- Published on
Codebase-Memory MCP: 코딩 에이전트의 다음 병목은 파일 탐색이 아니라 코드 그래프다
- Authors

- Name
- Kyunghyun Park
- @devkhpark
핵심 키워드: Codebase-Memory MCP · 코드 지식 그래프 · 코딩 에이전트 운영 비용
코딩 에이전트의 병목을 아직도 “모델이 코드를 덜 이해한다”로만 보면 절반만 본 것이다. 실제로 Claude Code, Codex, Cursor, OpenCode 같은 도구를 오래 돌려보면 더 자주 터지는 문제는 모델 지능보다 코드베이스 탐색 방식이다. 에이전트는 파일을 열고, grep하고, 다시 파일을 열고, 호출 관계를 추측하고, 중간에 토큰을 태운다. 컨텍스트 창이 커져도 이 습관이 그대로면 비용과 지연은 계속 남는다.

2026년 6월 21일 GitHub Trending에서 다시 포착된 DeusData/codebase-memory-mcp는 이 문제를 정면으로 건드린다. README의 포지셔닝은 공격적이다. 평균 저장소를 밀리초 단위로 전체 인덱싱하고, Linux kernel 일부 규모는 3분 안에 처리하며, 구조 질의는 1ms 미만으로 답한다는 식이다. 더 중요한 문장은 따로 있다. 이 프로젝트는 코드를 단순 텍스트 더미가 아니라 함수, 클래스, 호출 체인, HTTP route, cross-service link가 들어 있는 persistent knowledge graph로 만들고, 그 위를 MCP 도구로 질의하게 한다.
이 글의 결론부터 말하면, Codebase-Memory MCP는 “코드 검색 툴 하나 더”가 아니다. 더 정확한 해석은 코딩 에이전트가 파일 시스템을 헤매지 않도록 코드베이스 탐색을 구조화된 질의 문제로 바꾸는 실행면 계층이다.
왜 지금 중요한가: 코딩 에이전트는 파일 탐색으로 너무 많은 토큰을 낭비한다
