- Published on
ITBench-AA: AI 에이전트가 엔터프라이즈 SRE를 아직 자동화하지 못하는 이유
- Authors

- Name
- Kyunghyun Park
- @devkhpark
ITBench-AA · AI Agent Benchmark · Kubernetes SRE
AI 에이전트 시장의 최근 메시지는 대체로 낙관적이다. 코드를 고치고, 브라우저를 조작하고, 워크플로를 이어 붙이고, 운영팀의 반복 작업을 대신할 수 있다는 식이다. 그런데 2026년 5월 27일 공개된 ITBench-AA는 그 낙관론에 꽤 차가운 숫자를 던진다. frontier 모델조차 실제 엔터프라이즈 SRE류 장애 진단 벤치마크에서 50%를 넘기지 못했다.

이 글은 Artificial Analysis와 IBM Software Innovation Lab이 공개한 ITBench-AA 발표, Artificial Analysis 리더보드, IBM의 ITBench GitHub 저장소, 그리고 ITBench 논문을 바탕으로 정리했다. 결론부터 말하면, ITBench-AA의 의미는 “어떤 모델이 1등인가”보다 엔터프라이즈 에이전트 자동화가 아직 어디서 무너지는가에 있다.
ITBench-AA는 왜 중요한가: 채팅 능력이 아니라 사고 대응 능력을 본다
ITBench-AA는 Artificial Analysis와 IBM이 함께 만든 agentic enterprise IT 작업 벤치마크다. 첫 공개 범위는 SRE, 즉 Site Reliability Engineering 작업이다. 모델은 Kubernetes 사고 스냅샷을 받고, 로그·트레이스·메트릭·이벤트·애플리케이션 토폴로지를 살펴본 뒤, 장애를 일으킨 최소 root-cause Kubernetes entity를 찾아야 한다.
이 지점이 중요하다. 일반적인 에이전트 데모는 “터미널에서 몇 가지 명령을 실행했다” 또는 “로그를 요약했다” 수준에서 끝나기 쉽다. ITBench-AA는 훨씬 까다롭다. 모델이 최종적으로 제출해야 하는 것은 그럴듯한 설명이 아니라, ground truth와 비교 가능한 구조화된 root-cause entity 목록이다.
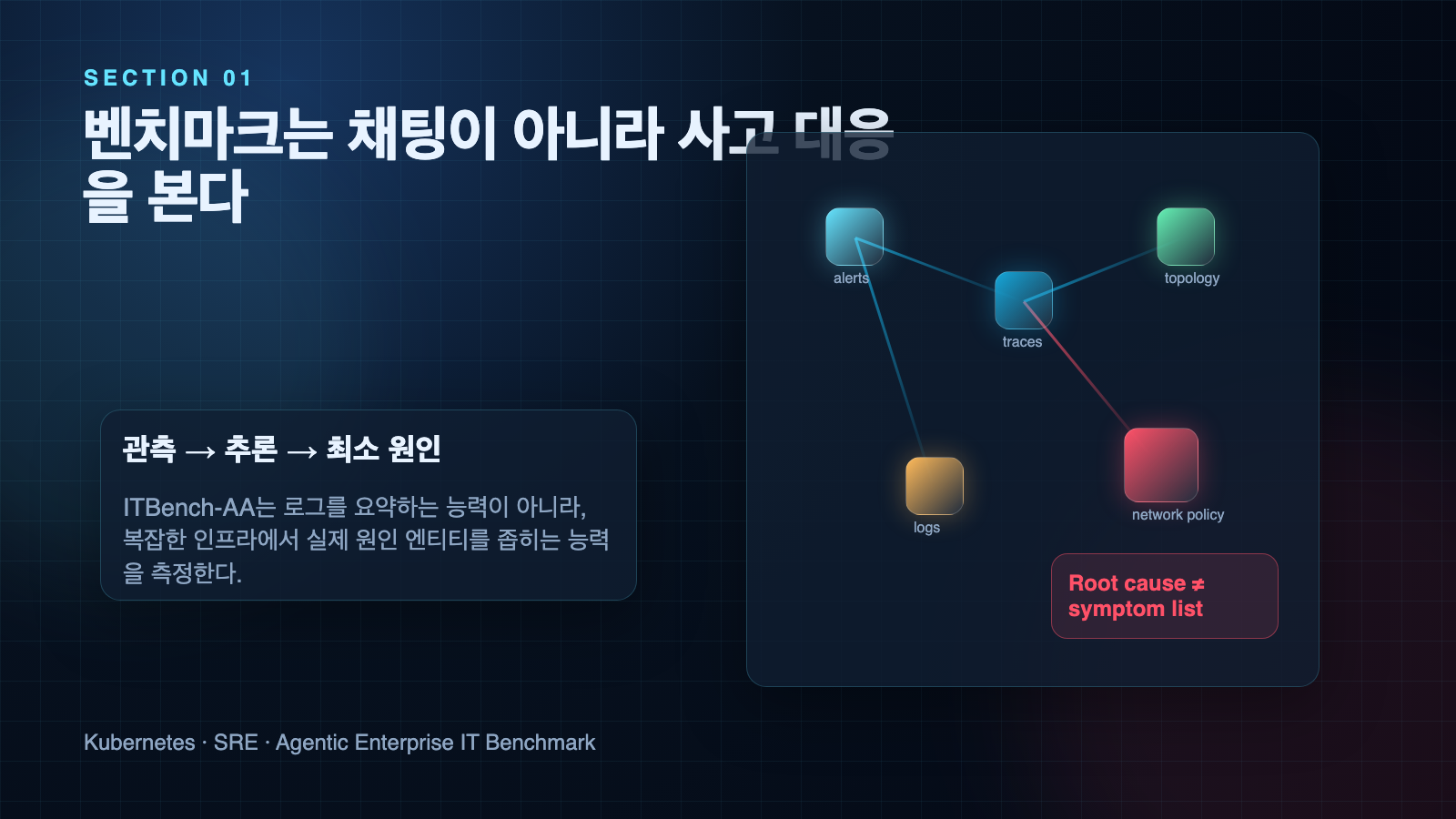
