- Published on
Gemini API Webhooks: AI 작업을 폴링 루프에서 이벤트 운영으로 바꾸는 업데이트
- Authors

- Name
- Kyunghyun Park
- @devkhpark
Gemini API · Webhooks · Long-running AI Jobs · Agent Runtime
Google이 2026년 5월 4일 공개한 Gemini API Webhooks는 겉으로 보면 작은 개발자 편의 기능처럼 보인다. 하지만 실제 의미는 꽤 크다. 장시간 걸리는 AI 작업을 GET /operations로 계속 확인하던 방식에서, 작업이 끝나는 순간 서버로 HTTP POST 이벤트를 밀어주는 방식으로 넘어가기 때문이다.

이 변화는 단순히 polling 코드를 줄이는 정도가 아니다. Batch API로 수천 개 프롬프트를 처리하거나, Interactions API로 agent 상태를 이어가거나, Veo로 영상을 생성하는 팀이라면 이제 AI 작업을 요청-응답 API가 아니라 비동기 작업 시스템으로 설계해야 한다. 실무 포인트는 명확하다. AI 제품의 병목은 모델 품질만이 아니라, 긴 작업을 어떻게 접수하고, 기다리고, 실패를 감지하고, 다시 라우팅하느냐로 이동하고 있다.
기준 시점: 이 글은 2026-05-06에 확인한 Google 공식 블로그와 Gemini API 문서 기준이다. Webhooks, Batch API, Interactions, Veo 관련 세부 동작과 베타 정책은 바뀔 수 있으니 실제 구현 전 공식 문서를 다시 확인하는 편이 좋다.
핵심은 “콜백 URL 하나”가 아니라 폴링 비용의 제거다
Google 공식 블로그는 Webhooks를 “push-based notification system”으로 설명한다. 기존에는 Batch API나 영상 생성처럼 몇 분에서 몇 시간까지 걸릴 수 있는 작업을 시작한 뒤, 클라이언트가 주기적으로 GET operations를 호출하며 상태를 확인해야 했다. 이제는 작업 완료 이벤트가 발생하면 Gemini API가 개발자 서버의 listener URL로 HTTP POST payload를 보낸다.
