- Published on
Firecrawl이 보여준 에이전트 시대의 웹 컨텍스트 API: 스크래핑이 아니라 데이터 평면이다
- Authors

- Name
- Kyunghyun Park
- @devkhpark
키워드: Firecrawl · AI 에이전트 · 웹 컨텍스트 API · LLM-ready data · RAG 데이터 파이프라인
Firecrawl을 "웹 스크래핑 도구"라고만 부르면 핵심을 놓친다. 2026년 6월 23일 기준 GitHub Trending에서 Firecrawl은 13위에 올랐고, GitHub API 기준으로 별 13.7만 개 이상, AGPL-3.0 라이선스, TypeScript 중심의 오픈소스 프로젝트다. 숫자보다 중요한 건 README와 문서가 가리키는 방향이다. Firecrawl은 이제 URL을 긁어오는 라이브러리가 아니라 AI 에이전트가 웹을 검색하고, 읽고, 상호작용하고, 구조화해서 사용할 수 있게 만드는 웹 컨텍스트 API에 가깝다.

이 글의 결론은 단순하다. 앞으로 에이전트 제품에서 경쟁력은 "모델이 웹에 접속할 수 있다"가 아니라 웹에서 가져온 정보를 얼마나 안정적으로, 검증 가능하게, 비용 예측 가능하게 컨텍스트로 바꾸느냐에서 갈린다. Firecrawl의 Search, Scrape, Extract, Agent, Interact 계층은 그 문제를 한 덩어리의 데이터 평면으로 묶으려는 시도다.
왜 지금 Firecrawl인가: 웹은 LLM에게 여전히 지저분하다
RAG나 에이전트 제품을 만들어 본 팀이라면 안다. 문제는 모델이 아니라 웹이다. 페이지는 자바스크립트로 렌더링되고, 광고와 팝업이 끼어들고, 본문보다 네비게이션 텍스트가 더 길고, PDF·DOCX 같은 파일이 섞이고, 검색 결과는 URL만 던져준다. 여기에 robots 정책, rate limit, 프록시, 동적 버튼, 페이지네이션까지 붙으면 "웹을 읽는다"는 말은 금방 작은 브라우저 인프라 사업이 된다.
Firecrawl README는 이 지점을 정면으로 찌른다. 프로젝트 설명은 "search, scrape, and interact with the web at scale"이고, 출력은 clean Markdown, structured JSON, screenshots 등 LLM이 바로 쓰기 쉬운 형태를 강조한다. 또 JS-heavy 페이지, proxy orchestration, rate limit, media parsing, click/scroll/write/wait/press 같은 action을 언급한다. 즉 단일 fetch(url) 래퍼가 아니라, 웹의 불안정성을 에이전트가 사용할 수 있는 안정된 입출력 계약으로 바꾸는 계층을 표방한다.

한국 개발자나 빌더 입장에서 이 포인트가 중요한 이유는 명확하다. 검색 기반 기능, 시장 조사 봇, 경쟁사 모니터링, 채용/부동산/커머스 데이터 수집, 문서 기반 고객지원, 내부 리서치 에이전트를 만들 때 결국 같은 질문으로 돌아온다.
- 검색 결과의 URL만 줄 것인가, 본문까지 함께 가져올 것인가?
- HTML을 그대로 넣을 것인가, Markdown으로 정리할 것인가?
- 자유 텍스트로 받을 것인가, JSON schema로 고정할 것인가?
- 동적 페이지나 페이지네이션은 누가 처리할 것인가?
- 결과가 틀렸을 때 어떤 소스와 요청에서 실패했는지 추적할 수 있는가?
Firecrawl이 관심을 받는 건 이 질문들이 이제 "부가 기능"이 아니라 에이전트 제품의 기본 운영 문제가 됐기 때문이다.