공개 글에 따르면 SRE 벤치마크는 총 59개 작업으로 구성된다. 이 중 40개는 public task이고, 19개는 새로 추가된 held-out task다. 각 작업은 Kubernetes incident snapshot을 제공하며, 모델은 shell access가 있는 sandboxed file system 안에서 관련 로그와 스냅샷을 조사한다. 100턴 제한, 작업당 3회 반복, 동일한 open-source Stirrup reference harness가 적용된다.
즉 이 벤치마크는 “AI가 운영 문서를 잘 읽는가”가 아니라 다음 질문을 묻는다.
- alerts, events, traces, metrics, logs를 종합해서 장애의 실제 원인을 좁힐 수 있는가?
- 증상과 원인을 구분할 수 있는가?
- Kubernetes Deployment, Service, Pod, NetworkPolicy 같은 entity 수준으로 정확히 지목할 수 있는가?
- 필요 이상으로 많은 후보를 제출하지 않고 최소 원인 집합을 맞힐 수 있는가?
이건 한국 개발자와 운영자에게 꽤 실무적인 신호다. 장애 대응 자동화는 “LLM에게 로그를 붙여넣고 물어보기”보다 훨씬 엄격한 문제다. 엔터프라이즈에서 필요한 것은 말이 되는 해설이 아니라, 실제 조치로 이어질 만큼 좁혀진 진단이다.
핵심 수치: 최고 모델도 47%, GPT-5.5도 46%
ITBench-AA 발표의 가장 큰 뉴스는 리더보드 수치다. 공개 글 기준 주요 결과는 이렇다.
| 모델 | ITBench-AA SRE 점수 |
|---|---|
| Claude Opus 4.7 (Adaptive Reasoning, Max Effort) | 47% |
| GPT-5.5 (xhigh) | 46% |
| Qwen3.7 Max | 42% |
| GLM-5.1 (Reasoning) | 40% |
| DeepSeek V4 Pro (Reasoning, Max Effort) | 38% |
| Gemma 4 31B (Reasoning) | 37% |
| Gemini 3.1 Pro Preview | 30% |
표면적으로는 Claude Opus 4.7이 1등이고, GPT-5.5가 근소하게 뒤따른다. 하지만 진짜 포인트는 순위가 아니다. 모든 frontier 모델이 50% 아래에 머물렀다는 점이다. Artificial Analysis는 ITBench-AA SRE를 자신들의 agentic benchmark suite에서 가장 덜 포화된 축 중 하나로 설명한다. Terminal-Bench 같은 다른 에이전트 벤치마크보다 frontier 모델 점수가 훨씬 낮다는 것이다.

