- Published on
OpenAI GPT-5.5: 더 똑똑한 모델보다 중요한 것은 에이전트 업무 단위다
- Authors

- Name
- Kyunghyun Park
- @devkhpark
OpenAI · GPT-5.5 · Codex · Agentic Work
OpenAI의 GPT-5.5 발표를 읽을 때 숫자만 보면 결론이 너무 평범해진다. Terminal-Bench 2.0 82.7%, SWE-Bench Pro 58.6%, OSWorld-Verified 78.7%, BrowseComp 84.4%, 1M 컨텍스트, API 가격 같은 항목은 분명 중요하다. 하지만 이번 발표의 핵심은 "더 강한 모델" 자체보다 모델이 처리하는 작업 단위가 바뀌었다는 점에 있다.
GPT-5.5는 질문 하나에 답하는 모델로 소개되지 않는다. OpenAI는 이 모델이 코딩, 온라인 리서치, 데이터 분석, 문서와 스프레드시트 작성, 소프트웨어 조작, 여러 도구를 오가는 일을 더 오래 끌고 간다고 설명한다. 즉 GPT-5.5의 제품적 의미는 response quality가 아니라 계획하고, 도구를 쓰고, 검증하고, 다시 실행하는 에이전트 루프의 품질에서 읽어야 한다.

이 글은 OpenAI의 GPT-5.5 발표, 시스템 카드, Bio Bug Bounty, 그리고 Codex 엔터프라이즈 확장 관련 자료를 바탕으로 GPT-5.5가 개발자와 조직의 AI 도입 방식에 어떤 변화를 요구하는지 정리한다.
기준 시점: 이 글의 내용은 2026-04-25에 확인한 OpenAI 공식 발표와 공개 문서 기준이다. OpenAI는 2026-04-24 업데이트에서 GPT-5.5와 GPT-5.5 Pro가 API에서 사용 가능해졌다고 밝혔다. 실제 가격, 제공 범위, 안전 정책은 배포 환경에 따라 바뀔 수 있으므로 적용 전 공식 문서를 다시 확인해야 한다.
GPT-5.5의 메시지는 "더 긴 작업을 맡겨도 된다"에 가깝다
OpenAI는 GPT-5.5를 "our smartest and most intuitive to use model yet"이라고 부르지만, 더 중요한 문장은 그 다음에 나온다. GPT-5.5는 사용자가 하려는 일을 더 빨리 이해하고, 더 많은 작업을 스스로 carry하며, messy multi-part task를 받아 계획하고 도구를 쓰고 결과를 확인하며 계속 진행할 수 있다는 식으로 설명된다.
이 표현은 모델 발표에서 흔히 보던 "추론이 좋아졌다"와 다르다. 여기서 OpenAI가 팔고 싶은 것은 답변 품질이 아니라 위임 가능한 작업 범위다. 개발자가 세세한 단계 지시를 계속 넣지 않아도, 모델이 코드베이스를 읽고, 가설을 세우고, 수정하고, 테스트하고, 주변 영향까지 확인하는 쪽으로 제품 서사가 이동한다.
벤치마크도 이 방향을 뒷받침한다.
| 영역 | OpenAI가 강조한 GPT-5.5 수치 | 해석 |
|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 명령줄 기반 장기 작업, 계획, 반복, 도구 조율 능력 |
| SWE-Bench Pro | 58.6% | 실제 GitHub 이슈를 끝까지 해결하는 능력 |
| OSWorld-Verified | 78.7% | 실제 컴퓨터 환경을 조작하는 능력 |
| Tau2-bench Telecom | 98.0% | 복잡한 고객 지원 워크플로 수행 능력 |
| GeneBench | 25.0% | 다단계 과학 데이터 분석에서의 개선 |
| Graphwalks BFS 1M | 45.4% | 긴 컨텍스트에서 구조를 따라가는 능력 |
숫자의 절대값보다 중요한 건 평가 항목의 성격이다. 대부분이 단발성 질의응답보다 환경 안에서 무언가를 끝까지 수행하는 능력을 겨냥한다. GPT-5.5의 포지셔닝은 그래서 "더 좋은 챗봇"이 아니라 "더 오래 일하는 작업 실행자"에 가깝다.