핵심 변화: Search, Scrape, Extract, Agent가 하나의 표면으로 모인다
Firecrawl 문서에서 가장 눈에 띄는 건 기능이 각각 따로 놀지 않는다는 점이다. /search는 쿼리를 받아 검색 결과의 제목, 설명, URL을 반환하고, scrapeOptions를 붙이면 결과 페이지의 Markdown, HTML, 링크, 스크린샷까지 함께 가져올 수 있다. 검색과 본문 수집이 분리된 두 단계가 아니라 하나의 호출 설계 안에 들어온다.
/scrape는 알려진 URL을 LLM-ready 형태로 바꾸는 기본 축이다. 반면 /extract는 URL 목록이나 와일드카드 도메인을 대상으로 prompt 또는 JSON schema를 주고 구조화 데이터를 뽑는다. 문서는 /extract가 여러 URL과 전체 도메인에도 쓰일 수 있고, enableWebSearch로 지정 도메인 밖 링크까지 따라갈 수 있다고 설명한다.
여기서 더 흥미로운 건 /agent다. Firecrawl 문서는 Agent를 "URL을 모를 때" 또는 "자율 탐색이 필요할 때" 쓰는 도구로 구분한다. 필수 입력은 prompt이고, 필요한 경우 schema를 붙여 결과를 구조화한다. 문서 표현대로라면 Agent는 검색하고, 탐색하고, 여러 사이트로 깊게 들어가 데이터를 찾는 방식이다. 다시 말해 URL-first 수집에서 intent-first 수집으로 넘어간다.
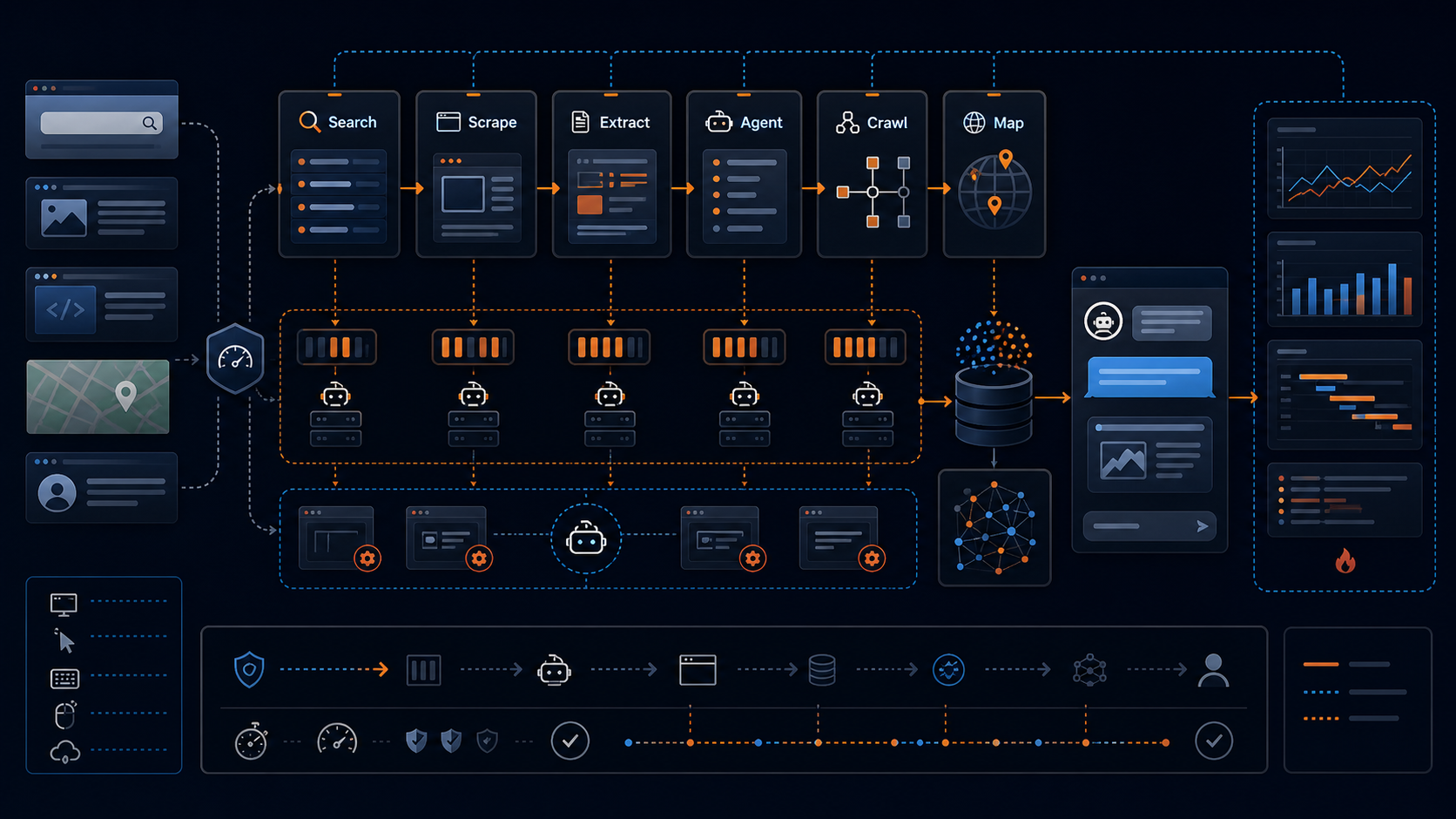
이 구조는 에이전트 앱 설계에 꽤 큰 차이를 만든다.
| 상황 | 더 적합한 계층 | 이유 |
|---|---|---|
| URL을 이미 알고 있고 본문만 필요함 | Scrape | 동기적이고 단순하다. Markdown/HTML/JSON 등 출력 제어가 핵심이다. |
| 여러 검색 결과의 본문이 필요함 | Search + scrapeOptions | 검색과 페이지 수집을 한 흐름으로 묶을 수 있다. |
