- Published on
DeepSeek DeepEP: MoE 추론 병목은 모델이 아니라 통신 런타임이다
- Authors

- Name
- Kyunghyun Park
- @devkhpark
DeepSeek · DeepEP · MoE Runtime · RDMA/NVLink
DeepSeek의 DeepEP를 그냥 "또 하나의 CUDA 라이브러리"로 보면 핵심을 놓친다. 지금 중요한 변화는 모델 아키텍처가 아니라 MoE 모델을 실제 클러스터에서 먹여 살리는 통신 런타임이 독립적인 경쟁 축으로 올라왔다는 점이다.
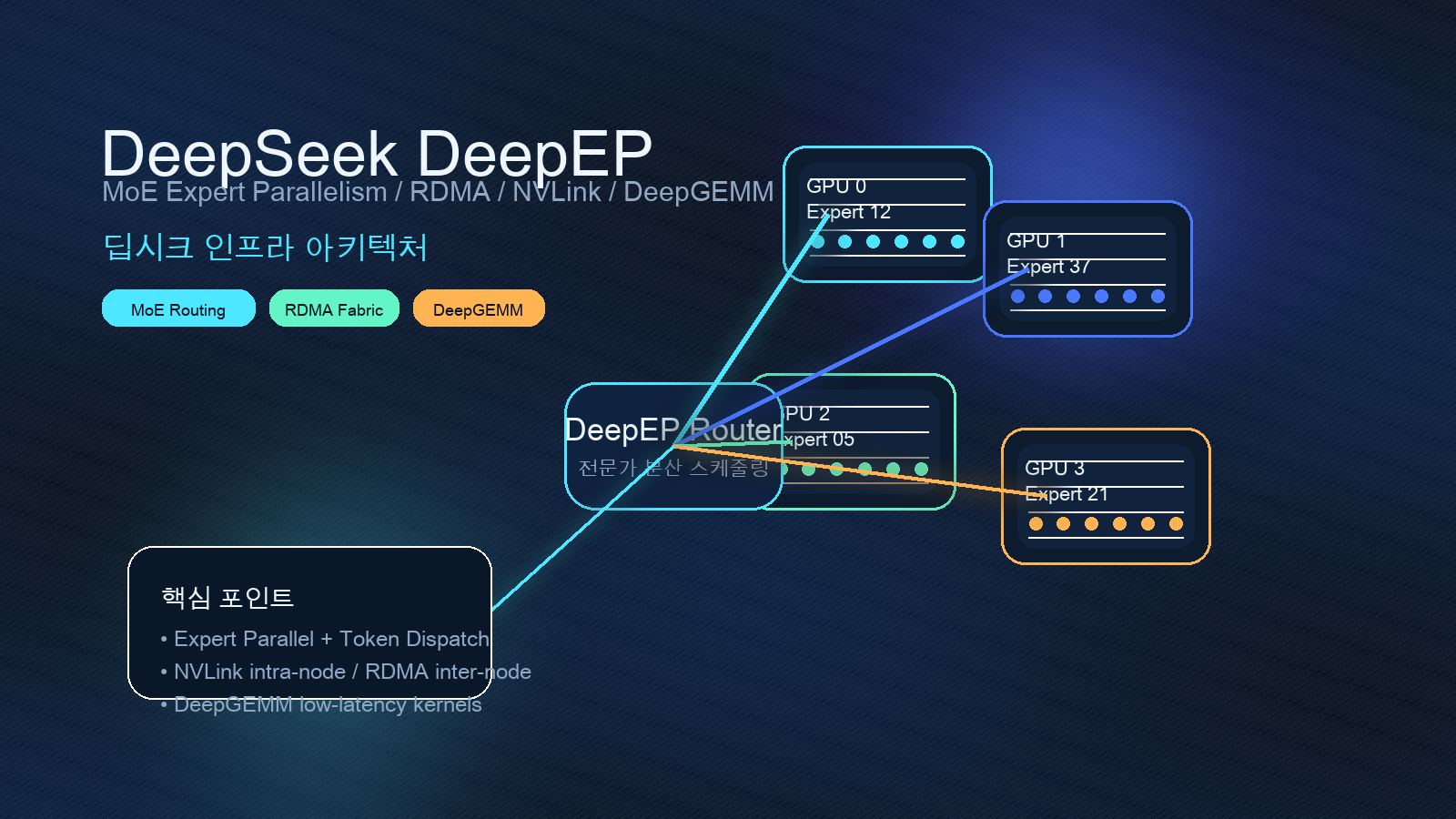
DeepEP README는 이 프로젝트를 Mixture-of-Experts(MoE)와 expert parallelism(EP)에 맞춘 통신 라이브러리라고 정의한다. 역할은 MoE dispatch와 combine으로도 불리는 all-to-all GPU 커널을 고처리량·저지연으로 제공하는 것이다. 여기에 FP8 같은 저정밀 통신, NVLink 도메인과 RDMA 도메인 사이의 비대칭 bandwidth forwarding, latency-sensitive decoding용 pure RDMA 커널까지 들어간다.
