- Published on
OpenMOSS MOSS-TTS: 오픈소스 음성 AI가 TTS 데모를 넘어 오디오 런타임이 되는 신호
- Authors

- Name
- Kyunghyun Park
- @devkhpark
OpenMOSS · MOSS-TTS v1.5 · MOSS-SoundEffect v2.0 · 오픈소스 오디오 AI
OpenMOSS의 MOSS-TTS가 2026년 5월 29일 GitHub Trending에 올라온 건 단순한 스타 수 이벤트로만 보기 어렵다. 더 중요한 신호는 5월 26일에 함께 공개된 두 축이다. 하나는 MOSS-TTS-v1.5, 다른 하나는 MOSS-SoundEffect-v2.0이다.
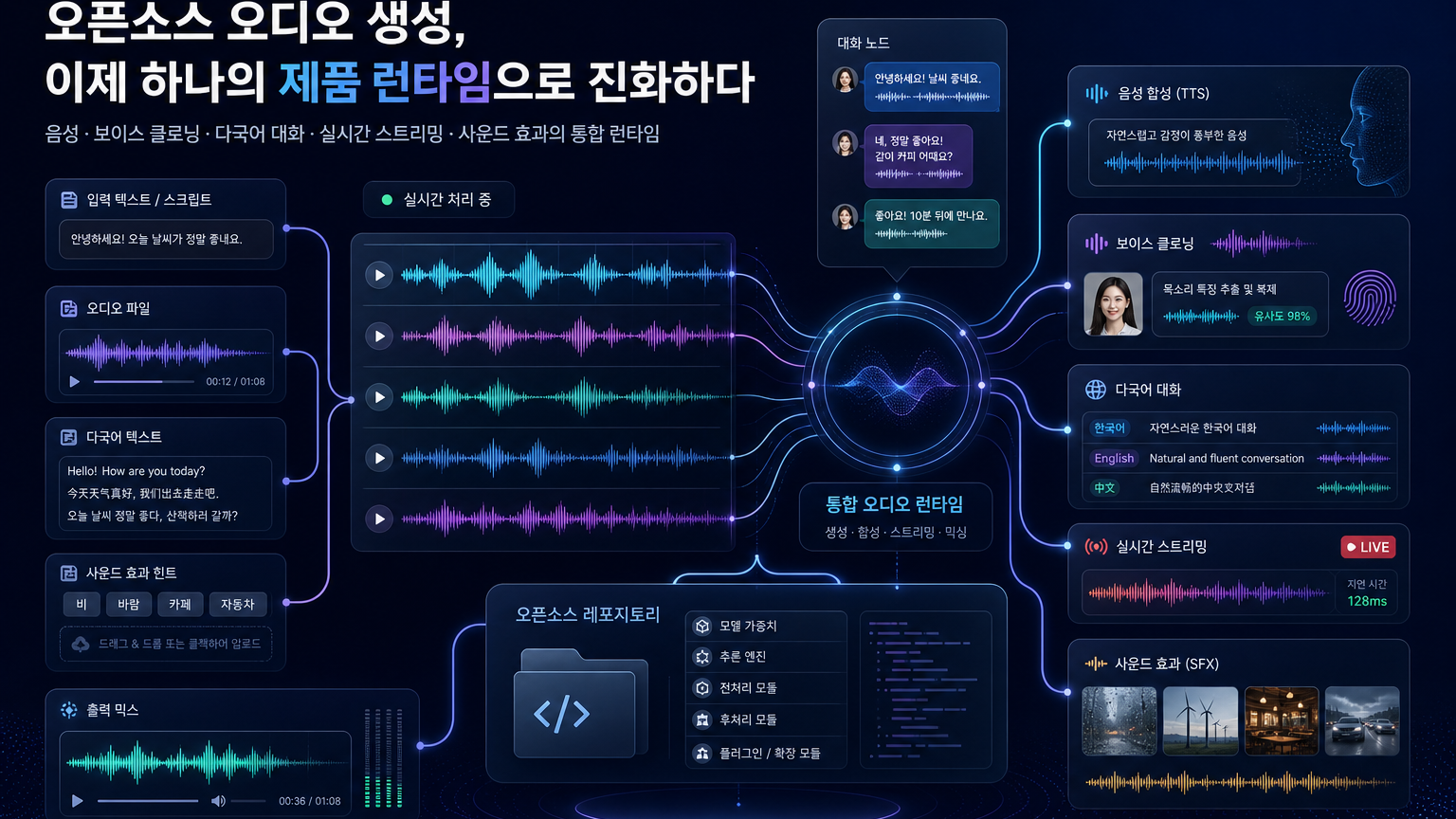
이 글의 결론부터 말하면 이렇다. 오픈소스 음성 AI의 경쟁축은 “말을 자연스럽게 읽어주는 모델”에서 “제품 안에서 음성·효과음·실시간 스트리밍을 운영할 수 있는 오디오 런타임”으로 이동하고 있다. MOSS-TTS는 이 변화를 꽤 노골적으로 보여준다. README는 이 프로젝트를 speech and sound generation model family라고 부르고, 안정적인 장문 음성, 다중 화자 대화, voice/character design, 환경음, 실시간 TTS까지 범위에 넣는다.