Codebase-Memory의 arXiv 초록은 문제를 꽤 직설적으로 정의한다. LLM 코딩 에이전트는 보통 repeated file-reading과 grep-searching으로 코드베이스를 탐색하고, 구조적 이해 없이 쿼리 하나마다 수천 토큰을 소비한다. 이 설명은 실제 팀 운영과 잘 맞다.
에이전트가 “이 함수는 어디서 호출돼?”라고 물을 때, 현재 많은 도구는 여전히 다음 흐름에 가깝다.
- 파일명이나 심볼명을 검색한다.
- 후보 파일을 여러 개 읽는다.
- import와 타입을 추측한다.
- 호출자를 다시 검색한다.
- 다른 언어, 프레임워크, generated code, monorepo 경계에서 다시 헤맨다.
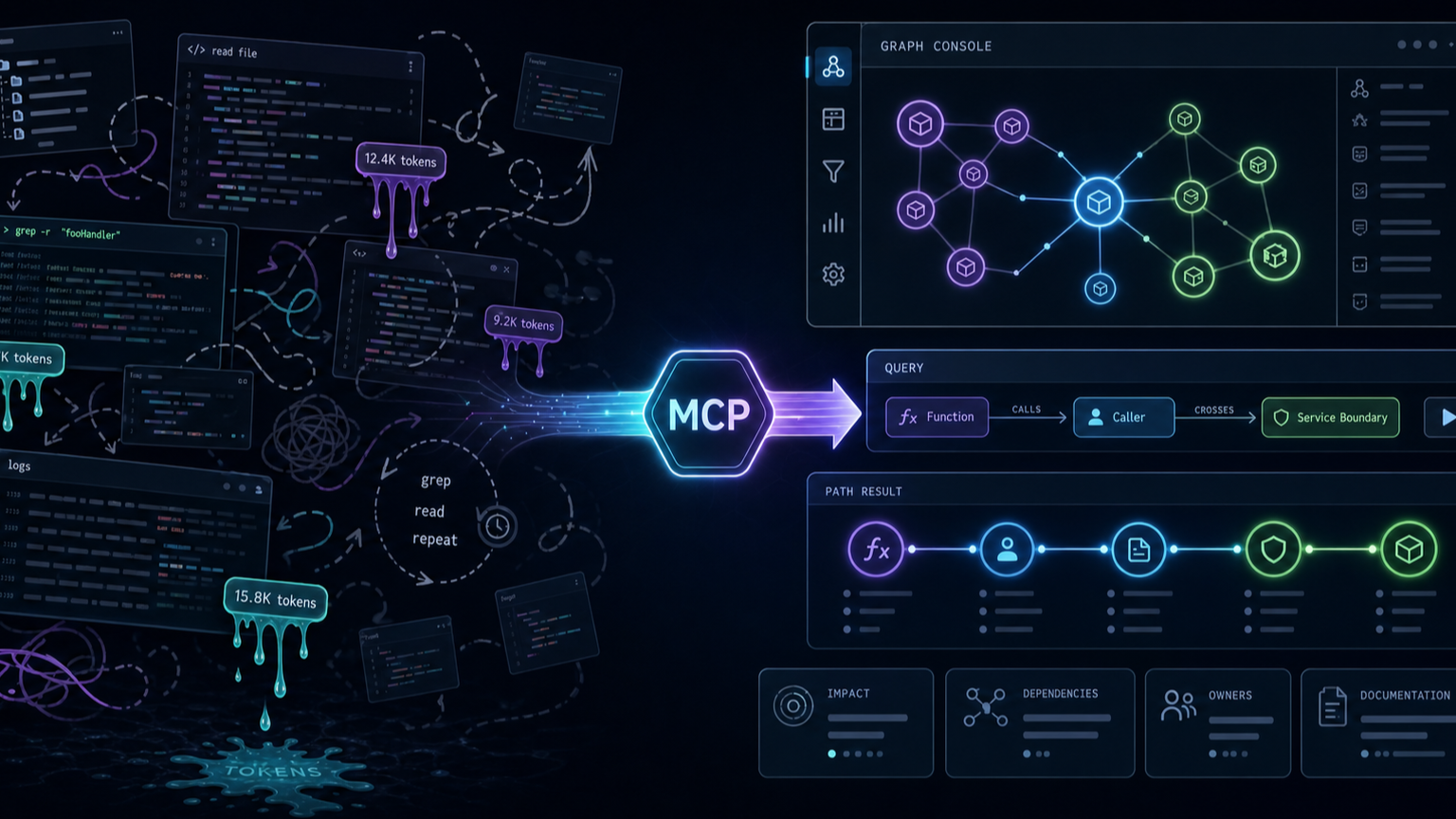
이 방식의 문제는 단순히 느리다는 데 있지 않다. 토큰을 많이 쓰는 것보다 더 나쁜 건 탐색이 비결정적이라는 점이다. 같은 질문도 어떤 파일을 먼저 열었는지, 어느 grep 결과를 택했는지에 따라 답이 달라진다. 에이전트가 코드를 수정할 때 이 비결정성은 품질 리스크가 된다.
그래서 Codebase-Memory가 흥미로운 지점은 “검색이 빠르다”보다 “탐색 단위를 바꾼다”에 있다. 파일 단위 탐색을 심볼·관계·경로 질의로 바꾸면, 에이전트는 다음 질문을 더 직접적으로 던질 수 있다.
- 이 함수의 inbound/outbound call path는 무엇인가?
- 이 HTTP route는 어느 service boundary와 연결되는가?
- 특정 클래스나 타입의 구현체는 어디에 있는가?
- 변경 영향도가 큰 hub function은 무엇인가?
- 이 기능을 이해하려면 어떤 커뮤니티나 모듈부터 봐야 하는가?
이건 RAG와도 다르다. 임베딩 검색은 “비슷한 텍스트”를 잘 찾는다. 반면 코드 변경에는 “정확한 관계”가 필요하다. call graph, inheritance, import, route, type relation 같은 구조는 벡터 검색만으로는 안정적으로 다루기 어렵다.
