- Published on
CocoIndex: 에이전트 컨텍스트는 RAG가 아니라 증분 동기화 문제다
- Authors

- Name
- Kyunghyun Park
- @devkhpark
CocoIndex · Agent Context · Incremental RAG
CocoIndex가 GitHub Trending에 오른 이유를 단순히 "새 RAG 도구가 하나 더 나왔다"로 보면 핵심을 놓친다. 더 중요한 신호는 이것이다. 장기 실행 AI 에이전트에서 컨텍스트는 검색 기능이 아니라 계속 동기화해야 하는 운영 데이터다.

CocoIndex의 GitHub 설명은 짧다. "Incremental engine for long horizon agents." 공식 README는 조금 더 직접적이다. codebase, meeting notes, inbox, Slack, PDF, video 같은 소스를 AI agent와 LLM app이 추론할 수 있는 live context로 바꾸되, 매번 전체를 다시 처리하지 않고 변경분만 처리한다는 것이다.
이 글은 CocoIndex의 공식 README, V1 발표 글, 문서의 core concepts/live mode/quickstart, 그리고 PyPI 메타데이터를 바탕으로 왜 이 도구가 지금 개발자들에게 관심을 받는지 정리한다. 결론부터 말하면, CocoIndex의 포인트는 "벡터 DB에 더 쉽게 넣는다"가 아니라 에이전트 시대의 컨텍스트 파이프라인을 batch ETL에서 change-data-capture에 가까운 형태로 바꾼다는 데 있다.
기준 시점: 이 글은 2026-05-05에 확인한 CocoIndex 공식 GitHub, 문서, 블로그, PyPI 정보를 기준으로 작성했다. CocoIndex 문서에는 v1.0.0-alpha48 문서가 포함되어 있고, PyPI에는 1.0.2가 공개되어 있었다.
왜 지금 이 주제인가: 에이전트는 사람보다 빨리 움직이는데 컨텍스트는 어제 밤 배치에 묶여 있다
CocoIndex V1 발표 글에서 가장 좋은 문장은 기술 설명이 아니라 문제 정의다. 에이전트는 사람보다 훨씬 빠른 속도로 작업하지만, 그 에이전트가 의존하는 데이터 도구는 여전히 사람의 속도에 맞춰져 있다는 주장이다.
전통적인 RAG 파이프라인은 보통 이렇게 생겼다.
- 문서를 모은다.
- chunk로 쪼갠다.
- embedding을 만든다.
- vector store에 넣는다.
- 주기적으로 전체 또는 큰 묶음을 다시 돈다.
이 방식은 문서가 가끔 바뀌고 사람이 가끔 검색할 때는 충분히 괜찮다. 문제는 에이전트가 들어오면 데이터의 성격이 바뀐다는 점이다. 코딩 에이전트는 파일을 수정하고, 빌드 로그를 만들고, 실패 원인을 기록하고, plan과 decision을 남긴다. 업무 에이전트는 Slack, 티켓, 회의록, 이메일, API 이벤트를 계속 읽고 다시 쓴다. 즉 컨텍스트는 정적인 지식베이스가 아니라 에이전트가 일하는 동안 계속 변하는 작업 표면이 된다.