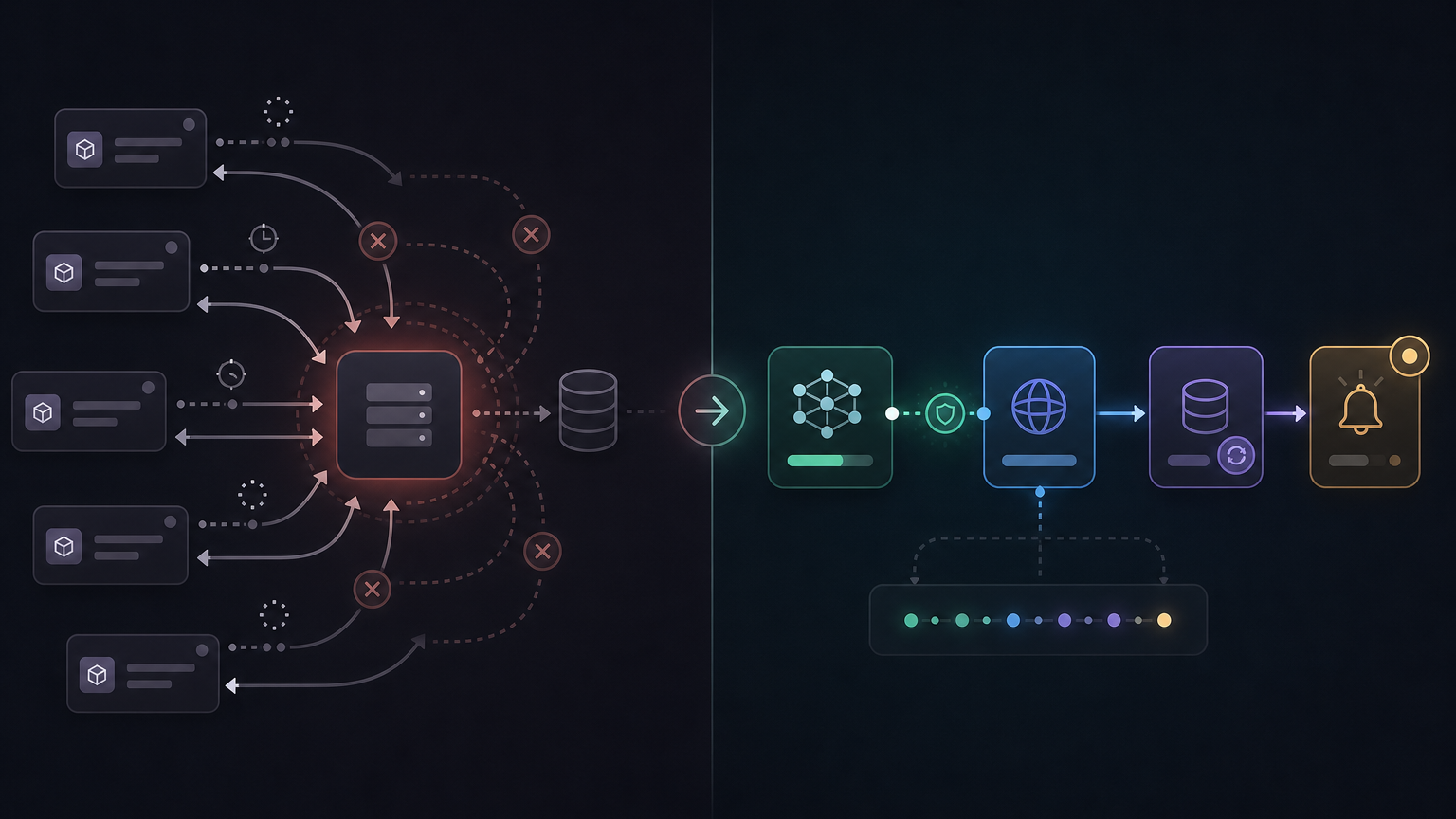
폴링은 처음에는 별문제 없어 보인다. 하지만 AI 작업이 길어지고 많아질수록 운영 비용이 커진다.
- 완료되지 않은 작업을 계속 확인하느라 불필요한 API 호출이 늘어난다.
- 상태 확인 주기를 길게 잡으면 사용자가 늦게 알림을 받는다.
- 주기를 짧게 잡으면 비용과 rate limit 부담이 커진다.
- worker, cron, queue, retry 로직이 모델 호출 주변에 덕지덕지 붙는다.
- 장애가 났을 때 “작업 자체가 실패한 것인지, 상태 확인 루프가 멈춘 것인지” 구분하기 어려워진다.
Webhooks는 이 문제를 뒤집는다. 클라이언트가 “끝났니?”라고 계속 묻는 대신, Gemini API가 “끝났다”는 이벤트를 보내게 만드는 것이다. 이 차이는 API 코드 몇 줄보다 운영 모델의 변화에 가깝다.
왜 지금 중요한가: Gemini가 더 오래 걸리는 작업 표면으로 확장되고 있다
이번 업데이트가 의미 있는 이유는 Gemini API가 점점 장시간 작업을 많이 품고 있기 때문이다. Google 문서는 Webhooks 적용 대상을 Batch jobs, Interactions, video generation으로 명시한다. 각각의 성격은 다르지만 공통점이 있다. 모두 단발성 채팅 응답보다 오래 걸리고, 완료 시점이 제품 흐름에 중요하다.
1) Batch API: 대량 프롬프트 처리의 완료 이벤트
Batch API는 수천 개 요청을 한 번에 처리하는 데 적합하다. 평가셋 실행, 데이터 라벨링, 콘텐츠 변환, 로그 분석, 대량 요약 같은 작업이 여기에 들어간다. 기존 방식에서는 batch job을 만든 뒤 주기적으로 상태를 조회해야 했다. Webhooks를 붙이면 batch.succeeded, batch.failed 같은 이벤트를 구독하고, 완료 즉시 후속 파이프라인을 실행할 수 있다.