코딩 성능의 실무적 의미: 패치 생성보다 실패 원인 추적
GPT-5.5의 코딩 성능을 볼 때 SWE-Bench Pro 58.6%나 Terminal-Bench 2.0 82.7%만 외우면 핵심을 놓친다. OpenAI가 반복해서 강조하는 차이는 코드 작성 자체보다 시스템의 모양을 이해하는 능력이다. 왜 실패했는지, 수정이 어디에 들어가야 하는지, 어떤 주변 코드가 영향을 받을지를 더 잘 본다는 주장이다.
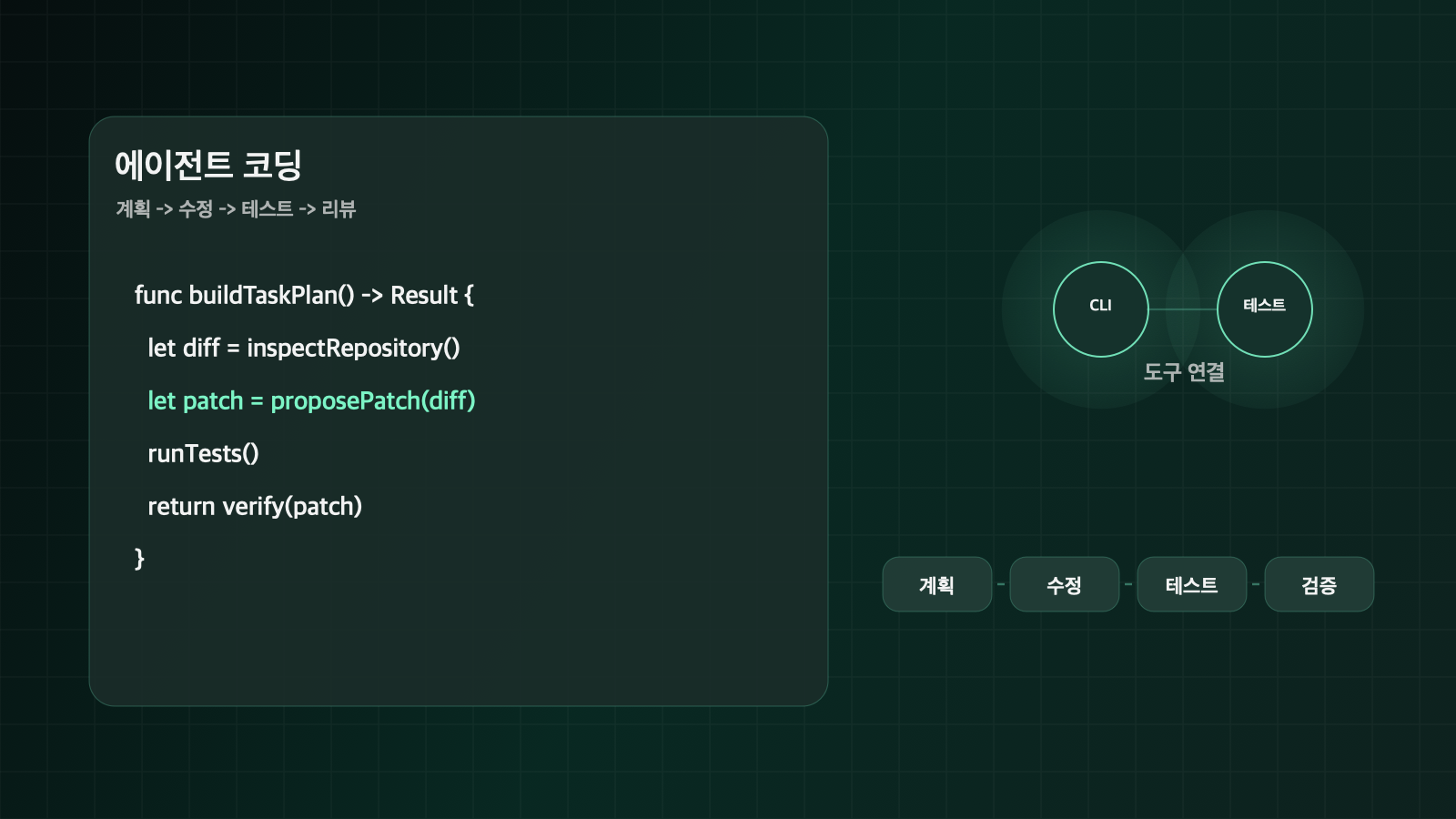
개발자 입장에서 이 차이는 꽤 크다. 많은 AI 코딩 도구가 이미 함수 하나, 컴포넌트 하나, 테스트 하나는 잘 만든다. 문제는 레포 전체에서 실패가 발생했을 때다. 실제 일은 보통 다음 순서로 흘러간다.