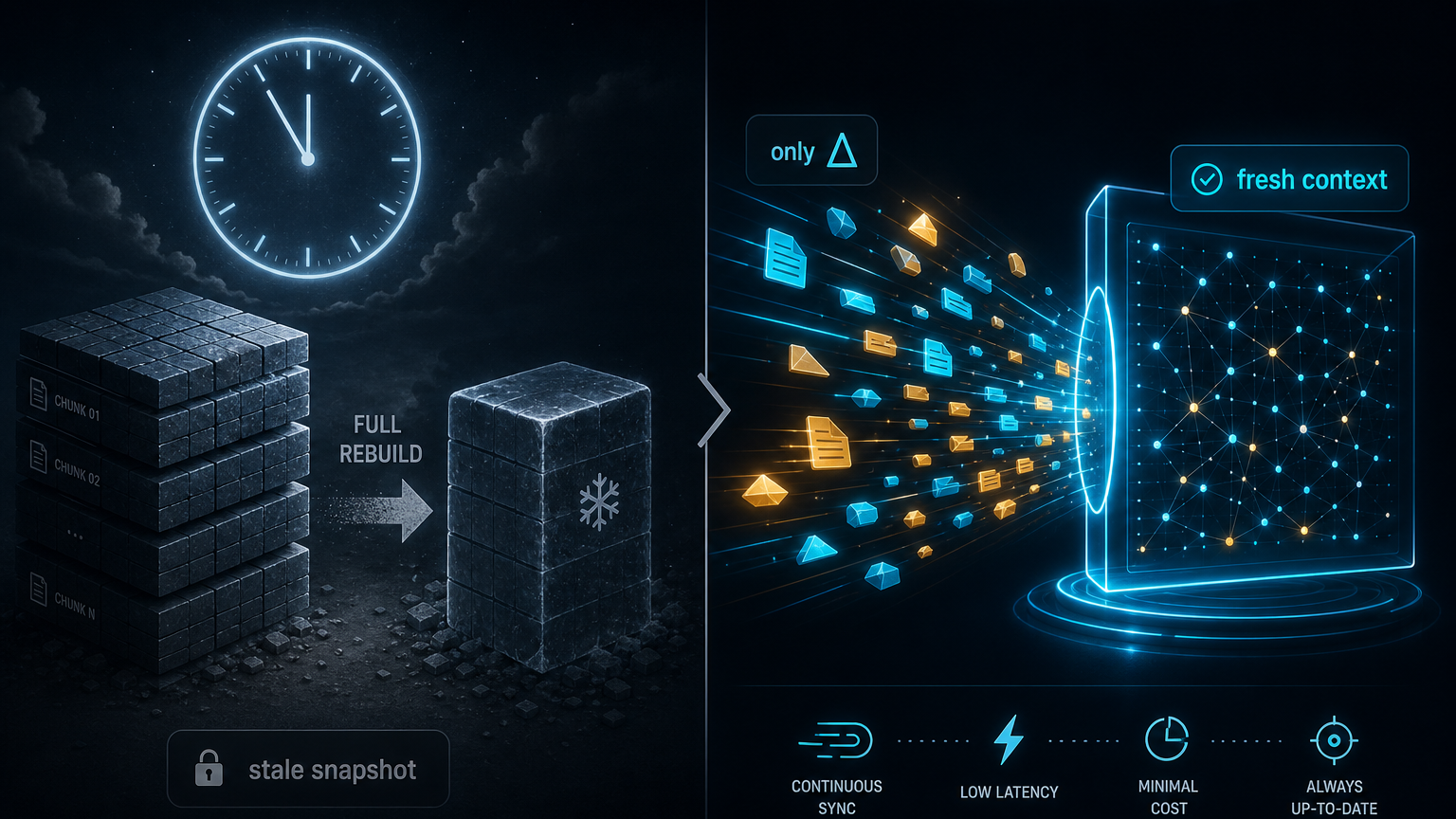
여기서 nightly rebuild 방식은 바로 병목이 된다. 에이전트가 방금 만든 파일, 방금 실패한 테스트 로그, 방금 바뀐 요구사항이 다음 추론에 안 들어가면 에이전트는 낡은 세계를 보고 행동한다. 반대로 모든 변경마다 전체 embedding을 다시 돌리면 비용과 지연시간이 터진다.
그래서 CocoIndex가 잡은 문제는 RAG의 UX가 아니라 RAG의 freshness다. 더 정확히는 "검색 정확도" 이전에 "지금 agent가 보는 컨텍스트가 최신인가"를 묻는다.
CocoIndex의 핵심 정신: TargetState = Transform(SourceState)
CocoIndex 문서가 반복해서 쓰는 정신 모델은 state-driven programming이다. 문서는 이를 React, spreadsheet, materialized view에 비유한다. 사용자는 "어떻게 delta를 계산할지"를 직접 절차적으로 구현하는 대신, 현재 source state로부터 target state가 어떻게 생겨야 하는지를 선언한다.
공식 문서의 핵심 식은 이렇게 요약된다.
TargetState = Transform(SourceState)
이 문장이 중요한 이유는 단순하다. 대부분의 AI 데이터 파이프라인에서 진짜 어려운 부분은 transform 함수 자체보다 변경 추적과 재처리 범위 결정이다.
- 어떤 파일이 바뀌었는가?
