- Published on
Anthropic Cybersecurity Skills: 보안 AI 에이전트는 이제 프롬프트보다 플레이북이 중요하다
- Authors

- Name
- Kyunghyun Park
- @devkhpark
AI Agent · Cybersecurity Skills · MITRE ATT&CK · Agent Operations
보안 AI 에이전트에서 지금 중요한 질문은 "어떤 모델이 더 똑똑한가"가 아니다. 더 실무적인 질문은 이것이다. 모델이 침해 조사, 위협 헌팅, 클라우드 사고 대응, 악성코드 분석 같은 작업을 할 때 어떤 절차를 따라야 하는가.

2026년 6월 22일 GitHub Trending에서 다시 눈에 띈 mukul975/Anthropic-Cybersecurity-Skills는 이 변화를 잘 보여준다. 이 저장소는 README 기준으로 754개 production-grade cybersecurity skills, 26개 보안 도메인, 26개 이상 AI 플랫폼 호환성을 내세운다. 별도 index.json은 2026년 6월 20일 생성된 version: 1.1.0 인덱스와 762개 스킬 항목을 담고 있다. README와 인덱스의 숫자가 약간 다르다는 점까지 포함해, 이 프로젝트는 빠르게 움직이는 커뮤니티형 지식 패키지에 가깝다.
중요한 건 숫자 자체가 아니다. 이 프로젝트가 흥미로운 이유는 보안 지식을 "멋진 프롬프트 모음"이 아니라 에이전트가 설치해서 실행할 수 있는 구조화된 운영 플레이북으로 다룬다는 점이다.
기준 시점: 이 글은 2026-06-22에 확인한 GitHub README, GitHub API 메타데이터,
index.json,ATTACK_COVERAGE.md,.claude-plugin/plugin.json,SECURITY.md를 바탕으로 썼다. 이 저장소는 커뮤니티 프로젝트이며 Anthropic PBC 공식 프로젝트가 아니라고 README가 명시한다.
이 프로젝트의 본질은 "보안 프롬프트팩"이 아니라 절차 지식의 패키징이다
README의 첫 메시지는 꽤 직설적이다. 주니어 분석가는 의심스러운 메모리 덤프에서 어떤 Volatility3 플러그인을 돌려야 하는지, Kerberoasting을 잡는 Sigma 규칙이 무엇인지, 클라우드 침해 범위를 어떻게 좁혀야 하는지 안다. 하지만 일반 LLM 에이전트는 그런 실무 플레이북을 기본으로 갖고 있지 않다.
이 차이가 보안 영역에서는 치명적이다. 보안 작업은 "그럴듯한 설명"보다 순서, 증거, 검증, 범위 통제가 중요하다. 예를 들어 침해 사고 대응에서 모델이 로그를 요약하는 능력만 갖고 있으면 부족하다. 무엇을 먼저 보존해야 하는지, 어떤 가설을 세우고 배제해야 하는지, 어떤 쿼리를 돌린 뒤 어떤 증거를 남겨야 하는지까지 알아야 한다.