- 에러 메시지를 읽는다.
- 실패가 재현되는지 확인한다.
- 최근 변경과 주변 의존성을 본다.
- 가설을 세운다.
- 작은 패치를 만든다.
- 테스트와 빌드를 돌린다.
- 실패하면 다시 원인으로 돌아간다.
GPT-5.5가 의미 있으려면 이 루프를 끊지 않고 돌아야 한다. OpenAI가 말한 "fewer tokens", "fewer retries", "checking assumptions with tools", "carrying changes through the surrounding codebase"는 모두 같은 지점을 가리킨다. 모델이 똑똑해졌다는 말보다 중간에 멈추지 않는 능력이 더 중요하다.
다만 이건 개발자의 역할이 사라진다는 뜻이 아니다. 오히려 리뷰 기준은 더 까다로워진다. 패치가 그럴듯할수록 사람은 구현 디테일보다 작업 단위의 경계를 봐야 한다. 이 변경이 원인에 닿았는가? 테스트가 증상을 덮은 것인가, 원인을 검증한 것인가? 권한이 필요한 파일을 건드렸는가? GPT-5.5 시대의 좋은 개발자는 프롬프트를 잘 쓰는 사람이 아니라 AI가 만든 작업 루프를 감사할 수 있는 사람에 가깝다.
진짜 변화는 Codex와 붙을 때 나온다
GPT-5.5는 ChatGPT 안에서도 중요하지만, 더 큰 변화는 Codex와 결합될 때 나온다. OpenAI는 GPT-5.5가 Codex에서 구현, 리팩터링, 디버깅, 테스트, 검증까지 맡을 수 있다고 설명한다. 또 Codex가 macOS/Windows 앱, 컴퓨터 사용, 브라우징, 이미지 생성, 메모리, 플러그인, 스킬을 묶어 더 넓은 작업면으로 확장되고 있다는 흐름도 이미 발표했다.
이 조합은 모델 경쟁의 초점을 바꾼다. 앞으로 개발자 경험의 차이는 "어떤 모델이 더 높은 점수를 냈는가"만으로 결정되지 않는다. 다음 질문이 더 중요해진다.
- 모델이 레포와 문서를 얼마나 안정적으로 읽는가?
- 도구 호출 실패를 스스로 복구하는가?
- 긴 작업을 프로젝트, 스레드, 파일 단위로 보존하는가?
- 테스트와 빌드를 자연스럽게 워크플로 안에 넣는가?
- 사람이 승인해야 할 지점과 자동으로 돌려도 되는 지점을 구분하는가?
OpenAI가 Codex 엔터프라이즈 확장에서 4백만 주간 활성 사용자, Codex Labs, Accenture·PwC·Infosys 등 시스템 통합 파트너를 언급한 것도 같은 맥락이다. 모델이 강해졌다는 발표가 곧바로 조직 도입으로 이어지지 않는다. 기업은 워크숍, 통합, 권한, 변경관리, 파일/툴 연결, 반복 가능한 사용 사례가 필요하다. GPT-5.5는 그 운영 계층을 밀어 올리는 엔진이고, Codex는 그 엔진이 붙는 업무 표면이다.