실무적으로는 이게 꽤 크다. 예를 들어 밤새 고객 문의 50만 건을 분류하는 작업을 돌린다고 하자. 완료 여부를 확인하는 별도 scheduler가 아니라 webhook callback이 바로 결과 저장, BI 갱신, Slack 알림, 실패 재처리를 트리거할 수 있다. AI batch job이 데이터 파이프라인의 한 단계로 들어오는 셈이다.
2) Interactions API: agent 상태와 장시간 태스크
Interactions API 문서는 이 API를 generateContent의 개선된 대안으로 설명하며, 상태 관리, 도구 오케스트레이션, 장시간 작업을 단순화한다고 말한다. 즉 Gemini의 agent 표면은 점점 “한 번 물어보고 답 받는 함수”가 아니라, 상태를 가진 상호작용 객체와 작업 흐름으로 가고 있다.
이런 구조에서는 완료 이벤트가 중요하다. 사용자는 agent에게 조사, 분석, 파일 처리, 도구 실행을 맡긴다. 제품 입장에서는 작업이 끝났을 때 UI를 갱신하거나, 다음 agent step을 이어가거나, 사람이 승인해야 할 지점을 알려야 한다. Webhooks는 이 흐름을 polling 화면이 아니라 event-driven workflow로 바꾸는 기본 부품이다.
3) Veo 영상 생성: 긴 생성 작업의 운영 계약
Veo 3.1 문서는 영상 생성이 계산량이 큰 작업이며, 요청을 보내면 long-running job이 시작되고 operation 객체가 반환된다고 설명한다. 고해상도 영상은 지연시간이 더 길어질 수 있다. 이런 작업은 채팅 응답처럼 브라우저 탭을 붙잡고 기다리기에 적합하지 않다.
영상 생성 제품을 만든다면 사용자는 “생성이 끝나면 알려줘”를 기대한다. 서버는 업로드, 과금, 검수, 썸네일 생성, 알림을 이어 붙여야 한다. Webhooks가 있으면 영상 생성 완료를 이벤트로 받아 후속 처리를 자연스럽게 연결할 수 있다.
Static webhook과 Dynamic webhook의 차이를 제품 설계 관점에서 봐야 한다
Gemini API 문서는 Webhooks를 두 가지 방식으로 나눈다.
| 방식 | 위치 | 적합한 용도 | 제품 설계 관점 |
|---|---|---|---|
| Static webhooks | 프로젝트 레벨 | 전역 알림, 공통 데이터 동기화, Slack/DB 통합 | 조직 단위 운영 이벤트를 중앙에서 받기 좋음 |
| Dynamic webhooks | 요청 레벨 | 특정 job을 전용 endpoint로 라우팅 | tenant, workflow, 사용자 요청별 후속 처리를 나누기 좋음 |
Static webhook은 “이 프로젝트의 batch 성공/실패는 모두 이 endpoint로 보내라”에 가깝다. 운영팀이 이벤트를 중앙에서 수집하고 모니터링하기 좋다. 반면 dynamic webhook은 특정 요청에 webhook URL을 같이 넘겨서 job마다 다른 callback을 지정할 수 있다. 예를 들어 고객 A의 대량 분석 작업은 A 전용 queue로, 고객 B의 영상 생성 작업은 B의 media pipeline으로 보내는 식이다.
이 구분은 사소하지 않다. AI 제품이 멀티테넌트 SaaS라면 dynamic webhook은 라우팅 자유도를 준다. 반대로 규정 준수와 감사가 중요한 조직이라면 static webhook으로 이벤트를 중앙 수집한 뒤 내부 workflow engine이 분기하는 편이 더 안전할 수 있다.
보안 포인트: Webhook은 편하지만 반드시 검증 가능한 이벤트여야 한다

Webhook은 편하지만, 잘못 설계하면 외부에서 임의 callback을 보내는 공격 표면이 된다. Google 문서가 signing secret과 서명 검증을 강조하는 이유가 여기에 있다. Static webhook을 만들 때 API는 signing secret을 한 번만 반환하므로 안전하게 저장해야 한다. 잃어버리면 rotate해야 한다. Google 블로그도 HMAC 기반 project-level webhook과 JWKS 기반 request-level override를 언급한다.