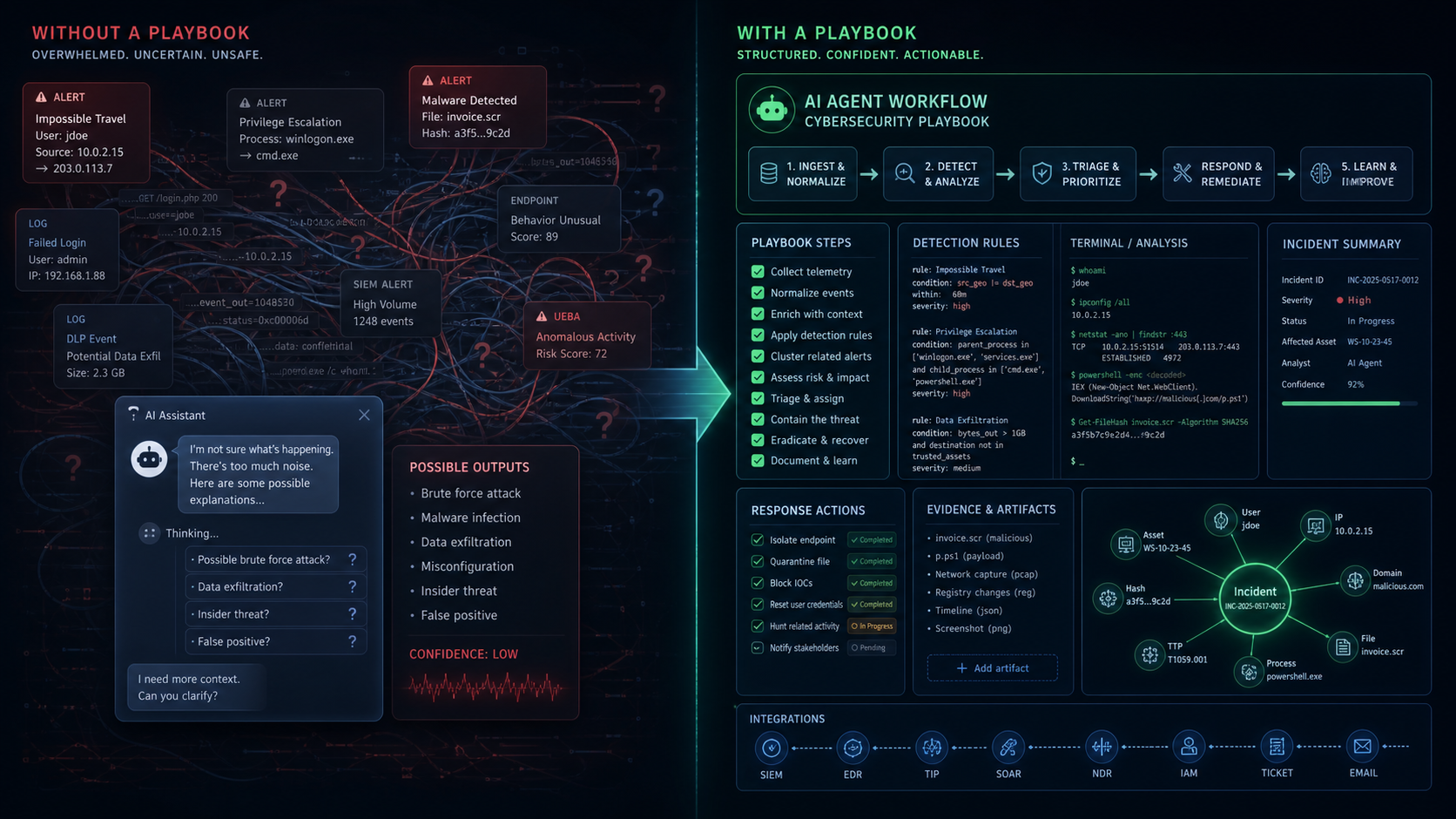
그래서 Anthropic-Cybersecurity-Skills의 의미는 "보안 질문에 답을 잘하는 에이전트"보다 좁고 강하다. 이 저장소는 에이전트에게 다음과 같은 작업 단위를 제공하려 한다.
- 디스크 이미지를 포렌식 방식으로 획득한다.
- Active Directory ACL 오남용을 탐지한다.
- Android APK 악성코드를 정적 분석한다.
- API Gateway 접근 로그에서 이상 징후를 찾는다.
- Azure Activity Log와 sign-in log를 위협 관점으로 조회한다.
- APT 그룹의 기법을 MITRE Navigator로 분석한다.
즉, 모델에게 "보안을 잘해줘"라고 말하는 대신 작업별로 언제 쓰고, 무엇을 확인하고, 어떤 산출물을 검증해야 하는지를 주입하는 방식이다. 이건 프롬프트 엔지니어링보다 운영 지식 관리에 가깝다.
왜 지금 중요한가: 에이전트 보안은 모델 성능보다 지식 라우팅 문제로 바뀌고 있다
최근 AI 에이전트 흐름을 보면 도구 호출, MCP, 브라우저 조작, 코드 실행, 장기 작업 관리가 빠르게 보편화되고 있다. 하지만 보안 도메인에서는 도구를 많이 붙이는 것만으로 충분하지 않다. 오히려 도구가 많아질수록 잘못된 액션의 비용이 커진다.
예를 들어 같은 nmap, sigma, yara, volatility, kubectl, aws, az 명령이라도 문맥에 따라 의미가 완전히 달라진다.