기준 시점: 이 글은 2026-05-29에 확인한 OpenMOSS GitHub README, Hugging Face 모델 카드, arXiv 기술 보고서 기준이다. 실제 제품 적용 전 라이선스, 의존성, 모델 파일, 추론 비용, 음성 권리 이슈는 다시 확인해야 한다.
왜 지금 볼 만한가: TTS 하나가 아니라 “오디오 제품 표면”을 묶고 있다
MOSS-TTS의 최신 README에서 눈에 띄는 대목은 2026년 5월 26일 업데이트다. 프로젝트는 같은 날 두 가지를 공개했다.
- MOSS-TTS v1.5: 다국어 합성, voice cloning 안정성, 장문 reference 기반 짧은 문장 cloning, 문장부호 기반 prosody,
[pause X.Ys]형태의 명시적 pause 제어를 개선했다고 설명한다. - MOSS-SoundEffect v2.0: DiT backbone과 Flow Matching objective를 사용하는 text-to-audio 모델로, 48kHz 양방향(영어/중국어) 효과음을 최대 30초까지 생성한다고 설명한다.
이 조합이 중요한 이유는 단순하다. 제품에서 음성 AI를 붙일 때 필요한 것은 “문장을 읽어주는 함수” 하나가 아니다. 실제로는 다음 표면들이 같이 필요하다.
- 사용자에게 말하는 TTS
- 캐릭터·브랜드·화자 정체성을 유지하는 voice cloning
- 다국어 또는 code-switching 처리
- 대화 중 pause, 억양, 문장부호를 따르는 prosody
- 환경음·UI 사운드·상황음 같은 non-speech audio
- 실시간 스트리밍과 낮은 time-to-first-audio
MOSS-TTS 패밀리는 이 표면들을 한 저장소와 모델 카드 생태계 안에 모으려 한다. 그래서 이 프로젝트를 “무료 TTS 모델” 정도로 보면 핵심을 놓친다. 더 정확한 해석은 오픈소스 오디오 기능을 제품 런타임으로 패키징하려는 시도다.
MOSS-TTS v1.5의 핵심은 품질보다 제어 가능성이다

MOSS-TTS-v1.5 모델 카드는 v1.0의 핵심 기능을 유지한다고 적는다. zero-shot voice cloning, long-form speech generation, token-level duration control, Pinyin/IPA pronunciation control, multilingual synthesis, code-switching이 그 축이다. v1.5는 여기에 “운영 품질” 쪽 개선을 붙인다.
특히 개발자 입장에서 중요한 건 세 가지다.
첫째, language tag를 명시했을 때 다국어 합성이 더 강해진다는 설명이다. 모델 카드 기준 v1.5는 31개 언어를 지원하고, 한국어도 목록에 들어 있다. 한국 개발팀이 영어·한국어·일본어·중국어가 섞인 제품을 만든다면, 이건 단순한 지원 언어 수보다 운영상 의미가 크다. 모델이 자동 추론으로 언어를 맞히길 기대하는 대신, 애플리케이션 레이어에서 language 필드를 명시하는 식으로 실패율을 낮출 수 있기 때문이다.
둘째, voice cloning variance를 줄였다는 점이다. 음성 복제 기능은 데모에서는 한 번 잘 나오면 충분해 보인다. 하지만 제품에서는 같은 캐릭터가 여러 문장을 반복 생성할 때 톤이 흔들리지 않아야 한다. 고객 응대, 교육 콘텐츠, 게임 캐릭터, 오디오북처럼 누적 청취 시간이 긴 환경에서는 speaker similarity의 평균보다 분산이 더 중요할 때가 많다.