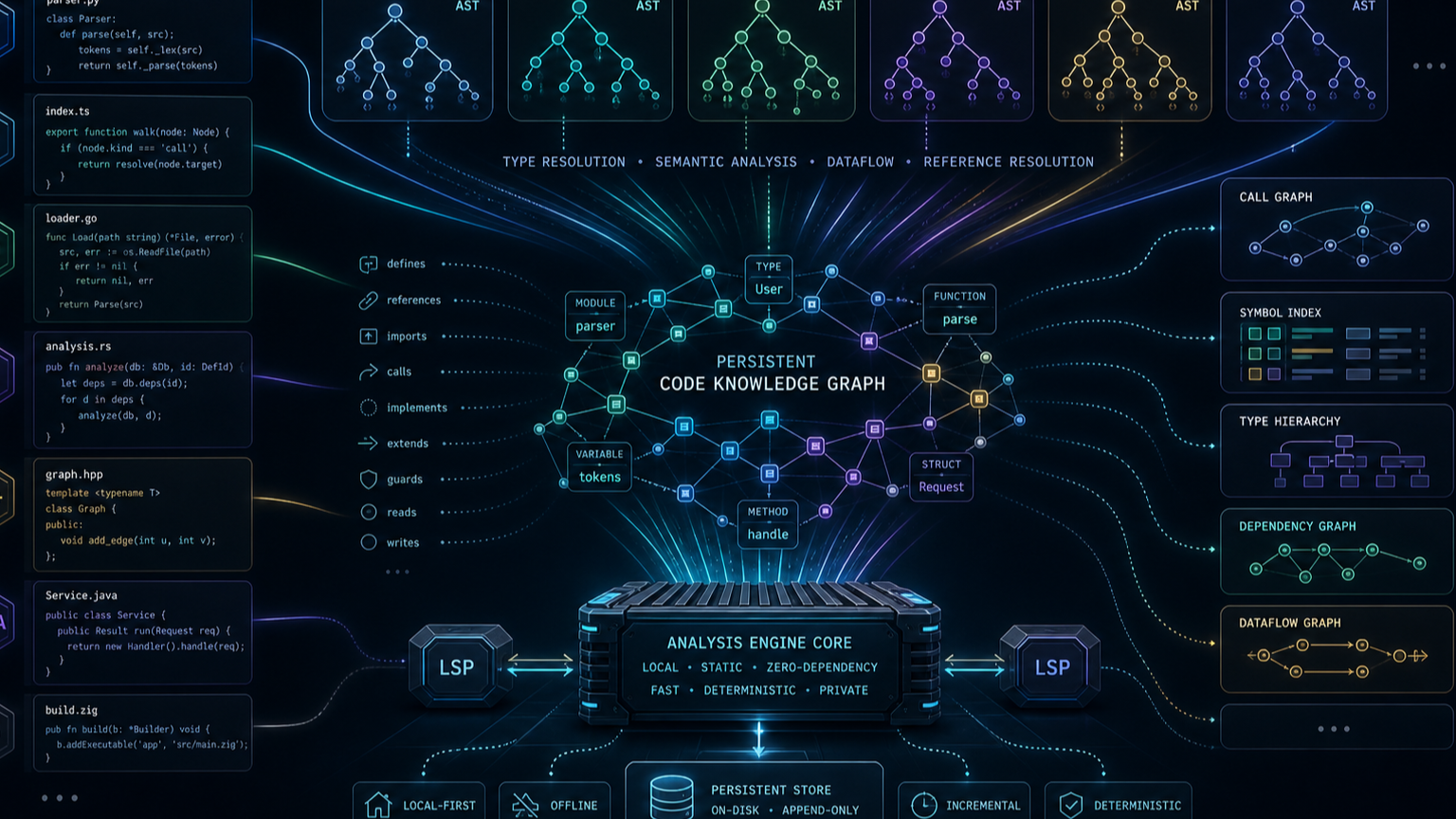
핵심 구조: Tree-sitter AST에 LSP 의미 정보를 얹고 MCP로 노출한다
README 기준으로 Codebase-Memory MCP의 기술적 축은 세 가지다.
첫째, tree-sitter 기반 AST 분석이다. README는 158개 언어를 AST로 파싱한다고 설명한다. arXiv 초록은 논문 시점에는 66개 언어를 기준으로 소개한다. 숫자가 다른 건 프로젝트가 빠르게 확장되는 중이라는 뜻으로 읽는 편이 안전하다. 중요한 건 언어 수 자체보다 “텍스트 검색이 아니라 구문 구조를 먼저 만든다”는 방향이다.
둘째, Hybrid LSP다. README는 Python, TypeScript/JavaScript/JSX/TSX, PHP, C#, Go, C, C++, Java, Kotlin, Rust 같은 주요 언어에서 LSP 기반 semantic type resolution을 더한다고 설명한다. AST만으로는 문법 구조는 알 수 있어도 실제 타입, cross-file symbol, 동적 호출의 일부를 놓칠 수 있다. LSP를 붙이는 이유는 여기에 있다.