- 운영 환경에서 돌려도 되는가?
- 증거 보존이 먼저인가, 격리가 먼저인가?
- 공격 시뮬레이션인가, 실제 침해 대응인가?
- 고객 시스템인가, 내부 랩 환경인가?
- 결과를 자동 조치로 연결해도 되는가, 사람 승인이 필요한가?
여기서 스킬 라이브러리는 에이전트의 "행동 기억" 역할을 한다. 모델이 매번 웹 검색으로 절차를 즉흥 조립하는 대신, 사전에 검토된 플레이북을 불러와 작업 흐름을 좁힌다. 검색 기반 RAG가 문서를 찾아주는 층이라면, 스킬은 행동 가능한 절차를 호출하는 층에 가깝다.
이 차이는 SEO용 키워드로도 중요하다. 앞으로 "AI security agent", "cybersecurity skills for AI agents", "MITRE ATT&CK agent workflow", "Claude Code security skills", "Codex CLI security automation" 같은 검색 의도는 단순 소개 글보다 실제 운영 설계를 찾는 쪽으로 이동할 가능성이 높다.
여섯 개 프레임워크 매핑이 진짜 차별점이다
이 저장소의 강한 포인트는 스킬 수보다 프레임워크 매핑이다. README는 모든 스킬을 다음 여섯 축에 연결한다고 설명한다.
| 프레임워크 | README 기준 범위 | 의미 |
|---|---|---|
| MITRE ATT&CK | v19.1, 15 tactics, 286 techniques | 공격자 행동과 TTP 기준 |
| NIST CSF 2.0 | 6 functions, 22 categories | 조직 보안 태세 기준 |
| MITRE ATLAS | v5.4, 16 tactics, 84 techniques | AI/ML 시스템 공격 기법 기준 |
| MITRE D3FEND | v1.3, 7 categories, 267 techniques | 방어 카운터메저 기준 |
| NIST AI RMF | 1.0, 4 functions, 72 subcategories | AI 위험관리 기준 |
| MITRE F3 | v1.1, 8 tactics, 123 techniques, 94 fraud-relevant skills | 사이버 금융사기 TTP 기준 |