이 글은 2026-04-26 기준 GitHub Trending에 다시 올라온 DeepEP와, 공식 DeepGEMM·DeepSeek-V3·DeepSeek-R1 자료를 함께 읽고 정리한 것이다. 결론부터 말하면 DeepSeek의 최근 오픈 인프라 흐름은 "더 큰 모델"보다 sparse MoE를 실제 서비스 지연시간 안에서 돌리는 실행 계층에 더 가깝다.
기준 시점: 이 글은 2026-04-26에 확인한 DeepSeek 공식 GitHub README와 GitHub repository metadata 기준이다. DeepEP/DeepGEMM은 커널·하드웨어 의존성이 큰 프로젝트라 수치와 요구사항은 이후 커밋에서 바뀔 수 있다.
왜 DeepEP가 지금 SEO 키워드로도, 기술 신호로도 중요한가
검색 의도부터 보면 DeepEP를 찾는 사람은 대체로 세 부류다.
- DeepSeek-V3/R1 계열 MoE를 실제로 돌리려는 인프라 엔지니어
- MoE inference에서 왜 all-to-all 통신이 병목이 되는지 이해하려는 개발자
- FP8, RDMA, NVLink, expert parallelism 같은 키워드가 추론 비용과 어떤 관계인지 알고 싶은 빌더
즉 이 주제는 단순한 오픈소스 소개가 아니다. 오픈 모델을 내려받는 단계와, 그것을 싸고 빠르게 운영하는 단계 사이의 간극을 다룬다.
DeepSeek-V3 README는 V3를 671B total parameters, token당 37B activated parameters를 쓰는 MoE 모델로 소개한다. DeepSeek-R1도 V3 기반 아키텍처를 사용하며 R1/R1-Zero 모델이 671B total, 37B activated, 128K context length를 갖는다고 공개한다. 이 구조의 장점은 분명하다. 모든 파라미터를 매번 쓰지 않고 일부 전문가만 활성화하므로, 모델 규모 대비 계산량을 줄일 수 있다.
하지만 sparse activation은 공짜가 아니다. 토큰을 어떤 expert로 보낼지 결정하고, GPU와 노드 사이로 데이터를 흩뿌린 뒤, 다시 결과를 모아야 한다. 이 dispatch/combine 구간이 느리면 MoE의 이론적 효율은 서비스 지연시간에서 사라진다.