추론 경제성: 더 비싼 모델이 항상 더 비싼 작업은 아니다
GPT-5.5의 가격은 가볍지 않다. OpenAI는 API 기준 gpt-5.5를 1M input token당 5달러, 1M output token당 30달러로 안내했고, gpt-5.5-pro는 1M input token당 30달러, output token당 180달러로 예고했다. 동시에 Batch/Flex는 표준 가격의 절반, Priority는 2.5배라고 설명한다.
표면적으로는 GPT-5.4보다 비싸다. 하지만 OpenAI는 GPT-5.5가 더 지능적이고 훨씬 token efficient하다고 주장한다. Codex에서는 더 적은 토큰과 더 적은 재시도로 더 나은 결과를 낸다는 식이다.
여기서 개발팀이 봐야 할 것은 단가가 아니라 완료된 작업당 비용이다. 에이전트 작업에서는 비용 항목이 토큰 몇 개로 끝나지 않는다.
- 실패한 시도와 재시도 비용
- 사람이 중간에 개입하는 시간
- 테스트를 돌리고 로그를 해석하는 반복 횟수
- 컨텍스트를 다시 설명하는 비용
- 잘못된 패치가 만든 후속 디버깅 비용
- 긴 작업을 중간에 잃어버려 다시 시작하는 비용
따라서 GPT-5.5 같은 모델은 모든 요청의 기본값으로 쓰기보다 실패 비용이 큰 작업에 먼저 배치하는 게 합리적이다. 예를 들어 대규모 리팩터링, flaky test 원인 추적, 긴 리서치 메모, 복잡한 데이터 분석, 보안 취약점 triage처럼 중간 실패가 비싼 작업이다. 반대로 짧은 요약, 단순 변환, 반복적인 템플릿 생성에는 더 작은 모델이나 캐시된 파이프라인이 낫다.
OpenAI가 추론 인프라 섹션에서 GB200/GB300 NVL72, load balancing, partitioning heuristics, token generation speed 20% 개선을 길게 설명한 것도 흥미롭다. 모델 발표 안에 인프라 최적화 이야기가 들어간다는 것은, 에이전트 시대에는 모델 품질과 serving economics가 분리되지 않는다는 뜻이다. 긴 작업을 많이 맡길수록 병목은 모델 IQ가 아니라 지연 시간, 처리량, 우선순위, 재시도 비용으로 이동한다.
1M 컨텍스트는 만능 기억이 아니라 설계 부담이다
GPT-5.5의 API 컨텍스트는 1M으로 안내됐다. Codex에서는 400K 컨텍스트 윈도우도 언급된다. 긴 컨텍스트는 분명 강력하다. Graphwalks나 MRCR 같은 긴 컨텍스트 평가에서 GPT-5.5가 GPT-5.4 대비 크게 좋아진 구간도 있다.
하지만 긴 컨텍스트를 "다 넣으면 된다"로 받아들이면 위험하다. 컨텍스트가 길어질수록 세 가지 문제가 생긴다.
첫째, 무엇이 중요한지 정렬하는 비용이 커진다. 레포 전체, 문서 전체, 로그 전체를 넣으면 모델은 많은 것을 볼 수 있지만, 사람이 원하는 판단 기준은 흐려질 수 있다.
둘째, 검증 가능한 근거와 잡음의 경계가 약해진다. 긴 문맥 안에는 오래된 문서, 실패한 실험, 임시 메모, 폐기된 정책이 섞인다. 에이전트가 오래 일할수록 이런 잡음을 사실처럼 다룰 가능성도 생긴다.
셋째, 비용과 지연 시간이 숨어 들어간다. 1M 컨텍스트는 가능성이지 기본값이 아니다. 실무에서는 컨텍스트 라우팅, 요약, 색인, 파일 선택, 메모리 갱신 정책이 함께 있어야 한다.