이 매핑의 가치는 "컴플라이언스 체크박스가 많다"가 아니다. 더 실무적인 장점은 같은 보안 작업을 서로 다른 조직 언어로 번역할 수 있다는 것이다.
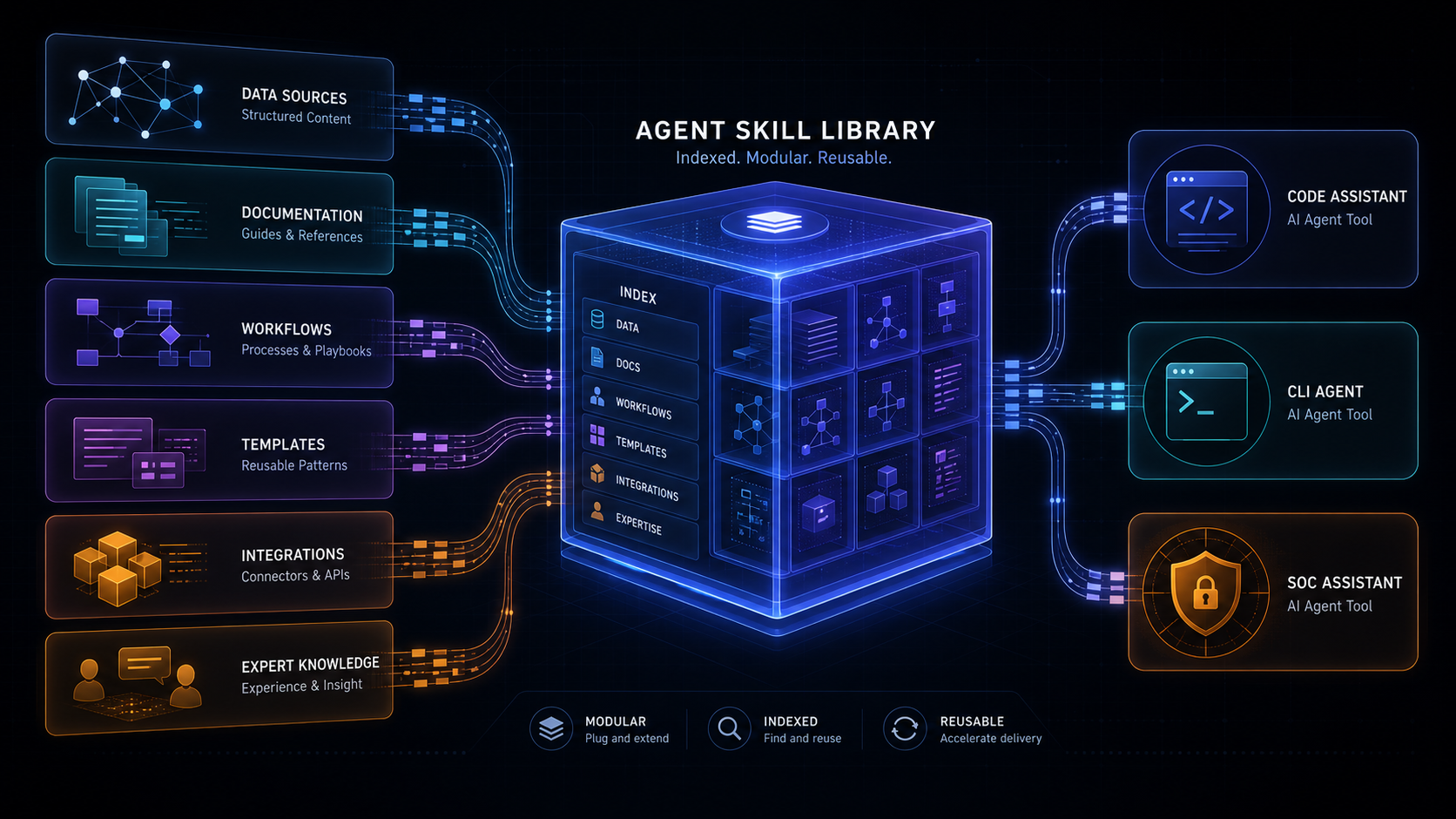
보안팀은 ATT&CK으로 위협 행동을 말한다. 경영진과 감사팀은 NIST CSF로 태세를 본다. AI 거버넌스 담당자는 AI RMF와 GenAI Profile을 본다. 머신러닝 보안팀은 ATLAS가 필요하다. 탐지·완화팀은 D3FEND가 더 직접적이다. 금융사기 대응팀은 F3가 중요할 수 있다.
하나의 스킬이 이 프레임워크들을 함께 갖고 있으면, 에이전트는 단순히 "이 명령을 실행하라"가 아니라 다음 질문에 답하기 쉬워진다.
- 이 작업은 어떤 ATT&CK 기법을 다루는가?
- 탐지 결과를 어떤 NIST CSF 기능과 연결할 수 있는가?
- AI 시스템 관련 위험이면 ATLAS나 AI RMF 관점에서 무엇을 기록해야 하는가?
- 방어 조치 추천은 D3FEND의 어떤 countermeasure와 연결되는가?
- 금융사기 맥락에서는 어떤 fraud tactic과 닿아 있는가?
이게 보안 AI 에이전트의 운영 품질을 바꾼다. 모델이 "답변"을 만드는 것이 아니라, 조직의 언어 체계 안에서 추적 가능한 작업 기록을 남길 수 있기 때문이다.
ATT&CK 커버리지 문서는 이 프로젝트가 어디까지 진지한지 보여준다
ATTACK_COVERAGE.md는 이 저장소가 단순한 README 마케팅에 그치지 않는다는 신호다. 이 문서는 753개 이상 사이버보안 스킬에서 참조하는 291개 unique MITRE ATT&CK techniques, 149개 parent techniques, 14개 Enterprise ATT&CK tactics 매핑을 설명한다. README의 최신 ATT&CK v19.1 표와 숫자는 다소 다르지만, 핵심은 같다. 이 프로젝트는 스킬을 프레임워크에 실제로 묶으려 한다.
커버리지 표를 보면 Defense Evasion, Persistence, Credential Access, Discovery, Command and Control 같은 영역이 눈에 띈다. 보안 자동화에서 위험한 영역과 유용한 영역이 동시에 몰려 있는 곳이다.