실무 체크리스트는 이렇다.
- 서명 검증을 callback handler의 첫 줄에 둔다. 이벤트 payload를 신뢰하기 전에 HMAC/JWKS 검증부터 해야 한다.
- 중복 이벤트를 전제로 idempotent하게 만든다. Google 블로그는 at-least-once delivery와 retry를 언급한다. 같은 이벤트가 두 번 와도 결과가 망가지지 않게 job id 기준으로 처리해야 한다.
- callback URL을 공개 API처럼 방치하지 않는다. endpoint별 rate limit, allowlist, WAF, observability를 붙이는 편이 좋다.
- job 상태의 최종 진실은 서버 저장소에 남긴다. webhook은 trigger이고, 제품의 상태 전이는 내부 DB/queue에서 관리해야 한다.
- secret rotation 절차를 미리 둔다. signing secret을 잃어버렸을 때가 아니라, 정기 rotation과 사고 대응 절차를 먼저 만들어야 한다.
여기서 중요한 건 Webhooks를 “편의 기능”으로 보지 않는 것이다. AI 작업 완료 이벤트는 곧 고객 데이터 처리, 과금, 알림, 후속 자동화로 이어질 수 있다. 따라서 webhook handler는 단순 route handler가 아니라 운영 경계다.
좋은 구조는 “모델 호출”보다 “작업 수명주기”를 먼저 설계한다
AI 앱을 만들 때 흔한 실수는 모델 호출 코드를 중심에 두는 것이다. 하지만 장시간 작업이 많아지면 중심은 모델 호출이 아니라 job lifecycle이 된다.

권장 구조는 대략 이렇다.
- 사용자가 작업을 요청한다.
- 서버가 내부 job record를 만든다. 상태는
queued또는submitted로 시작한다. - Gemini Batch / Interactions / Veo 작업을 시작하고 operation id를 저장한다.
- callback URL은 static 또는 dynamic webhook 정책에 맞춰 지정한다.
- webhook을 받으면 서명을 검증한다.
- 이벤트의 operation id로 내부 job을 찾는다.
- 같은 이벤트가 이미 처리됐는지 확인한다.
- 결과 조회 또는 결과 저장을 수행한다.
- DB 상태를
succeeded,failed,needs_review등으로 전이한다. - 사용자 알림, downstream queue, BI 업데이트, human review를 트리거한다.
이 구조에서는 Gemini API가 모든 상태를 대신 관리해주는 것이 아니다. Gemini는 장시간 AI 작업의 완료 이벤트를 보내주고, 제품은 그 이벤트를 자신만의 업무 상태로 변환한다. 이 분리감이 중요하다.
한국 개발팀에게 실전적으로 중요한 네 가지 질문
1) 폴링을 완전히 없앨 것인가, 보조 fallback으로 남길 것인가
Webhook은 push 기반이지만, 운영 환경에서는 callback 수신 실패, 네트워크 장애, 배포 중단 같은 일이 생길 수 있다. 따라서 핵심 작업에는 낮은 빈도의 reconciliation polling을 fallback으로 남기는 편이 안전하다. 다만 주 경로는 webhook이어야 한다. 폴링은 “항상 돌리는 메인 루프”가 아니라 “이상 상태를 복구하는 안전망”이 되는 것이 맞다.
2) 이벤트를 사용자에게 바로 보여줄 것인가, 내부 queue에 넣을 것인가
작은 서비스라면 webhook handler가 곧바로 DB를 갱신하고 사용자에게 알림을 보낼 수 있다. 하지만 멀티테넌트 SaaS나 대량 작업에서는 handler가 이벤트를 검증한 뒤 내부 queue에 넣고 빠르게 2xx를 반환하는 편이 낫다. callback endpoint는 짧고 안정적이어야 한다. 오래 걸리는 후속 처리는 worker가 담당해야 한다.