| URL 집합에서 정해진 schema를 채워야 함 | Extract | prompt와 schema로 구조화 데이터 계약을 만들 수 있다. |
| 어디에 데이터가 있는지 모름 | Agent | 검색과 탐색 자체를 API에 맡기는 intent-first 방식이다. |
| 동적 페이지 조작이 필요함 | FIRE-1 / Interact | 버튼 클릭, 페이지네이션, 입력, 스크롤 같은 브라우저 행동이 필요하다. |
이 테이블의 실무적 의미는 "하나의 도구가 모든 문제를 푼다"가 아니다. 오히려 반대다. 웹 컨텍스트 수집을 작업 유형별로 라우팅할 수 있어야 한다. 알고 있는 URL은 싸고 빠른 scrape로, 불확실한 리서치는 agent로, 반복 도메인 추출은 extract로 보내는 식의 라우팅이 비용과 품질을 동시에 잡는다.
FIRE-1과 Interact: 에이전트가 웹을 읽는 것에서 조작하는 것으로 간다
Firecrawl의 FIRE-1 문서는 더 직접적이다. FIRE-1은 scraping capability를 지능형 웹 navigation과 interaction으로 확장하는 AI agent다. 문서가 든 예시는 페이지네이션을 자동으로 넘기고, 버튼·링크·입력·동적 요소를 다루고, 여러 페이지에 걸친 extraction task를 수행하는 것이다.
이건 단순 편의 기능이 아니다. 많은 업무 데이터는 첫 화면에 없다. "Load more"를 눌러야 나오고, 필터를 선택해야 보이고, 검색어를 입력해야 생성되며, 로그인 이후 페이지나 SPA 라우팅 안쪽에 숨어 있다. 기존 크롤러 방식은 이런 지점에서 brittle script가 된다. 반면 에이전트형 브라우저 조작 계층은 "다음 페이지 버튼을 더 이상 없을 때까지 누르고 각 페이지를 수집하라"처럼 목표 지향 프롬프트를 받는다.