여기서 중요한 해석은 두 가지다.
첫째, 에이전트가 보안 도구를 쓰는 시대에는 커버리지 맵이 제품 기능이 된다. 어떤 스킬이 어느 공격 기법을 다루는지 알아야 SOC 자동화, threat hunting, incident response 워크플로에 넣을 수 있다.
둘째, 커버리지는 곧 책임 범위다. 스킬 라이브러리가 어떤 기법을 많이 다루는지 알면, 팀은 그 라이브러리를 어디에 적용하고 어디에는 적용하지 말아야 하는지 판단할 수 있다. 예를 들어 공격 시뮬레이션과 방어 탐지는 절차 일부가 겹치지만 권한·범위·로그 정책은 완전히 다르다.
플랫폼 호환성은 "에이전트 스킬의 배포 형식"이 표준화되고 있다는 신호다
README는 Claude Code, GitHub Copilot, Cursor, Windsurf, Cline, Aider, Continue, Roo Code, Amazon Q Developer, Tabnine, Sourcegraph Cody, JetBrains AI, OpenAI Codex CLI, Gemini CLI, Devin, Replit Agent, SWE-agent, OpenHands, LangChain, CrewAI, AutoGen, Semantic Kernel, Haystack, Vercel AI SDK, MCP 호환 에이전트 등을 호환 대상으로 적는다.
이 목록을 그대로 다 믿고 프로덕션 도입을 결정하면 안 된다. 플랫폼마다 스킬 로딩 방식, 권한 모델, 툴 호출 표면, 샌드박스 강도가 다르기 때문이다. 하지만 방향성은 분명하다. 스킬은 특정 챗봇의 내부 기능이 아니라, 여러 에이전트 런타임으로 이동 가능한 패키지 형식이 되고 있다.
.claude-plugin/plugin.json도 이 흐름을 보여준다. 이 파일은 cybersecurity-skills라는 이름, 753 cybersecurity skills covering web security, pentesting, DFIR, threat intelligence, cloud security, malware analysis, and more라는 설명, 1.0.0 버전을 담는다. 작고 단순한 메타데이터지만, 에이전트 생태계가 플러그인·스킬·패키지 단위로 움직이기 시작했다는 점에서는 의미가 있다.
개발자와 보안 운영자 입장에서 이건 꽤 큰 변화다. 과거에는 보안 자동화를 하려면 SIEM 룰, SOAR 플레이북, 스크립트, 런북, 위키 문서를 각각 관리했다. 이제는 그 일부가 에이전트가 직접 읽고 실행하는 portable skill package로 흡수될 수 있다.
하지만 이걸 그대로 설치하는 건 위험하다: 스킬도 공급망이다
여기서 냉정해져야 한다. 보안 스킬 라이브러리는 유용하지만, 동시에 매우 강한 공급망 리스크를 만든다. 에이전트에게 보안 절차를 가르친다는 건 곧 에이전트가 시스템, 로그, 클라우드 계정, 취약점 정보, 내부 네트워크에 더 가까이 다가간다는 뜻이다.

따라서 실무 도입 기준은 "별이 많다"가 아니라 다음이어야 한다.
1) 스킬 내용을 샘플링 검토해야 한다
index.json에 762개 항목이 있다는 건 장점이지만, 동시에 검토량이 크다는 뜻이다. 전체를 한 번에 신뢰하기보다 도메인별로 좁혀야 한다. 예를 들어 DFIR, 클라우드, Active Directory, Kubernetes, malware analysis, phishing response처럼 팀이 실제로 쓸 범위를 먼저 고른다.
2) 실행 권한을 분리해야 한다
보안 에이전트가 읽기 전용 로그 조회만 하는지, 클라우드 리소스를 변경할 수 있는지, 격리·차단 같은 액션을 할 수 있는지에 따라 위험도가 달라진다. 스킬이 아무리 좋아도 권한 모델이 허술하면 사고가 난다.
3) 스킬 패키지를 CI에서 검사해야 한다
에이전트 스킬은 이제 코드와 비슷하게 다뤄야 한다. 변경 diff, 출처, 라이선스, 위험 명령어, 외부 URL, 스크립트, 권한 요구사항을 검사해야 한다. 기존 글에서 다뤘던 agent skill security scanner 류의 도구가 바로 이 지점에서 필요해진다.