셋째, pause 제어와 punctuation-following prosody다. [pause 3.2s] 같은 inline marker를 지원한다는 건 작아 보이지만, 실제 콘텐츠 제작에서는 꽤 크다. 음성 UX는 텍스트 UX와 다르다. 쉼표 하나, 1초의 침묵, 문장 끝의 호흡이 사용자의 이해 속도를 바꾼다. 자연스러움은 모델 내부의 “감”만으로 해결되는 게 아니라, 제작자가 필요한 지점에 제어권을 넣을 수 있어야 안정된다.
MOSS-SoundEffect v2.0은 TTS 저장소를 오디오 생성 플랫폼처럼 보이게 만든다

이번 업데이트에서 더 흥미로운 쪽은 오히려 MOSS-SoundEffect-v2.0일 수 있다. 모델 카드는 이 모델을 Diffusion Transformer backbone과 Flow Matching objective를 쓰는 text-to-audio 모델이라고 설명한다. DAC VAE와 Qwen3 text encoder를 함께 사용하고, 자연어 프롬프트에서 환경음, 도시 소리, 생물·크리처, 사람 행동, 짧은 음악적·타악기적 클립까지 생성하는 방향이다.
여기서 포인트는 “효과음도 만든다”가 아니다. 제품 관점에서는 speech와 sound effect가 같은 오디오 경험 안에 있다. 예를 들어 다음 제품을 생각해보자.
- AI 튜터: 설명 음성, 정답 피드백 사운드, 집중을 돕는 배경음
- 게임 NPC: 캐릭터 음성, 발소리, 문 여는 소리, 몬스터 반응음
- 숏폼 제작 도구: 내레이션, 전환 효과음, 상황음, 짧은 배경 루프
- 콜센터 시뮬레이터: 상담원 음성, 통화 환경음, 대기음, 알림음
기존에는 이런 구성요소가 서로 다른 API와 라이선스, 품질 관리 체계로 갈라졌다. TTS는 A 서비스, 효과음은 B 라이브러리, 배경음은 C 스톡 사이트, 실시간 처리는 또 다른 인프라로 붙는 식이다. MOSS-TTS 패밀리의 방향은 이 경계를 흐린다. 완성도와 배포 편의성은 별도로 검증해야 하지만, 오픈 모델 생태계가 speech-only가 아니라 product audio stack으로 확장되고 있다는 신호는 분명하다.
기술 보고서가 말하는 구조: 토크나이저, 자기회귀, 장문 제어
arXiv 기술 보고서는 MOSS-TTS를 “discrete audio tokens, autoregressive modeling, large-scale pretraining” 위에 세운 speech generation foundation model로 설명한다. 핵심 부품은 MOSS-Audio-Tokenizer다. 보고서 초록에 따르면 이 토크나이저는 24kHz 오디오를 12.5fps로 압축하고, variable-bitrate RVQ와 semantic-acoustic representation을 사용한다.
이 설명에서 실무적으로 읽어야 할 것은 두 가지다.
첫째, 오디오 모델도 점점 LLM식 제품 설계 언어로 해석된다. 텍스트 토큰 대신 오디오 토큰을 다루고, 제어 가능한 생성과 장문 안정성을 이야기한다. 이건 개발자가 음성을 “파일 출력”이 아니라 “모델이 생성하는 시퀀스”로 다루게 만든다.
둘째, 장문과 실시간은 서로 다른 최적화 문제다. 기술 보고서는 MOSS-TTS와 MOSS-TTS-Local-Transformer를 구분한다. 전자는 구조적 단순성, 확장성, long-context/control-oriented deployment에 초점을 두고, 후자는 frame-local autoregressive module로 모델링 효율과 speaker preservation, shorter time to first audio를 노린다고 설명한다. 즉 하나의 “최고 모델”보다, 제품 요구에 따라 다른 아키텍처와 추론 경로를 고르는 방향에 가깝다.