이 수치가 불편한 이유는 명확하다. 지금 AI 에이전트 담론은 이미 “운영팀을 대체한다”, “SRE를 자동화한다”, “엔터프라이즈 업무를 end-to-end로 수행한다”는 방향으로 움직이고 있다. 그런데 실제 장애 스냅샷에서 root cause를 맞히는 문제로 들어가면, 최고 모델도 절반을 넘지 못한다.
이건 “모델이 별로다”라는 단순한 이야기가 아니다. 오히려 반대에 가깝다. 가장 강한 모델들조차 실패한다면, 문제는 모델 크기만으로 해결되는 단순 QA가 아니라는 뜻이다. SRE 자동화에는 관측 데이터, 토폴로지, 원인-증상 분리, 반복 조사 비용, 제출 형식, 안전한 조치 경계가 모두 얽혀 있다.
더 긴 추론이 항상 더 좋은 답을 만들지 않는다
ITBench-AA에서 특히 흥미로운 대목은 turn count다. 공개 글은 턴 수가 거의 3배까지 차이 나지만, 더 긴 trajectory가 더 높은 정확도로 이어지지 않는다고 지적한다. 예를 들어 GPT-5.5 (xhigh)는 작업당 평균 31턴으로 46%를 기록한 반면, Gemini 3.1 Pro Preview는 평균 83턴을 쓰고도 30%에 그쳤다.
이건 에이전트 운영 설계에서 꽤 중요한 교훈이다. 우리는 종종 “더 오래 생각하게 하면 좋아진다”, “더 많은 도구 호출을 허용하면 좋아진다”고 가정한다. 하지만 장애 진단에서는 과잉 조사가 오히려 false positive를 늘릴 수 있다. 모델이 실제 root cause뿐 아니라 upstream fault injection mechanism, co-occurring symptom, 주변 증상까지 제출하면 점수가 깎인다.
ITBench-AA의 scoring 방식은 이 문제를 잘 드러낸다. 모델이 ground-truth root cause를 하나라도 놓치면 해당 repeat는 0점이다. 모두 맞히면 precision, 즉 제출한 entity 중 실제 원인인 비율로 점수를 받는다. 그래서 정답을 포함했더라도 불필요한 후보를 잔뜩 붙이면 낮은 점수를 받는다.
실무적으로 번역하면 이렇다.
운영 자동화에서 좋은 에이전트는 “많이 조사하는 에이전트”가 아니라, 증상 후보를 줄이고 조치 가능한 최소 원인으로 수렴하는 에이전트다.
이 관점은 최근 에이전트 제품을 평가할 때도 유용하다. 단순히 tool call을 많이 한다거나, 긴 사고 과정을 보여준다거나, 로그를 많이 읽는다고 좋은 운영 에이전트가 되는 게 아니다. 실제로는 어느 시점에 멈추고, 어떤 원인을 제출하고, 어떤 불확실성을 남기는지가 더 중요하다.
오픈 웨이트 모델이 비용 전선에서 의외로 강하다
또 하나 눈에 띄는 지점은 비용이다. 공개 글은 open weights 모델들이 ITBench-AA SRE의 cost frontier에 있다고 설명한다. 예를 들어 Gemma 4 31B (Reasoning)는 37%를 기록하면서 작업당 비용이 0.14달러로 제시됐다. Gemini 3.1 Pro Preview는 30%에 작업당 2.23달러다. GLM-5.1 (Reasoning)은 40%에 1.23달러로, Gemini 3.5 Flash (high)와 비슷한 점수를 더 낮은 비용으로 낸다. 반면 Claude Opus 4.7은 47%로 선두지만 작업당 5.38달러로 가장 비싸다.

이건 한국의 스타트업, SaaS 팀, 내부 플랫폼 팀이 특히 봐야 할 부분이다. SRE 자동화는 한 번 멋지게 성공하는 데모보다 반복 실행 비용이 중요하다. 장애, 알림, 배포 검증, 로그 분석은 하루에도 여러 번 발생할 수 있다. 모델 하나의 최고점만 보고 선택하면 운영비가 금방 커진다.
따라서 실무 평가 질문은 다음처럼 바뀌어야 한다.
- 우리 인프라의 실제 장애 유형에서 어느 모델이 가장 잘 맞히는가?
- 평균 turn count와 latency는 어느 정도인가?