MoE의 진짜 병목은 행렬곱만이 아니다
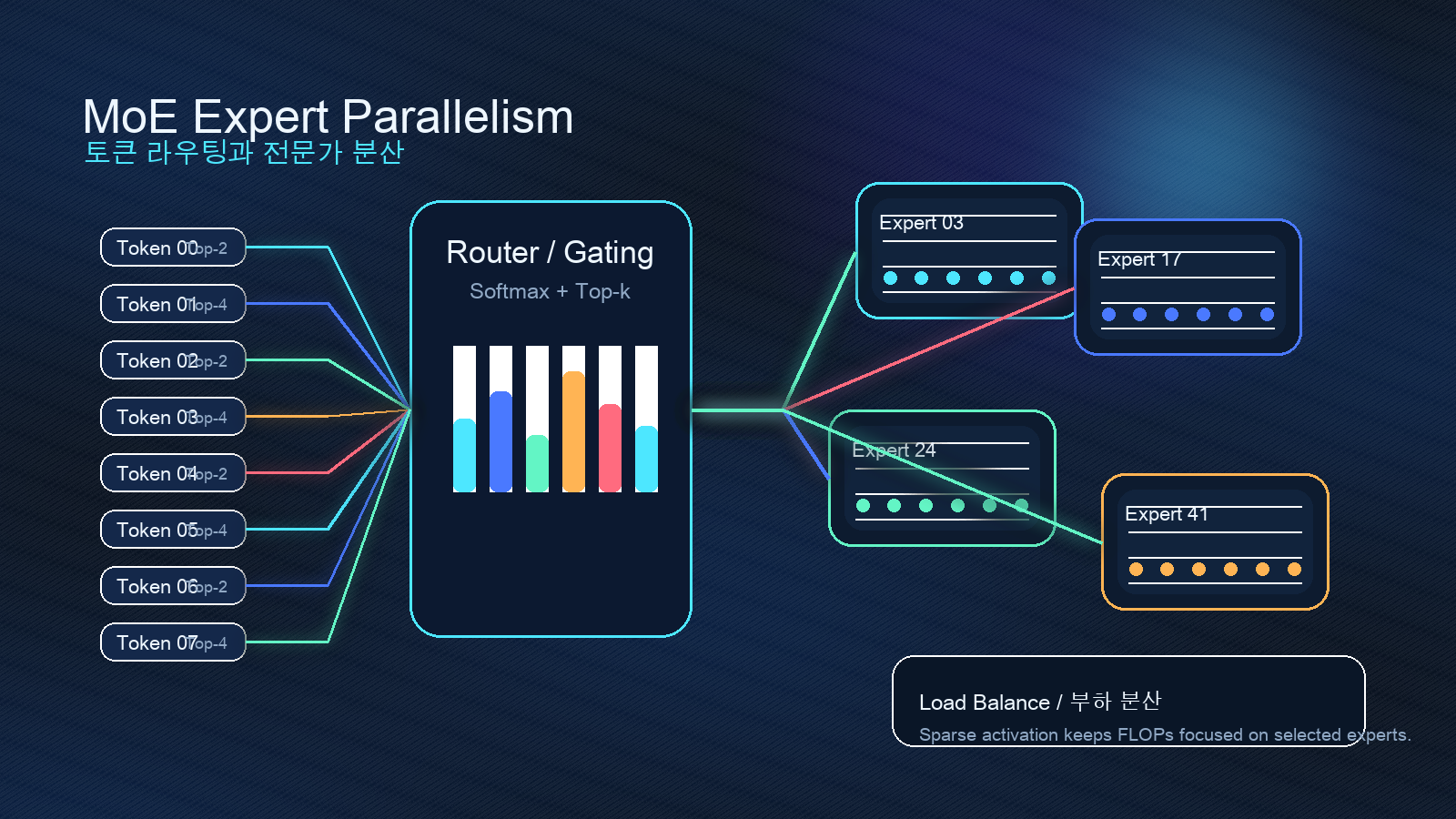
일반적인 LLM 최적화 이야기는 GEMM, attention, KV cache, quantization에 집중한다. 물론 중요하다. 하지만 MoE에서는 병목이 하나 더 생긴다. 선택된 전문가가 어디에 있느냐다.
MoE runtime은 대략 이런 순서를 갖는다.
- 입력 토큰마다 router/gating이 top-k expert를 고른다.
- 같은 expert로 갈 토큰을 묶고, expert가 올라간 GPU 또는 노드로 보낸다.
- 각 expert가 계산한다.
- 결과를 다시 원래 토큰 순서와 배치로 combine한다.
여기서 expert가 한 노드 안에 있으면 NVLink가 중요해지고, 여러 노드로 퍼지면 RDMA 네트워크가 중요해진다. DeepEP README가 normal kernels에서 NVLink와 RDMA forwarding을 따로 설명하고, low-latency kernels에서 pure RDMA를 별도로 다루는 이유가 여기에 있다.
공식 README에 공개된 성능 표도 같은 방향을 말한다. DeepEP는 H800과 CX7 InfiniBand 400 Gb/s 환경에서 DeepSeek-V3/R1 pretraining setting을 기준으로 normal kernels를 테스트했고, intranode에서는 NVLink bandwidth, internode에서는 RDMA bandwidth를 병목 기준으로 제시한다. 또한 decoding에 가까운 128-token batch production setting에서는 dispatch와 combine latency를 마이크로초 단위로 제시한다.