실무 해석: 음성 AI 도입 질문이 바뀐다
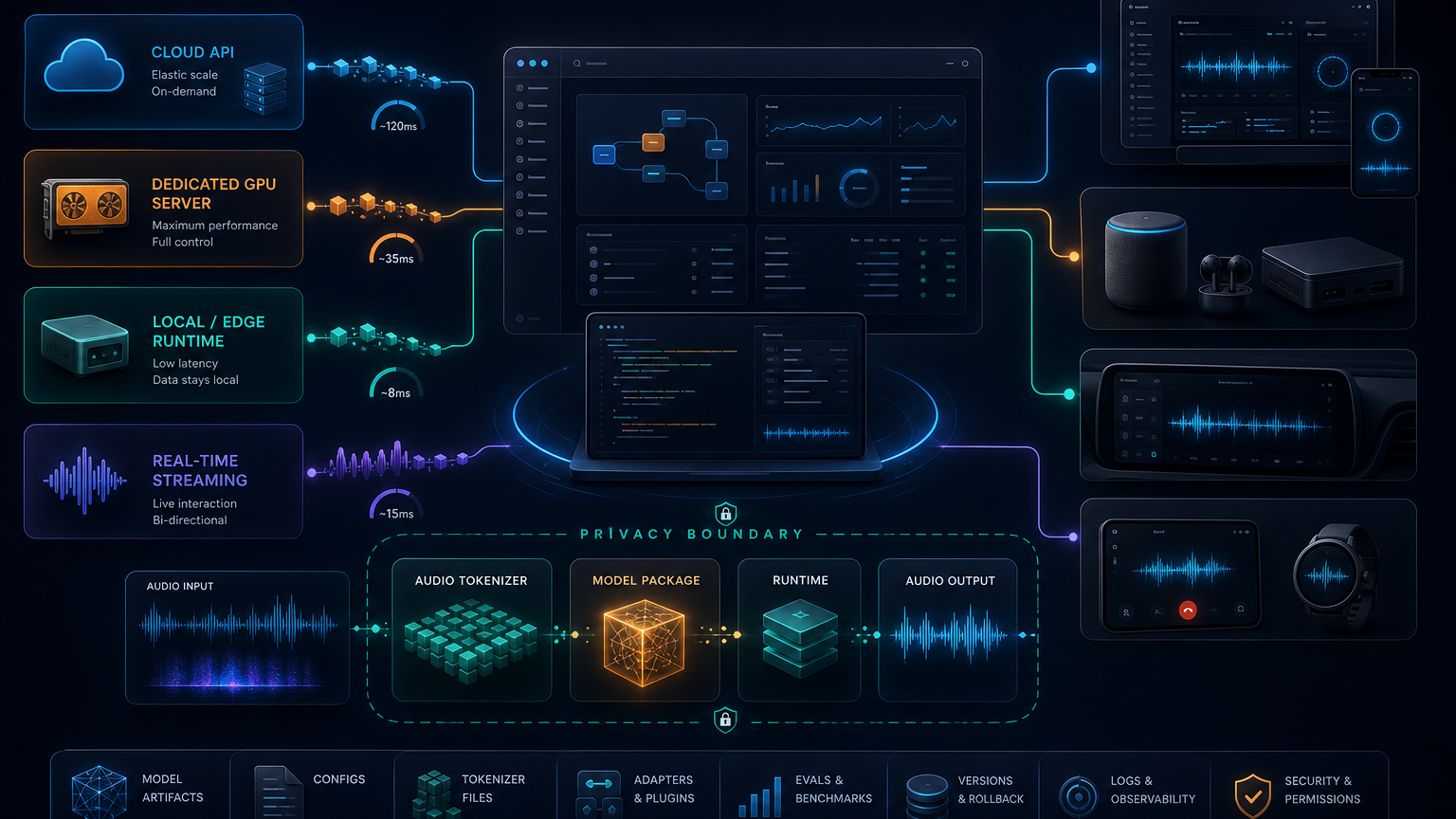
한국 개발팀이 이 업데이트를 볼 때 바로 “MOSS-TTS를 프로덕션에 넣자”로 결론낼 필요는 없다. 오히려 더 중요한 건 질문의 프레임이다. 앞으로 음성 AI를 고를 때는 아래 질문을 먼저 던져야 한다.
1. 우리는 TTS가 필요한가, 오디오 런타임이 필요한가?
단순 안내 문장을 읽어주는 정도라면 상용 TTS API가 여전히 가장 빠르다. 하지만 캐릭터, 다국어, 장문 콘텐츠, 효과음, 실시간 인터랙션이 같이 필요하다면 TTS API 하나로는 부족하다. 이때는 모델보다 파이프라인을 봐야 한다. 어떤 입력 스키마로 언어·화자·pause를 제어할 수 있는지, 효과음과 내레이션을 같은 제작 플로우로 묶을 수 있는지가 중요해진다.