셋째, MCP 도구화다. 프로젝트는 14개의 MCP tools를 제공한다고 설명한다. 이게 중요하다. 그래프가 있어도 에이전트가 자연스럽게 쓸 수 없으면 운영 계층이 되지 못한다. MCP로 노출되면 Claude Code, Codex, Cursor, OpenCode 같은 호스트가 “파일 읽기” 대신 “그래프 질의”를 도구 호출로 선택할 수 있다.
여기서 제품적으로 눈여겨볼 부분은 설치 형태다. GitHub API 기준 이 저장소는 C가 주 언어이고, README는 single static binary, zero dependencies, macOS/Linux/Windows 지원을 강조한다. 이는 단순한 구현 취향이 아니다. 코드 인덱서는 조직의 소스코드를 읽는다. “서버 하나 더 띄우고, 데이터베이스 붙이고, SaaS에 코드 보내는” 방식이면 도입 저항이 커진다. 로컬 정적 바이너리라는 포지션은 보안·배포·운영 측면에서 꽤 실용적이다.
수치가 말하는 것: 완벽한 답변보다 토큰 경제성이 더 큰 메시지다
README와 arXiv 초록이 반복해서 내세우는 벤치마크는 이렇다.
- 31개 real-world repositories 평가
- answer quality 83%
- file-by-file exploration agent 대비 10× fewer tokens
- 2.1× fewer tool calls
- graph-native query에서는 31개 언어 중 19개에서 explorer와 같거나 더 나은 결과
이 수치를 읽을 때 조심할 점이 있다. 83% 품질은 92%로 제시된 파일 탐색 에이전트보다 낮다. 즉 “그래프가 무조건 더 정확하다”는 주장이 아니다. 하지만 운영 관점에서는 이 차이가 오히려 현실적이다. 모든 질문에 대해 그래프가 완벽한 대체재가 되기는 어렵다. 대신 그래프는 반복되는 구조 질의에서 토큰과 tool call을 크게 줄인다.
실무적으로 더 중요한 해석은 다음이다.
| 질문 유형 | 파일 탐색 방식 | 코드 그래프 방식 |
|---|---|---|
| 심볼 위치 찾기 | grep 후보를 많이 읽음 | 정의/노드 질의 |
| 호출자·피호출자 추적 | 검색 → 파일 읽기 반복 | call edge traversal |
| 변경 영향도 | 사람이 경로를 추측 | graph neighborhood / hub 분석 |
| 대형 monorepo 이해 | 토큰과 시간 급증 | 인덱스 후 구조 질의 반복 |
| 코드 리뷰 보조 | 근거 파일 누락 가능 | 관련 관계를 먼저 좁힌 뒤 읽기 |
다시 말해 Codebase-Memory MCP의 가치는 “모델이 더 똑똑해진다”가 아니라 에이전트가 코드베이스를 둘러보는 비용 함수가 바뀐다에 있다. 매번 원문을 읽는 대신, 먼저 구조를 질의하고 필요한 부분만 읽게 만들 수 있다.
MCP라는 배포면이 중요하다: 코드 인덱스가 에이전트의 공용 감각기관이 된다
MCP가 단순 플러그인 포맷처럼 보일 때가 있지만, 이런 도구에서는 의미가 더 크다. 코드 지식 그래프가 MCP 서버로 제공되면, 각 에이전트가 자체적으로 매번 인덱싱 로직을 구현할 필요가 없다. 하나의 로컬 서버가 공용 감각기관처럼 작동할 수 있다.
예를 들어 팀이 다음과 같은 흐름을 만들 수 있다.
- 저장소 checkout 후 Codebase-Memory가 로컬 그래프를 만든다.
- Claude Code나 Codex는 MCP를 통해 구조 질의를 한다.
- 에이전트는 그래프 결과로 후보 범위를 좁힌다.
- 마지막에 필요한 파일만 읽고 수정한다.
- 리뷰나 테스트 실패가 나오면 다시 그래프로 영향 범위를 확인한다.
이 구조는 최근의 agent tooling 흐름과도 맞물린다. Headroom은 에이전트 입력을 압축하고, LMCache류는 inference의 반복 비용을 줄이고, code graph 계열 도구는 탐색 비용을 줄인다. 공통점은 하나다. 에이전트 시대의 경쟁은 모델 호출 자체보다 호출 전후의 운영 계층에서 벌어진다.