물론 이 방식은 비용과 실패 모드도 달라진다. FIRE-1 문서도 task complexity와 interaction depth에 따라 더 많은 credits를 소비할 수 있다고 말한다. 그래서 실무에서는 무조건 Agent/FIRE-1로 보내면 안 된다. 다음 같은 정책이 필요하다.
- 기본은 deterministic scrape: 알려진 URL과 정적 문서는 가장 단순한 경로로 처리한다.
- schema가 있는 업무는 extract: 제품 가격, 채용 공고, API 변경점처럼 필드가 정해진 데이터는 schema를 먼저 만든다.
- 탐색 불확실성이 높을 때만 agent: 어디에 정보가 있는지 모를 때, 또는 사이트 안에서 탐색이 필요한 경우에만 쓴다.
- 반복 작업은 로그와 샘플 검수: 에이전트가 수집한 결과는 source URL, timestamp, prompt, schema, 실패 로그를 같이 남겨야 한다.
즉 Firecrawl류 도구를 붙인다고 해서 리서치 품질이 자동으로 올라가지는 않는다. 품질은 수집 계층을 운영하는 정책에서 나온다.
Self-hosting은 매력적이지만, 진짜 비용은 Playwright와 프록시 운영이다
Firecrawl은 오픈소스이고 self-hosting 문서도 제공한다. 문서는 보안과 컴플라이언스가 강한 조직, 내부 인프라 안에 데이터를 남겨야 하는 조직, 특정 Playwright 서비스나 scraping method를 커스터마이즈해야 하는 조직에 self-hosting이 유리할 수 있다고 설명한다.
하지만 같은 문서는 trade-off도 분명히 적는다. self-hosted instance는 Fire-engine의 고급 IP block/robot detection 처리 기능에 접근하지 못할 수 있고, 기본 fetch·Playwright를 넘어서는 scraping method는 .env에서 직접 구성해야 한다. 환경 변수 예시에는 Supabase 기반 인증, OpenAI/Ollama/OpenAI-compatible API, proxy server, search API용 SearXNG 같은 항목도 나온다.

여기서 한국 팀들이 자주 놓치는 부분이 있다. "오픈소스니까 직접 띄우면 싸다"는 계산은 반만 맞다. 단순 내부 문서나 제한된 도메인 수집이라면 self-hosting이 유리할 수 있다. 하지만 공개 웹 전체를 대상으로 높은 성공률을 요구하면 비용 항목이 급격히 늘어난다.
- Playwright worker와 브라우저 리소스 관리
- queue, retry, timeout, deduplication
- proxy 품질과 차단 대응
- search provider 선택과 장애 처리
- LLM extract 비용과 schema drift
- 개인정보/저작권/robots 정책 검토
- 결과 품질 샘플링과 모니터링
따라서 의사결정은 "hosted냐 self-hosted냐"가 아니라 어떤 데이터 범위에서 어떤 실패율을 감수할 수 있느냐로 해야 한다. 내부 도메인·파트너 사이트·문서 포털 중심이면 self-hosting 실험이 의미 있다. 반대로 공개 웹 검색, 경쟁사 모니터링, 실시간 리서치처럼 사이트 다양성이 높으면 hosted API의 운영 대체 가치가 커진다.
실무 해석: 에이전트 제품의 병목은 모델 호출보다 컨텍스트 공급망이다
지금 많은 팀이 모델 라우팅, 프롬프트, MCP, agent framework에 집중한다. 물론 중요하다. 하지만 Firecrawl이 보여주는 병목은 그보다 앞단에 있다. 에이전트가 답을 잘하려면 먼저 좋은 컨텍스트를 지속적으로 공급받아야 한다.
좋은 컨텍스트에는 네 가지 조건이 있다.