이 수치의 디테일보다 중요한 건 측정 축이다. DeepEP가 보여주는 것은 "모델이 더 똑똑하다"가 아니라 MoE의 성능을 말하려면 이제 통신 커널, 네트워크 fabric, overlap 전략을 같이 봐야 한다는 사실이다.
DeepEP는 DeepSeek-V3 논문의 구현 부록이 아니라 운영 계층이다
DeepEP README는 DeepSeek-V3 논문의 group-limited gating 알고리즘에 맞추기 위해, NVLink domain에서 RDMA domain으로 데이터를 forwarding하는 식의 비대칭 bandwidth forwarding 커널을 제공한다고 설명한다. 동시에 README는 라이브러리 구현이 논문과 약간 다를 수 있다고 선을 긋는다.
이 문장이 꽤 중요하다. 논문은 알고리즘의 방향을 설명하지만, 실제 런타임은 하드웨어 topology와 네트워크 상황에 맞춰 달라진다. 한국 개발자나 AI 스타트업이 여기서 읽어야 할 포인트는 다음과 같다.
- MoE serving은 모델 파일을 올리는 문제만이 아니다.
- expert placement, token routing, batch shape, GPU interconnect가 성능을 바꾼다.
- 논문 수치와 실제 production latency 사이에는 런타임 구현이라는 큰 층이 있다.
특히 DeepEP는 latency-sensitive inference decoding을 위해 pure RDMA low-latency kernels를 제공한다고 명시한다. 대화형 챗봇이나 agent loop에서는 prefill보다 decoding 지연시간이 사용자 경험을 더 크게 좌우할 때가 많다. 그래서 DeepEP는 training/perf enthusiast용 장난감이 아니라 실제 응답 지연시간을 줄이려는 serving 인프라 조각으로 봐야 한다.
RDMA와 NVLink가 "하드웨어 스펙"이 아니라 제품 품질이 되는 순간