- chunk 수가 줄었을 때 target vector row는 어떻게 삭제할 것인가?
- embedding 로직이 바뀌면 무엇을 backfill해야 하는가?
- 중간 계산 결과를 어디까지 재사용할 수 있는가?
- 실패했을 때 target state와 source state의 불일치를 어떻게 복구할 것인가?
CocoIndex 문서는 이 문제를 정면으로 다룬다. source와 code가 모두 바뀔 수 있고, 매번 전체 재처리는 비싸고 느리고 disruptive하다고 설명한다. 그래서 processing component와 function memoization을 통해 입력과 코드가 바뀌지 않은 계산은 건너뛰고, target에는 삽입·수정·삭제를 적용한다.
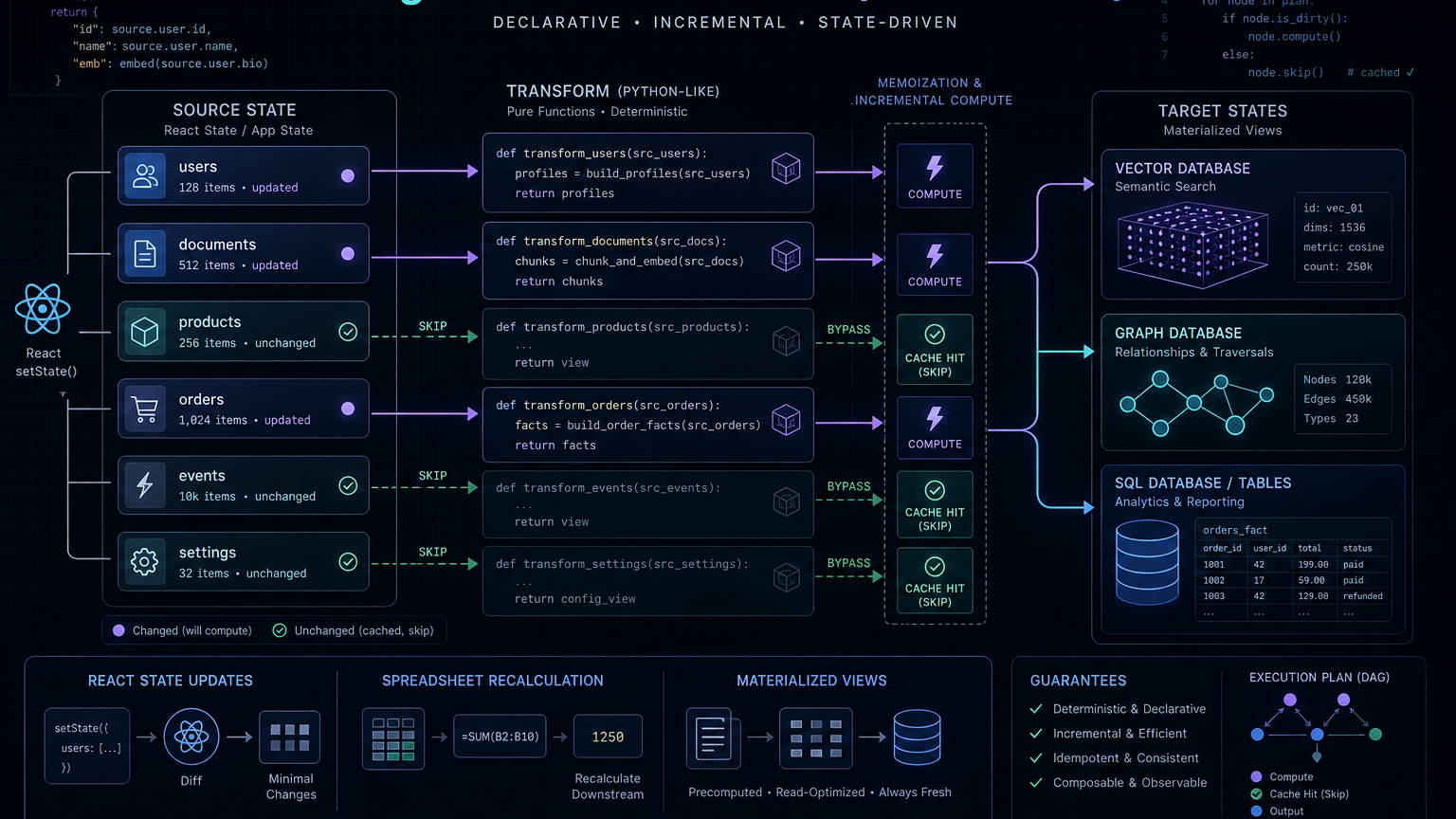
이건 AI 앱 개발자에게 꽤 실무적인 차이를 만든다. 기존에는 "문서가 바뀌면 다시 인덱싱한다"라는 느슨한 운영 규칙만 있었다. CocoIndex식 모델에서는 각 파일, 메시지, row, event가 target state의 어떤 부분을 만들어내는지 더 명시적으로 관리한다.