첫째, 출처가 남아야 한다. 웹에서 가져온 결과는 항상 URL, 수집 시점, 쿼리, schema, 원문 일부를 추적할 수 있어야 한다. 그래야 hallucination과 stale data를 구분할 수 있다.
둘째, 형태가 안정적이어야 한다. Markdown은 모델 입력에 좋고, JSON schema는 앱 로직에 좋다. 둘을 상황에 맞게 나누지 않으면 downstream 코드가 매번 예외 처리 지옥이 된다.
셋째, 비용 라우팅이 필요하다. 모든 요청을 브라우저 에이전트로 처리하면 멋있지만 비싸고 느리다. Search, Scrape, Extract, Agent를 업무 난이도에 따라 나누는 라우터가 있어야 한다.
넷째, 운영 경계가 있어야 한다. 공개 웹 데이터는 권리, 개인정보, robots, 계정 약관, 내부 보안 정책과 충돌할 수 있다. 특히 에이전트가 자동으로 클릭하고 탐색하는 단계로 가면 audit trail이 선택이 아니라 필수다.
이 관점에서 Firecrawl은 "우리 앱에 웹 검색 기능을 붙인다"보다 큰 의미를 갖는다. 에이전트 제품이 외부 세계를 읽는 방식, 즉 컨텍스트 공급망의 표준화에 가까운 문제를 건드린다.
도입 체크리스트: Firecrawl을 붙이기 전에 정해야 할 것
Firecrawl을 바로 붙여볼 수는 있다. 하지만 제품에 넣기 전에는 최소한 아래 결정을 먼저 해야 한다.
- 수집 범위: 공개 웹 전체인가, 특정 도메인 목록인가, 내부 문서 포털인가?
- 출력 계약: Markdown 중심인가, JSON schema 중심인가, 둘 다 필요한가?
- 갱신 주기: 요청 시점마다 실시간인가, 배치로 캐싱할 것인가?
- 검증 기준: 샘플링, source citation, 중복 제거, 실패 로그를 어떻게 볼 것인가?
- 비용 상한: Agent/FIRE-1 계층을 언제 허용하고 언제 금지할 것인가?
- 운영 방식: hosted API로 갈 것인가, self-hosting으로 통제권을 확보할 것인가?
내 추천은 작게 시작하는 것이다. 먼저 search + scrapeOptions 또는 알려진 URL에 대한 scrape로 실제 서비스 쿼리 50개를 돌려보고, Markdown 품질과 누락률을 본다. 그다음 schema가 명확한 업무 하나를 골라 /extract를 붙인다. 마지막으로 URL을 모르는 리서치나 동적 페이지가 꼭 필요한 작업에만 /agent 또는 FIRE-1 계층을 실험한다.
결론: 웹을 읽는 에이전트는 브라우저보다 데이터 계약이 필요하다
Firecrawl의 인기는 스크래핑의 부활이 아니다. 더 정확히는 에이전트 시대에 웹 컨텍스트를 공급하는 인프라가 제품의 핵심 부품으로 올라왔다는 신호다. 모델은 점점 더 길고 똑똑해지지만, 웹은 여전히 지저분하고 동적이며 실패하기 쉽다. 이 간극을 메우는 계층이 없으면 에이전트는 좋은 답변 대신 그럴듯한 추측을 하게 된다.
한국의 개발자와 운영팀에게 실질적인 메시지는 이것이다. AI 에이전트 로드맵을 짤 때 모델, 프롬프트, UI만 보지 말고 웹 컨텍스트 데이터 평면을 별도 아키텍처 항목으로 잡아야 한다. Firecrawl을 쓰든 직접 만들든, 검색·스크레이핑·구조화·브라우저 조작·출처 추적·비용 라우팅을 하나의 운영 체계로 설계해야 한다. 그게 없으면 에이전트 제품은 데모에서는 빛나도 운영에서는 금방 흔들린다.