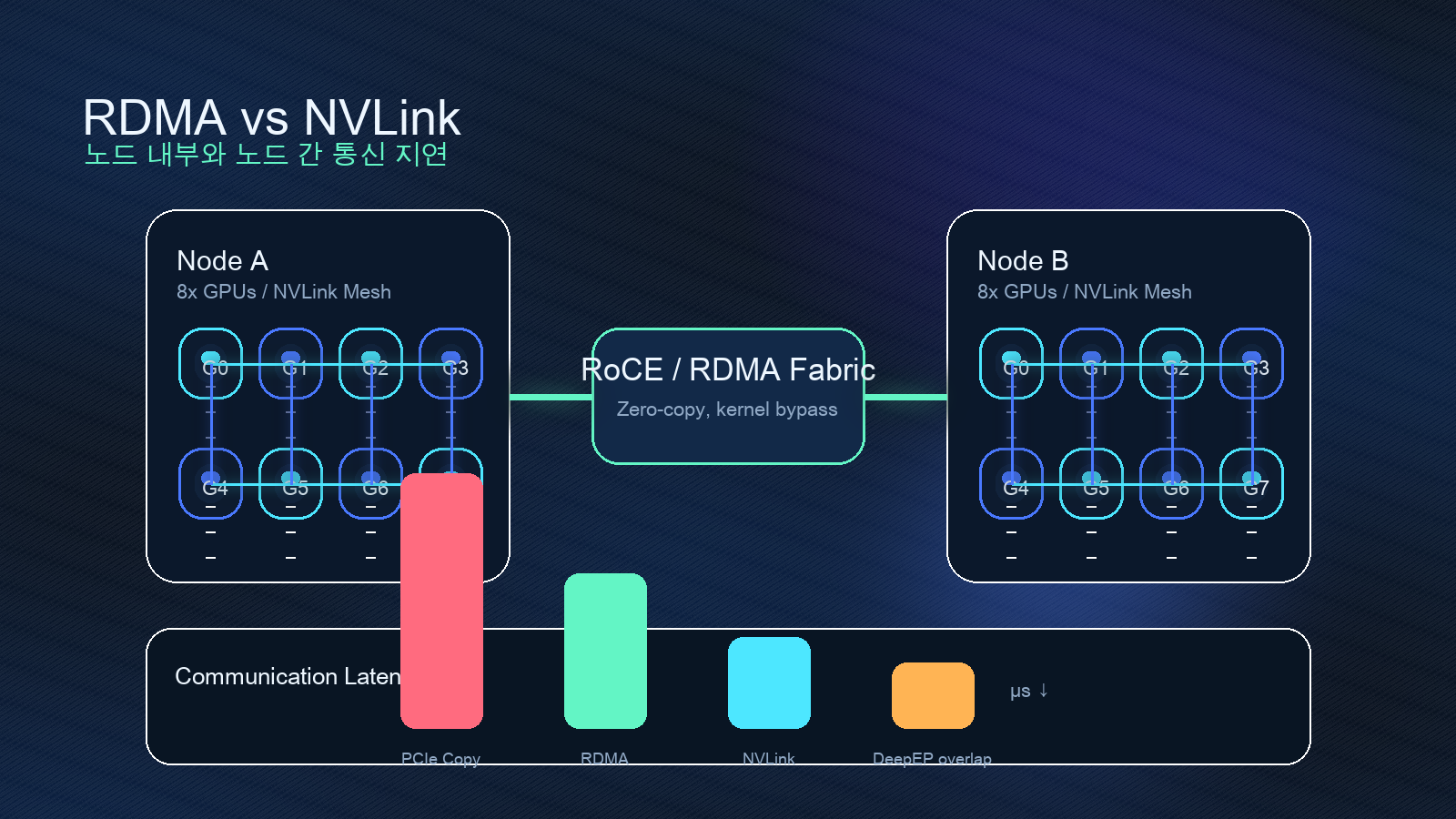
AI 제품을 만드는 입장에서는 하드웨어 세부사항을 추상화하고 싶다. 하지만 agent나 long-context 서비스처럼 호출이 길어지고 반복이 많아지면, 추론 비용과 지연시간은 곧 제품 기능이 된다.
DeepEP의 요구사항은 꽤 직접적이다. README는 Ampere(SM80), Hopper(SM90) 또는 SM90 PTX ISA 지원 아키텍처, CUDA, PyTorch, NVLink, RDMA network, NVSHMEM 의존성을 언급한다. 즉 "pip install 하고 끝"나는 라이브러리가 아니라 클러스터 네트워크와 빌드 환경까지 포함한 프로젝트다.
이 점은 작은 팀에게 두 가지 의미를 준다.
1) MoE 오픈 모델은 로컬 실행성과 클러스터 실행성을 나눠 봐야 한다
DeepSeek-R1 distill 계열처럼 작은 dense 모델을 로컬에서 돌리는 문제와, 671B급 sparse MoE를 낮은 지연시간으로 운영하는 문제는 완전히 다르다. 전자는 quantization과 메모리 절약이 핵심이고, 후자는 expert parallel communication이 핵심이 된다.
2) 추론 비용 최적화는 모델 선택 이후의 일이 아니라 모델 선택 기준이다
어떤 모델을 고를 때 benchmark 점수만 보면 부족하다. 운영자는 다음을 같이 물어야 한다.
- expert parallelism을 지원하는 serving stack이 있는가?
- low-latency decoding에서 네트워크 병목을 감당할 수 있는가?
- FP8 dispatch/combine 같은 저정밀 통신 경로가 성숙했는가?
- NVLink와 RDMA topology를 실제 배포 환경에서 맞출 수 있는가?
이 질문에 답하지 못하면, 좋은 모델을 골라도 제품에서는 느리고 비싸게 느껴질 수 있다.