그래서 GPT-5.5를 잘 쓰는 팀은 "큰 컨텍스트 모델이 있으니 RAG가 필요 없다"고 말하지 않을 것이다. 반대로 더 정교한 컨텍스트 엔지니어링이 필요해진다. 긴 작업을 맡길수록 입력을 줄이는 기술보다 어떤 근거를 언제 보여줄지 결정하는 운영 기술이 중요하다.
안전과 배포: 강한 모델은 더 강한 권한 모델을 요구한다
OpenAI는 GPT-5.5를 "strongest set of safeguards to date"와 함께 출시한다고 설명했다. 시스템 카드에서는 전체 predeployment safety evaluation, Preparedness Framework, 고급 사이버보안과 생물학 능력에 대한 targeted red-teaming, 약 200개 early-access partner 피드백을 언급한다. Bio Bug Bounty에서는 GPT-5.5 in Codex Desktop을 대상으로 보편적 jailbreak를 찾는 챌린지를 열고, 다섯 개 bio safety question을 모두 통과시키는 universal jailbreak에 25,000달러 보상을 제시했다.

이 안전 서사는 단순한 PR 장식이 아니다. GPT-5.5 같은 모델이 실제로 코드를 수정하고, 도구를 호출하고, 컴퓨터를 조작하고, 연구 데이터와 문서를 다룬다면 안전은 모델 출력 필터만으로 해결되지 않는다. 배포 구조 자체가 바뀌어야 한다.
실무에서 필요한 체크리스트는 대략 이렇다.
- 기본은 읽기 권한으로 시작하고, 쓰기 권한은 작업 종류별로 분리한다.
- 파일 수정, 배포, 외부 전송, 결제, 이메일 발송 같은 행위는 별도 승인 경계를 둔다.
- 에이전트가 실행한 명령, 읽은 파일, 만든 패치, 실패한 테스트를 로그로 남긴다.
- 보안·개인정보·규제 영역은 모델 선택보다 데이터 경계와 감사 가능성을 먼저 설계한다.
- 자동화는 사람이 이해할 수 있는 작은 단위로 쪼개고, 실패 시 안전하게 멈추게 한다.
OpenAI가 사이버 영역에서 stricter classifiers, trusted access, verified defenders 같은 용어를 쓰는 것도 같은 이유다. 모델 능력이 올라갈수록 모든 사용자에게 같은 권한을 주는 방식은 오래가지 못한다. 앞으로 frontier model 배포는 "사용 가능/불가"의 이분법보다 누가, 어떤 신뢰 신호로, 어떤 작업을, 어떤 제한 안에서 실행하는가로 갈 가능성이 높다.
GPT-5.5 Pro는 더 강한 답변 엔진이 아니라 고비용 판단 엔진으로 봐야 한다
GPT-5.5 Pro는 같은 underlying model에 parallel test-time compute를 더 쓰는 설정으로 설명된다. OpenAI는 GPT-5.5 Pro가 더 어려운 질문과 높은 정확도 작업에 적합하다고 말하고, API 가격도 일반 GPT-5.5보다 훨씬 높게 잡았다.
이런 모델을 일반 질의의 기본값으로 두는 것은 비효율적이다. Pro 계열은 고비용 판단 엔진으로 배치하는 편이 맞다. 예를 들어 다음 같은 곳이다.
- 중요한 아키텍처 결정 전 최종 반대 검토
- 보안 취약점 triage의 false negative를 줄이는 검토
- 장문 계약서나 정책 문서의 충돌 지점 탐색
- 연구 가설과 데이터 분석 계획의 재검토
- 이미 작은 모델과 일반 GPT-5.5가 만든 결과의 second opinion
즉 GPT-5.5와 GPT-5.5 Pro의 관계는 단순한 good/better가 아니다. 제품 설계 관점에서는 worker model과 reviewer model의 역할 분리에 가깝다. 일반 GPT-5.5가 실행 루프를 맡고, Pro가 고위험 판단이나 최종 검토를 맡는 식의 계층화가 더 자연스럽다.