결국 CocoIndex는 RAG를 검색 기능이 아니라 derived data system으로 보는 쪽에 가깝다. 이 관점에서는 vector store도, graph DB도, SQL table도 모두 source state에서 파생된 target state다. 중요한 건 "어디에 저장하느냐"보다 "어떻게 계속 맞춰두느냐"다.
V1에서 눈에 띄는 변화: DSL을 버리고 regular async Python으로 간다
CocoIndex V1 발표 글에서 가장 제품적으로 중요한 변화는 "no DSL anymore"다. V1은 별도의 DSL 대신 regular async Python으로 pipeline을 작성하는 방향으로 바뀌었다고 설명한다.
이 선택은 생각보다 크다. AI 엔지니어와 에이전트 빌더에게 파이프라인 DSL은 처음에는 깔끔해 보이지만, 실제 업무에서는 금방 마찰이 생긴다.
- 기존 Python 코드와 타입을 재사용하기 어렵다.
- LLM coding agent가 DSL의 세부 규칙을 헷갈릴 가능성이 높다.
- 조건부 처리, multi-phase reduction, entity resolution, per-tenant topology처럼 현실적인 분기가 늘어나면 DSL이 답답해진다.
- 디버깅 도구와 IDE 지원이 약해진다.
CocoIndex가 Python-native surface를 강조하는 이유는 여기에 있다. README도 "Declarative · Python, 5 min"을 전면에 놓고, V1 글은 Claude나 Cursor가 이미 잘 쓰는 언어와 데이터 타입 안에서 동작하는 것이 중요하다고 말한다.
여기서 흥미로운 포인트는 CocoIndex 자체가 에이전트 친화적인 인프라를 말하면서, 개발 표면도 에이전트가 다루기 쉬운 쪽으로 고른다는 점이다. 장기적으로는 이런 도구가 중요해진다. 사람이 처음 파이프라인을 짜는 것보다, 에이전트가 새로운 data source와 target을 추가하고, 실패한 transform을 고치고, schema 변경을 따라가는 일이 더 많아질 수 있기 때문이다.
Live mode는 "자동 갱신"이 아니라 에이전트 운영 루프의 일부다
CocoIndex 문서의 live mode 설명도 중요하다. 기본 app.update()는 catch-up mode다. 지금까지 바뀐 것을 스캔하고, memoized component는 건너뛰고, target state를 맞춘 뒤 종료한다. 반면 live=True를 주면 초기 catch-up 이후에도 앱이 계속 떠 있으면서 source change에 반응한다.
문서에 따르면 live mode는 두 경우에 특히 유용하다.
- source 변경에 near-real-time으로 반응해야 할 때
- source가 full rescan보다 더 효율적으로 change stream을 제공할 때
CocoIndex는 LiveMapView와 LiveMapFeed라는 개념으로 이 차이를 설명한다. 파일시스템처럼 현재 상태를 스캔하고 이후 watcher로 변경을 받는 source는 LiveMapView에 가깝고, Kafka topic처럼 snapshot 없이 stream으로만 들어오는 source는 LiveMapFeed에 가깝다.