DeepGEMM과 같이 보면 DeepSeek의 방향이 더 선명해진다
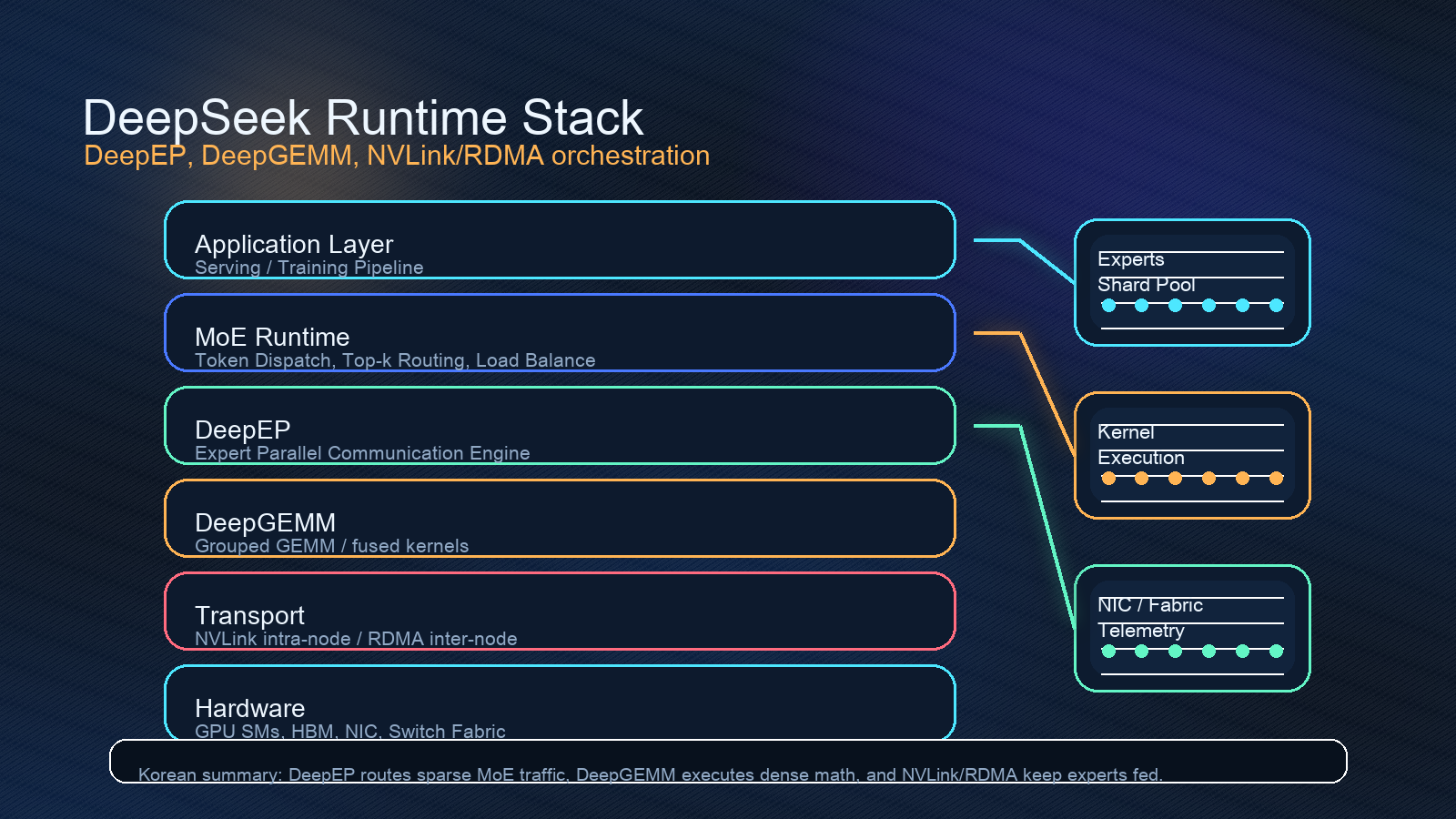
DeepEP만 보면 통신 라이브러리 하나로 보인다. 하지만 DeepGEMM과 같이 보면 그림이 커진다.
DeepGEMM README는 이 프로젝트를 modern LLM의 핵심 연산을 모은 high-performance tensor core kernel library라고 설명한다. FP8, FP4, BF16 GEMM뿐 아니라 fused MoE with overlapped communication, Mega MoE, MQA scoring, HyperConnection 등을 언급한다. 특히 2026-04-16 뉴스에는 Mega MoE, FP8xFP4 GEMM, FP4 Indexer, PDL, faster JIT compilation이 추가됐다고 적혀 있다.