한국 개발팀이 바로 적용할 수 있는 운영 패턴
GPT-5.5를 도입한다고 해서 바로 생산성이 올라가지는 않는다. 모델보다 먼저 작업 설계가 필요하다. 작은 팀이라면 다음 순서로 시작하는 편이 좋다.
1. 에이전트에게 맡길 작업을 "완료 조건" 중심으로 정의한다
"이 코드 고쳐줘"보다 "이 테스트가 통과하고, 관련 문서가 업데이트되고, 변경 파일이 세 개 이하이며, 빌드가 통과하면 완료"처럼 쓰는 편이 낫다. GPT-5.5는 긴 작업을 더 잘 끌고 갈 수 있지만, 완료 조건이 흐리면 오래 헤맬 수도 있다.
2. 권한을 작업 종류별로 나눈다
리서치, 코드 읽기, 로컬 패치, 테스트 실행, 외부 배포는 서로 다른 권한이다. 모두 같은 에이전트 세션에 몰아넣지 말고, 위험한 단계는 사람 승인이나 별도 환경으로 분리해야 한다.
3. 비용을 프롬프트 단위가 아니라 결과 단위로 본다
단순히 input/output token 가격만 보면 큰 모델은 비싸 보인다. 하지만 고급 디버깅이나 리팩터링에서는 실패한 작은 모델 여러 번보다 큰 모델 한 번이 싸게 먹힐 수 있다. 반대로 단순 반복 작업에는 큰 모델이 낭비다.
4. 로그와 산출물을 남긴다
에이전트가 만든 계획, 실행한 명령, 실패한 테스트, 최종 패치를 저장해야 다음 작업의 컨텍스트가 된다. GPT-5.5는 긴 문맥을 다룰 수 있지만, 조직의 기억은 여전히 사람이 검토 가능한 형태로 남아야 한다.
5. 리뷰 기준을 바꾼다
코드 한 줄의 품질보다 작업 루프의 품질을 봐야 한다. 문제를 제대로 재현했는가? 원인에 닿았는가? 테스트가 충분한가? 주변 영향을 확인했는가? 보안 경계를 넘지 않았는가? 앞으로 AI 코드 리뷰는 점점 더 과정 리뷰가 된다.
결론: GPT-5.5의 본질은 모델 성능보다 업무 단위의 재정의다
GPT-5.5는 당연히 더 강한 모델이다. 코딩, 지식 작업, 과학 연구, 도구 사용, 긴 컨텍스트, 사이버보안 평가에서 여러 개선을 내세운다. 하지만 이번 발표를 단순히 "OpenAI가 새 SOTA를 냈다"로 요약하면 가장 중요한 변화를 놓친다.
핵심은 작업 단위다. GPT-5.5는 프롬프트 하나에 답하는 모델이 아니라, 레포를 읽고, 도구를 호출하고, 파일을 만들고, 테스트하고, 다시 고치는 장기 실행 에이전트 업무 모델로 포지셔닝된다. Codex는 그 실행면이고, 추론 인프라는 그 경제성의 기반이며, 시스템 카드와 bug bounty는 그 배포 조건을 설명한다.
그래서 개발자와 조직이 던져야 할 질문도 바뀐다.
이 모델이 얼마나 똑똑한가?
보다,
이 모델에게 어떤 작업을, 어떤 권한으로, 어떤 검증 루프 안에서 맡길 것인가?
가 더 중요하다. GPT-5.5의 실질적 가치는 그 질문에 답할 준비가 된 팀에서 더 크게 나타날 것이다.
참고 자료
- OpenAI, Introducing GPT-5.5, 2026-04-23.
- OpenAI, GPT-5.5 System Card, 2026-04-23.
- OpenAI, GPT-5.5 Bio Bug Bounty, 2026-04-23.
- OpenAI, Scaling Codex to enterprises worldwide, 2026-04-21.
- OpenAI Academy, Top 10 uses for Codex at work, 2026-04-23.