3) job id와 operation id를 어떻게 매핑할 것인가
AI 작업은 외부 operation id와 내부 business job id를 동시에 가진다. 둘을 느슨하게 관리하면 장애 분석이 어려워진다. 내부 job record에는 provider, model, operation id, user/tenant id, requested_at, webhook_received_at, final_state, retry_count, source event id를 남기는 편이 좋다. 나중에 비용·지연시간·품질 문제를 추적할 때 이 메타데이터가 생명줄이 된다.
4) 실패 이벤트를 제품 UX에 어떻게 드러낼 것인가
batch.failed나 영상 생성 실패는 단순 로그가 아니다. 사용자는 재시도, 입력 수정, 환불, human review 중 하나를 기대한다. Webhooks가 들어오면 실패를 조용히 삼키지 말고, 제품 UX에서 실패 상태와 다음 행동을 명확하게 보여줘야 한다.
SEO 키워드보다 중요한 실제 검색 의도: “Gemini Webhooks를 왜 써야 하나?”
이 주제를 검색하는 개발자는 보통 세 가지 의도를 가진다.
- Gemini API에서 long-running operation을 어떻게 처리할지 알고 싶다.
- Batch API나 Veo 작업 완료를 polling 없이 받는 방법을 찾고 있다.
- Webhook 서명 검증, retry, idempotency 같은 운영 설계가 궁금하다.
그래서 핵심 답은 단순하다. Gemini API Webhooks는 “코드가 예뻐지는 기능”이 아니라 AI 작업을 제품 운영 시스템에 붙이는 기능이다. Batch, agent, video generation처럼 오래 걸리는 작업을 다룬다면, Webhooks는 latency를 줄이고, 불필요한 status call을 줄이며, 후속 처리를 안정적으로 연결하는 기본 부품이 된다.
실무 적용 순서
바로 프로덕션에 붙이기보다 아래 순서가 좋다.
- 가장 오래 걸리는 Gemini 작업 하나를 고른다. 보통 batch 평가, 대량 요약, 영상 생성이 시작점이다.
- 내부 job table을 먼저 정리한다. operation id, 상태, 재시도, 사용자/tenant 정보를 남긴다.
- Static webhook으로 공통 이벤트 수신을 만든다. 초기에는 중앙 endpoint 하나가 디버깅하기 쉽다.
- 서명 검증과 idempotency를 테스트한다. 중복 이벤트, 잘못된 서명, 오래된 이벤트를 모두 처리해야 한다.
- 성공/실패 이벤트를 내부 queue로 넘긴다. callback handler는 짧게 유지한다.
- 필요한 경우 dynamic webhook으로 tenant/workflow별 라우팅을 확장한다. 처음부터 너무 많은 endpoint를 만들 필요는 없다.
- 낮은 빈도의 reconciliation job을 둔다. webhook 누락이나 장애 복구를 위한 안전망이다.
결론: Agent 시대의 API는 응답보다 완료 이벤트가 중요해진다
Gemini API Webhooks의 본질은 “Google도 webhook을 지원한다”가 아니다. 더 정확히는, AI 작업이 채팅 응답을 넘어 batch, agent interaction, video generation, deep research 같은 장시간 운영 흐름으로 확장되면서 완료 이벤트 자체가 제품 설계의 핵심 인터페이스가 됐다는 신호다.
한국 개발팀이 이 업데이트에서 읽어야 할 실무 메시지는 분명하다. 앞으로 AI 기능을 만들 때는 모델 호출 함수보다 job lifecycle, callback security, idempotency, retry, observability를 먼저 설계해야 한다. 좋은 AI 제품은 똑똑한 응답을 만드는 것에서 끝나지 않는다. 오래 걸리는 작업을 안전하게 맡기고, 끝났을 때 정확히 이어받고, 실패했을 때 복구할 수 있어야 한다.
한 줄로 정리하면 이렇다.
Gemini API Webhooks는 AI 작업을 “기다리는 API”에서 “운영 가능한 이벤트 시스템”으로 바꾸는 업데이트다.