2. 제어권을 모델에 맡길 것인가, 애플리케이션 레이어에 둘 것인가?
MOSS-TTS v1.5의 language tag와 pause marker는 좋은 힌트다. 좋은 음성 UX는 모델이 알아서 자연스럽게 말하는 것만으로 끝나지 않는다. 제품은 언제 침묵해야 하는지, 어떤 언어로 읽어야 하는지, 어느 단어를 어떻게 발음해야 하는지, 사용자가 끼어들 때 어디서 멈춰야 하는지를 알아야 한다. 즉 음성 합성은 프롬프트 엔지니어링이 아니라 상태와 제어 정책의 문제가 된다.
3. 오픈소스 모델의 장점은 비용이 아니라 운영 독립성이다
오픈소스 TTS를 “API 비용 절감”으로만 보면 과소평가다. 진짜 장점은 제품이 특정 공급자의 가격·지역·정책·데이터 반출 조건에 덜 묶인다는 점이다. 반대로 그만큼 모델 서빙, GPU 메모리, 지연시간, 업데이트, abuse 방지, 음성 권리 관리 같은 책임은 개발팀 쪽으로 온다. Apache-2.0 라이선스라도 생성 음성의 권리와 reference audio 동의 문제는 별개다.
4. 실시간 음성 에이전트에서는 TTS만 빨라서는 부족하다
OpenMOSS README에는 real-time streaming TTS와 MOSS-TTS-Nano, llama.cpp, ONNX Runtime 같은 배포 관련 신호가 반복해서 나온다. 이건 음성 에이전트에서 매우 중요하다. 사용자는 텍스트 응답처럼 몇 초를 기다리지 않는다. 음성에서는 time-to-first-audio, interrupt, turn-taking, partial generation, silence handling이 UX를 좌우한다. 모델 품질이 좋아도 이 운영 표면이 약하면 제품은 답답하게 느껴진다.
검색 의도 관점: “오픈소스 TTS”보다 “음성 AI 제품화” 키워드가 중요해진다
한국어 검색에서 오픈소스 TTS, 음성 합성 모델, voice cloning, 텍스트 음성 변환 같은 키워드는 이미 존재한다. 하지만 앞으로 실무자가 더 많이 찾게 될 질문은 조금 다를 가능성이 높다.
- 오픈소스 TTS를 제품에 넣을 때 지연시간은 어떻게 줄이나?
- 한국어와 영어가 섞인 음성 합성에서 언어 태그를 어떻게 관리하나?
- voice cloning을 서비스에 넣을 때 동의와 워터마킹은 어떻게 처리하나?
- 효과음 생성 모델을 콘텐츠 제작 파이프라인에 어떻게 붙이나?
- cloud TTS API와 self-hosted audio model의 운영 비용은 어떻게 비교하나?
MOSS-TTS v1.5와 MOSS-SoundEffect v2.0은 이 검색 의도에 잘 맞는다. 모델이 “좋다/나쁘다”보다, 오픈소스 오디오 AI가 실제 제품 운영 질문으로 들어오고 있다는 점이 핵심이다.
결론: MOSS-TTS는 음성 합성 모델보다 “오디오 AI 스택”에 가깝다
MOSS-TTS를 오늘 바로 상용 서비스의 기본 음성 엔진으로 채택해야 한다는 뜻은 아니다. 성능, 한국어 품질, 지연시간, 하드웨어 요구사항, 데이터 권리, 안전장치, 운영 자동화는 각 팀이 직접 검증해야 한다. 특히 voice cloning은 기술보다 정책과 동의 설계가 더 어려울 수 있다.
그럼에도 이번 업데이트는 볼 만하다. MOSS-TTS v1.5는 다국어·voice cloning·pause/prosody 제어를 강화했고, MOSS-SoundEffect v2.0은 TTS 저장소를 non-speech audio 생성까지 확장했다. 여기에 실시간 TTS, local transformer, llama.cpp/ONNX 계열 배포 신호까지 더하면 그림이 선명해진다.
오픈소스 음성 AI는 이제 “문장을 읽는 모델”이 아니라, 제품 안에서 말하고 듣고 분위기를 만드는 오디오 런타임으로 내려오고 있다. MOSS-TTS는 그 전환을 관찰하기 좋은 사례다.