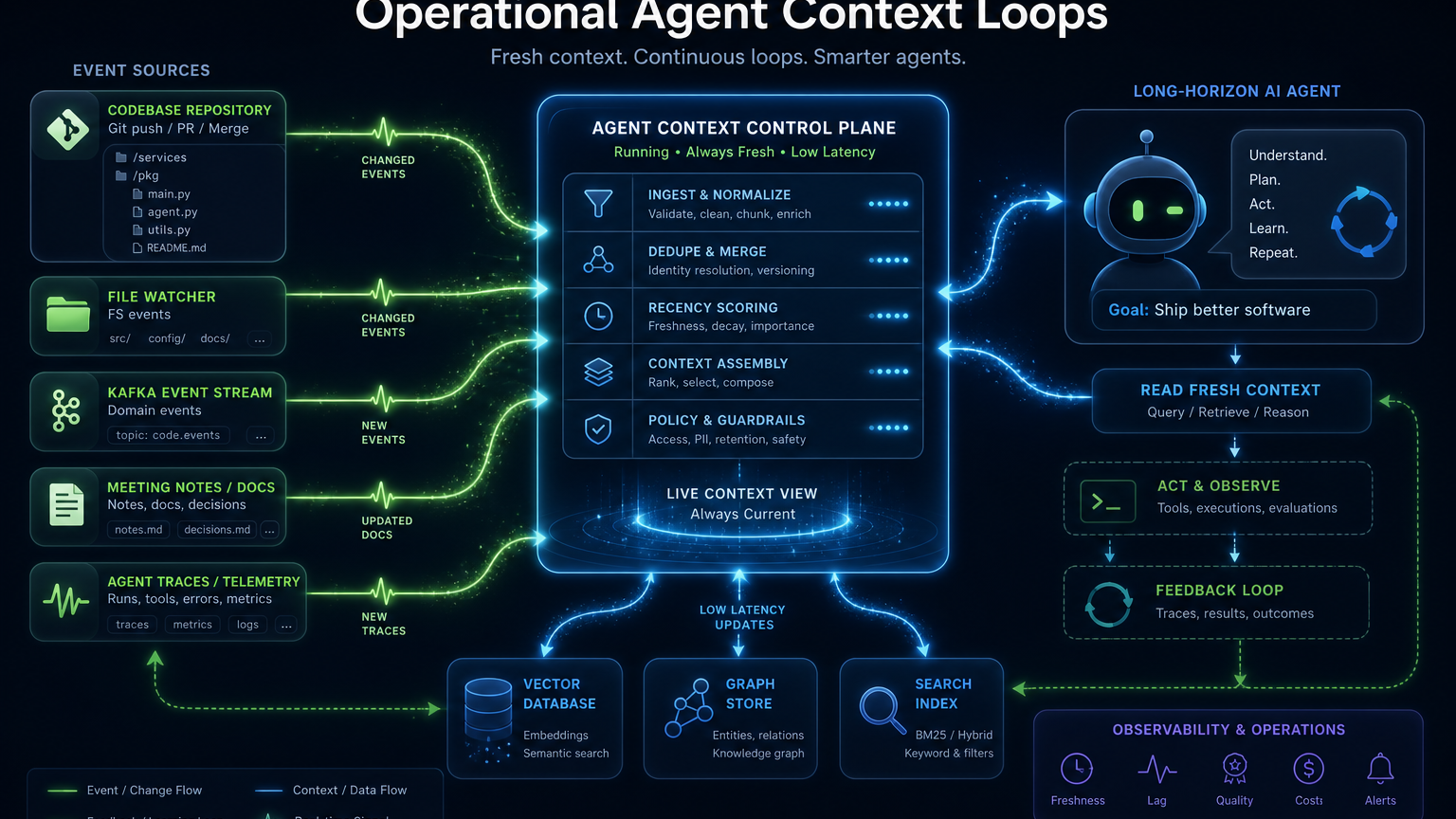
이건 단순히 편한 옵션이 아니다. 장기 실행 에이전트에서 live mode는 운영 루프의 일부가 된다. 예를 들어 코딩 에이전트가 리포지토리를 고치고, 테스트 로그를 만들고, 리뷰 코멘트를 반영한다고 해보자. 이때 code index가 몇 시간 전 상태에 머물러 있으면 에이전트는 자기 자신이 만든 최신 변화를 제대로 참조하지 못한다.
반대로 변경 이벤트가 작게 들어오고, 바뀐 component만 다시 처리되고, target state가 빠르게 동기화되면 에이전트는 더 긴 작업을 해도 컨텍스트 드리프트가 줄어든다. 이게 CocoIndex가 말하는 long horizon agents의 실제 의미에 가깝다.