실무 도입 포인트: 바로 믿기보다 “탐색 전처리 계층”으로 시험해야 한다
그렇다고 곧바로 모든 코딩 에이전트 작업을 Codebase-Memory 위에 올리라는 뜻은 아니다. 코드 인텔리전스 도구는 틀리면 꽤 위험하다. 특히 AST/LSP 기반 그래프는 언어별 parser 품질, generated code, dynamic dispatch, framework convention, monorepo 경계에서 빈틈이 생길 수 있다.

그래서 실제 도입은 아래처럼 좁게 시작하는 편이 낫다.
1) “찾기” 작업부터 붙인다
처음부터 자동 수정까지 맡기기보다, 정의 찾기, 호출자 찾기, route-to-handler 찾기, impact surface 추정 같은 읽기 중심 작업에 붙이는 게 안전하다. 그래프가 틀려도 사람이 확인하기 쉽고, 토큰 절감 효과도 빨리 보인다.
2) 그래프 결과 뒤에는 반드시 원문 확인을 남긴다
그래프는 후보를 좁히는 데 강하다. 하지만 최종 수정 근거는 여전히 원문 코드, 테스트, 타입체크, 런타임 검증에서 나와야 한다. 좋은 패턴은 “그래프 질의 → 관련 파일 read → 수정 → 테스트”다. 그래프만 보고 수정하면, 오래된 인덱스나 누락 edge가 사고를 만들 수 있다.
3) 보안 모델을 먼저 정한다
README도 솔직하게 적는다. 이 도구는 코드베이스를 읽고 에이전트 설정 파일에 쓴다. 그게 설계 목적이다. 따라서 팀 환경에서는 다음을 확인해야 한다.
- 바이너리 출처와 checksum 검증
- 로컬 처리 여부와 네트워크 호출 범위
- 인덱스 파일 저장 위치와 삭제 정책
- MCP 서버가 노출하는 도구 권한
- CI/개발자 장비에서의 버전 고정 방식
이런 질문 없이 “토큰 10배 절약”만 보고 붙이면 안 된다. 코드 인덱스는 사실상 내부 아키텍처 지도다. 편해질수록 권한과 감사가 더 중요해진다.
SEO 관점에서 보면, 이 주제의 검색 의도는 “MCP 서버 추천”보다 넓다
한국 개발자들이 이 주제를 검색할 때 꼭 Codebase-Memory MCP라는 이름으로만 찾지는 않을 가능성이 높다. 더 넓은 검색 의도는 다음에 가깝다.
- 코딩 에이전트가 대형 코드베이스를 잘 이해하게 하는 방법
- Claude Code / Codex / Cursor에서 코드 검색 비용을 줄이는 방법
- MCP code intelligence server란 무엇인가
- Tree-sitter 기반 code graph가 RAG보다 나은 경우
- monorepo에서 AI coding agent를 실무에 붙이는 방법
그래서 이 프로젝트를 볼 때도 저장소 하나의 유행보다 큰 흐름을 봐야 한다. 코딩 에이전트가 장난감에서 운영 도구로 넘어가려면, 세 가지 기반이 필요하다.
- 관측성 — 에이전트가 무엇을 읽고 비용을 썼는지 추적한다.
- 맥락 관리 — 필요 없는 입력을 줄이고 필요한 근거를 회수한다.
- 구조적 코드 이해 — 파일 더미가 아니라 관계 그래프로 코드베이스를 본다.
Codebase-Memory MCP는 이 중 세 번째 축에 있는 도구다.
결론: 큰 컨텍스트 창보다 좋은 코드 지도
Codebase-Memory MCP가 보여주는 방향은 분명하다. 코딩 에이전트의 성능을 올리는 방법은 모델을 더 크게 만드는 것만이 아니다. 에이전트가 읽는 세계를 더 구조화하는 것도 같은 만큼 중요하다.
컨텍스트 창은 계속 커질 것이다. 하지만 큰 창은 잘못된 탐색 습관을 자동으로 고쳐주지 않는다. 대형 코드베이스에서는 “모든 것을 더 많이 읽기”보다 “무엇을 읽어야 하는지 먼저 아는 것”이 더 중요하다. Codebase-Memory MCP의 핵심 메시지는 바로 여기에 있다.
앞으로 코딩 에이전트 운영의 차이는 모델 선택만이 아니라, 코드베이스를 어떤 지도 형태로 제공하느냐에서 갈릴 가능성이 높다.