이 조합은 꽤 명확하다.
| 층위 | DeepSeek 오픈 인프라가 다루는 문제 | 실무 의미 |
|---|---|---|
| 모델 | DeepSeek-V3/R1의 sparse MoE 구조 | 큰 총 파라미터, 낮은 token당 활성 파라미터 |
| 통신 | DeepEP의 dispatch/combine, NVLink/RDMA 경로 | expert를 먹여 살리는 데이터 이동 최적화 |
| 계산 | DeepGEMM의 FP8/FP4/BF16 GEMM과 fused MoE 커널 | expert 내부 계산과 low-level kernel 효율 |
| 서비스 | decoding latency, batch shape, topology | 실제 사용자 응답속도와 비용 |
즉 DeepSeek은 모델 하나만 공개하는 게 아니라, 오픈 모델 시대에 필요한 runtime substrate를 조금씩 밖으로 꺼내고 있다. 이것이 DeepEP가 GitHub Trending에서 의미 있는 이유다.
실무 해석: 한국 개발자와 빌더는 무엇을 해야 하나
DeepEP를 당장 production에 넣을 팀은 많지 않을 수 있다. 요구 하드웨어가 무겁고, NVSHMEM·CUDA·클러스터 설정도 만만하지 않다. 하지만 이 프로젝트가 주는 전략적 메시지는 넓게 적용된다.
1) "오픈 모델"과 "오픈 런타임"을 분리해서 평가하라
모델 가중치가 공개됐다고 해서 운영이 쉬워지는 것은 아니다. 특히 MoE는 routing과 communication이 성능의 큰 부분을 차지한다. 모델 카드만 읽지 말고, serving framework, kernel library, communication backend까지 같이 봐야 한다.
2) agent 서비스는 latency tail을 더 민감하게 본다
agent는 단일 답변보다 여러 tool call, 여러 reasoning step, 긴 context를 반복한다. 평균 latency보다 tail latency와 비용 누적이 중요해진다. DeepEP 같은 low-latency dispatch/combine 연구는 agent runtime 경제성과 직접 연결된다.
3) 벤치마크보다 topology가 먼저인 경우가 생긴다
같은 모델이라도 NVLink가 있는지, RDMA가 안정적인지, expert를 어떻게 shard했는지에 따라 체감 성능이 바뀐다. 따라서 GPU 서버 견적을 낼 때도 "몇 장짜리 GPU인가"보다 노드 내부/노드 간 연결이 어떤 MoE traffic을 버틸 수 있는가를 물어야 한다.
4) 작은 팀은 전체 스택을 직접 만들기보다 신호를 읽어야 한다
대부분의 팀은 DeepEP를 직접 튜닝하기보다 vLLM, TensorRT-LLM, SGLang, vendor serving, managed inference를 쓸 가능성이 높다. 그래도 DeepEP를 읽는 가치는 있다. 이 프로젝트는 앞으로 managed inference 가격표 뒤에서 어떤 병목이 비용을 결정하는지 보여 주기 때문이다.
DeepEP를 한 문장으로 보면: MoE의 비용 절감 약속을 현실로 만드는 통신 계층
MoE는 "큰 모델을 매번 전부 계산하지 않는다"는 매력적인 약속을 한다. 하지만 그 약속은 expert를 빠르게 고르고, 보내고, 계산하고, 다시 모을 수 있을 때만 성립한다. DeepEP는 바로 이 중간 구간을 겨냥한다.
그래서 DeepEP의 핵심은 CUDA 커널 이름이나 성능표의 숫자 하나가 아니다. 더 큰 신호는 이것이다.
최신 AI 경쟁은 모델 가중치에서 끝나지 않는다. MoE, long context, agentic loop가 확산될수록 승부는 모델을 둘러싼 통신·커널·네트워크·serving runtime의 설계 품질로 내려간다.
짧은 결론
DeepSeek DeepEP는 MoE inference의 현실적인 병목을 전면에 꺼낸 프로젝트다. DeepSeek-V3/R1 같은 sparse MoE 모델이 보여준 규모의 이점을 실제 서비스에서 살리려면, expert parallel communication과 low-level kernel stack이 같이 성숙해야 한다. 한국 개발자와 빌더에게 중요한 takeaway는 분명하다. 이제 AI 인프라를 볼 때 모델 이름만 보지 말고, 그 모델을 지연시간과 비용 안에서 굴리는 런타임 계층까지 같이 봐야 한다.