예제 구성이 보여주는 방향: 벡터 검색만이 아니라 그래프, 멀티모달, 구조화 추출까지 간다
CocoIndex examples 페이지는 이 도구의 방향을 꽤 잘 보여준다. 20개 예제, 9개 source, 6개 target, 5개 LLM provider를 내세우고, 카테고리도 vector index, custom building block, structured extraction, knowledge graph, multimodal, agent로 나뉜다.
이 구성이 중요한 이유는 CocoIndex가 자신을 단순 vector indexing wrapper로 포지셔닝하지 않기 때문이다. 예제에는 codebase indexing, academic paper index, Postgres source, Hacker News custom source, image search, knowledge graph 계열이 포함된다. 즉 실제 agent context는 텍스트 chunk와 embedding 하나로 끝나지 않는다는 전제를 깔고 있다.
실무에서도 이 전제가 맞다. 한국 개발팀이 사내 AI 에이전트를 만든다고 해도 컨텍스트는 보통 섞여 있다.
| 컨텍스트 종류 | 필요한 target | 실패 방식 |
|---|---|---|
| 코드베이스 | syntax-aware chunk, vector/search index | 최신 파일 변경 누락, symbol 단위 맥락 손실 |
| 회의록/문서 | vector index, summary table | 오래된 정책 참조, 중복 문서 혼동 |
| 티켓/PR/Slack | SQL, graph, search | 권한 경계 붕괴, 최신 결정 누락 |
| 실행 trace/log | time-series/search table | 실패 재현 불가, 평가 데이터 누락 |
| 이미지/PDF/멀티모달 | OCR, embedding, metadata | modality별 검증 기준 부재 |
그래서 앞으로의 agent context stack은 "어떤 vector DB를 쓸 것인가"보다 더 넓어진다. source connector, incremental transform, target reconciliation, live update, schema evolution, observability가 모두 필요하다.
검색 의도 관점에서 보면: CocoIndex는 RAG 키워드보다 agent memory 키워드에 더 가깝다
SEO 관점에서도 CocoIndex를 단순히 "RAG framework"로만 잡으면 차별성이 약하다. 이미 LangChain, LlamaIndex, Haystack, vector DB 문서가 그 키워드를 많이 차지하고 있다. CocoIndex가 더 강하게 연결되는 검색 의도는 아래에 가깝다.
- AI agent context engineering
- incremental RAG pipeline
- live codebase indexing for AI agents
- agent memory infrastructure
- long-horizon agent data pipeline
- vector index incremental update
- change data capture for LLM apps
즉 사용자는 "RAG가 뭔가요"를 묻는 게 아니라, 이미 RAG를 붙여봤고 다음 문제를 겪는 사람일 가능성이 높다.
- 문서가 자주 바뀌는데 전체 embedding 비용이 부담된다.
- 에이전트가 오래 돌수록 컨텍스트가 낡아진다.
- 코드베이스 인덱스가 PR 단위 변경을 제대로 따라가지 못한다.
- Slack/회의록/문서/티켓이 따로 놀아서 agent가 최신 결정을 놓친다.
- multi-tenant 또는 권한 경계를 유지하면서 indexing해야 한다.
이 사람들에게 필요한 메시지는 "더 좋은 검색"이 아니라 "낡지 않는 컨텍스트"다. CocoIndex가 흥미로운 이유도 여기에 있다.
실무 해석: 작은 팀도 컨텍스트 파이프라인을 소프트웨어처럼 다뤄야 한다
CocoIndex를 당장 도입하느냐와 별개로, 여기서 배울 점은 명확하다. AI 에이전트 프로젝트를 시작할 때 프롬프트와 모델만 먼저 정하면 안 된다. 컨텍스트 파이프라인도 별도의 제품처럼 설계해야 한다.
실무적으로는 최소한 다음 질문을 먼저 던지는 편이 좋다.
1) 무엇이 source of truth인가?
코드, 문서, Slack, 티켓, 고객 DB, 로그 중 무엇을 agent가 믿어야 하는지 정해야 한다. 모든 것을 한 vector store에 밀어 넣으면 retrieval은 쉬워져도 권한, 최신성, 충돌 처리가 어려워진다.
2) 변경 단위는 무엇인가?
파일 단위, chunk 단위, row 단위, message 단위, event 단위 중 무엇을 delta로 볼 것인가. 변경 단위가 너무 크면 재처리 비용이 커지고, 너무 작으면 target reconciliation이 복잡해진다.