4) 산출물 검증을 강제해야 한다
보안 AI 에이전트가 "분석 완료"라고 말하는 것으로 끝나면 안 된다. 어떤 로그를 봤는지, 어떤 탐지 규칙을 적용했는지, 어떤 가설을 배제했는지, 어떤 증거가 남았는지 확인해야 한다. 스킬의 Verification 단계가 중요한 이유다.
5) 공격·방어 경계를 문서화해야 한다
침투 테스트, red team, threat hunting, incident response는 도구와 절차가 일부 겹친다. 하지만 법적·운영적 허용 범위는 다르다. 보안 스킬을 에이전트에 넣을 때는 "무엇을 하면 안 되는가"를 스킬보다 더 명확히 써야 한다.
실무 적용 방식: 전사 도입보다 작은 폐쇄 루프로 시작하라
이런 라이브러리를 보고 바로 "우리 SOC에 AI 에이전트를 붙이자"로 가면 위험하다. 더 나은 접근은 작은 폐쇄 루프다.
- 읽기 전용 유스케이스를 고른다. 예: Azure sign-in log 이상 징후 요약, CloudTrail 이벤트 분류, Sigma 룰 후보 설명.
- 관련 스킬 5~10개만 가져온다. 전체 700개를 한 번에 설치하지 않는다.
- 내부 런북과 비교한다. 스킬이 조직 정책과 충돌하는지 확인한다.
- 샌드박스에서 실행한다. 실제 계정 변경 권한 없이 로그·샘플 데이터만 준다.
- 사람 검토를 기본값으로 둔다. 자동 조치는 마지막 단계다.
- 결과를 프레임워크에 매핑한다. ATT&CK, NIST CSF, AI RMF 기준으로 기록하면 감사와 개선 루프가 쉬워진다.
이 방식으로 보면 Anthropic-Cybersecurity-Skills는 완성된 제품이라기보다 보안팀이 자기 조직용 에이전트 런북을 만들 때 참고할 수 있는 대형 seed corpus에 가깝다. 그대로 쓰는 것보다 선별·검토·수정해서 쓰는 쪽이 현실적이다.
검색 의도 관점에서 볼 때, 이 주제는 "AI 보안 자동화"보다 더 구체적이다
한국어 검색에서는 아직 "AI 보안 자동화"나 "보안 AI 에이전트"가 넓은 키워드로 소비될 가능성이 크다. 하지만 실제 독자가 찾는 건 더 구체적이다.
- Claude Code나 Codex CLI에 보안 스킬을 붙일 수 있는가?
- MITRE ATT&CK 기반으로 AI 에이전트 워크플로를 만들 수 있는가?
- SOC 자동화에 LLM 에이전트를 넣을 때 무엇을 검증해야 하는가?
- 보안 플레이북을 에이전트가 읽을 수 있는 패키지로 관리할 수 있는가?
- agent skills는 프롬프트 라이브러리와 무엇이 다른가?
이 글의 결론도 그 지점에 있다. 보안 AI 에이전트의 차별점은 더 센 모델 이름이 아니라 좋은 플레이북을 어떤 권한·검증·감사 구조 안에서 실행하느냐다.
짧은 결론: 보안 에이전트의 경쟁력은 "프롬프트"에서 "검증 가능한 절차"로 이동한다
mukul975/Anthropic-Cybersecurity-Skills는 완벽한 정답이라기보다 강한 신호다. 보안 AI 에이전트 시장은 이제 모델 성능 경쟁만으로 설명되지 않는다. 중요한 층은 그 위에 있다.
- 어떤 절차 지식을 패키지로 관리하는가.
- 어떤 프레임워크에 매핑되는가.
- 어떤 에이전트 런타임에서 재사용되는가.
- 어떤 권한과 샌드박스 안에서 실행되는가.
- 어떤 감사 기록과 검증 단계를 남기는가.
보안팀이 AI 에이전트를 진지하게 다루려면, "좋은 프롬프트"보다 운영 가능한 스킬 공급망을 먼저 설계해야 한다. 이 저장소가 보여주는 가장 큰 메시지는 바로 그 전환이다.