3) target state를 어떻게 검증할 것인가?
embedding row 수, graph edge 수, 삭제 처리, schema migration, backfill 결과를 검증해야 한다. 에이전트가 최신 정보를 못 찾는 문제는 모델 hallucination처럼 보이지만 실제로는 index drift일 수 있다.
4) live mode가 필요한가, catch-up으로 충분한가?
모든 source를 실시간으로 볼 필요는 없다. 규정 문서나 제품 매뉴얼은 catch-up batch로 충분할 수 있다. 하지만 code, trace, ticket, incident log처럼 에이전트가 작업 중 계속 읽고 쓰는 데이터는 live update가 훨씬 중요하다.
5) 에이전트가 파이프라인을 수정할 수 있는가?
V1이 Python-native surface를 강조하는 대목은 여기서 실무적이다. 앞으로는 사람이 매번 connector와 transform을 작성하기보다, coding agent가 새 source를 붙이고 pipeline을 고치는 일이 늘어날 것이다. 그러려면 파이프라인 정의가 일반 개발 도구와 잘 맞아야 한다.
한계도 있다: CocoIndex가 모든 에이전트 운영 문제를 해결하는 것은 아니다
과장하면 안 된다. CocoIndex가 해결하려는 문제는 중요하지만, 이것만으로 production agent가 완성되지는 않는다.
- tool permission과 policy enforcement는 별도 계층이 필요하다.
- retrieval 품질 평가는 여전히 직접 만들어야 한다.
- 민감 데이터 masking, row-level permission, tenant isolation은 설계 이슈다.
- 어떤 context를 agent에게 보여줄지 결정하는 ranking/eval은 여전히 어렵다.
- live mode는 장애 복구, backpressure, observability와 함께 봐야 한다.
즉 CocoIndex는 agent runtime 전체가 아니라 context synchronization layer에 가깝다. 하지만 바로 그 계층이 지금까지 너무 가볍게 다뤄졌다. 많은 AI 앱은 model call과 prompt에는 신경 쓰면서, 정작 모델이 보는 지식이 어떻게 최신 상태를 유지하는지는 느슨하게 관리한다.
결론: 에이전트 시대의 RAG는 검색보다 동기화가 먼저다
CocoIndex가 흥미로운 이유는 도구 자체보다 방향성에 있다. AI 에이전트가 길게 일하고, 스스로 파일과 기록을 만들고, 여러 시스템의 상태를 읽어야 한다면 컨텍스트는 더 이상 한 번 만들어두는 인덱스가 아니다.
앞으로 중요한 질문은 "어떤 모델이 더 똑똑한가"만이 아니다.
- 에이전트가 보는 컨텍스트는 얼마나 최신인가?
- 변경분만 싸게 반영할 수 있는가?
- source와 target의 불일치를 발견하고 복구할 수 있는가?
- vector, graph, SQL, search target을 같은 운영 원칙으로 다룰 수 있는가?
- 사람이 아니라 에이전트가 파이프라인을 확장해도 유지 가능한가?
CocoIndex는 이 질문에 꽤 선명한 답을 내놓는다. 에이전트 컨텍스트는 RAG 튜토리얼의 마지막 단계가 아니라, 장기 실행 에이전트를 가능하게 하는 증분 데이터 인프라다. 한국 개발팀이 에이전트 프로젝트를 운영 단계로 밀어붙이려 한다면, 지금 봐야 할 것은 더 화려한 챗 UI가 아니라 이런 지루한 동기화 계층이다.
참고한 자료
- CocoIndex GitHub, cocoindex-io/cocoindex — GitHub Trending 2026-05-05 기준 확인. Repository metadata: Python, Apache-2.0, 약 7.8k stars, 2026-05-04 pushed.
- CocoIndex Blog, CocoIndex V1 is Live!, 2026-04-22.
- CocoIndex Docs, Core concepts — incremental processing, state-driven programming, target state, memoization.
- CocoIndex Docs, Running in live mode — catch-up mode,
live=True,LiveMapView,LiveMapFeed. - CocoIndex Docs, Quickstart and Examples.
- PyPI, cocoindex — version 1.0.2 metadata checked on 2026-05-05.