- 모델이 과잉 진단을 자주 하는가, 아니면 최소 원인으로 잘 수렴하는가?
- 장애당 비용을 감당할 수 있는가?
- 저비용 모델을 1차 triage에 쓰고, 고성능 모델을 escalation에 쓰는 구조가 가능한가?
즉 ITBench-AA가 보여주는 방향은 “가장 똑똑한 모델 하나를 고르자”가 아니다. 운영 자동화는 model routing, confidence gating, escalation policy, cost budget이 함께 설계되어야 한다는 쪽에 가깝다.
IBM의 원래 ITBench가 깔아둔 문제의식
이번 ITBench-AA는 IBM의 기존 ITBench 위에 올라간다. IBM의 ITBench 논문은 AI 에이전트가 실제 IT 자동화 작업에서 얼마나 효과적인지 측정하려면 체계적인 벤치마크가 필요하다고 말한다. 초기 릴리스는 세 영역을 대상으로 했다.
| 영역 | 초점 |
|---|---|
| SRE | availability와 resiliency |
| CISO | compliance와 security operations |
| FinOps | cost efficiency와 ROI optimization |
논문 초록에 따르면 ITBench의 초기 94개 real-world scenario에서 state-of-the-art 모델 기반 에이전트는 SRE 13.8%, CISO 25.2%, FinOps 0% 수준의 해결률을 보였다. 이번 ITBench-AA의 SRE 점수는 훨씬 강한 frontier 모델과 별도 평가 구현을 반영하지만, 메시지는 이어진다. 엔터프라이즈 IT 자동화는 일반 코딩 벤치마크보다 훨씬 더 어렵다.
왜 그럴까? 엔터프라이즈 IT 문제는 정답이 문서 안에 깔끔하게 들어 있지 않다. 원인은 여러 계층에 걸쳐 있고, 관측 데이터는 noisy하며, 증상은 실제 원인보다 훨씬 많이 보인다. 게다가 잘못된 자동 조치는 장애를 더 키울 수 있다.
그래서 SRE/CISO/FinOps 에이전트는 일반 챗봇과 다르게 설계해야 한다.
- 관측 가능한 데이터 범위를 명확히 제한해야 한다.
- 모델이 제출할 수 있는 action과 diagnosis schema를 강제해야 한다.
- false positive와 false negative의 비용을 따로 계산해야 한다.
- 자동 조치 전에 human-in-the-loop 또는 policy gate를 둬야 한다.
- 리더보드 점수가 아니라 우리 조직의 incident class별 성능을 측정해야 한다.
한국 개발자·운영팀을 위한 실무 해석
ITBench-AA를 모델 순위표로만 보면 아쉽다. 더 중요한 것은 AI 에이전트 도입 전략이다. 지금 당장 운영팀이 얻어야 할 교훈은 네 가지다.
1) 로그 요약 에이전트와 장애 대응 에이전트를 구분해야 한다
로그 요약은 유용하다. 하지만 로그 요약이 root cause diagnosis는 아니다. ITBench-AA가 보여주는 것처럼, 실제 운영 자동화는 여러 관측 신호를 연결해 최소 원인 entity로 좁히는 작업이다. 제품을 평가할 때도 “로그를 읽는가”가 아니라 “원인을 과잉 제출하지 않고 맞히는가”를 봐야 한다.
2) 에이전트에게 무한 조사권을 주는 것은 답이 아니다
turn count가 많아도 성능이 오르지 않는다는 결과는 중요하다. 운영 자동화에서 도구 호출은 공짜가 아니다. latency와 비용을 늘리고, 경우에 따라 잘못된 맥락을 더 많이 끌어들인다. 좋은 harness는 모델에게 더 많은 자유를 주는 것보다, 조사 경로와 제출 형식을 잘 제한하는 쪽에 가깝다.
3) 고성능 모델과 저비용 모델의 역할을 나눠야 한다
모든 알림을 가장 비싼 모델에 보낼 필요는 없다. 반대로 모든 진단을 저렴한 모델에 맡기는 것도 위험하다. 현실적인 구조는 1차 triage, 후보 좁히기, 고위험 incident escalation, human approval을 단계적으로 나누는 것이다.
4) 자체 벤치마크 없이 에이전트를 운영에 넣으면 안 된다
ITBench-AA 점수는 출발점일 뿐이다. 각 조직의 Kubernetes 구조, 로그 포맷, 배포 방식, 장애 유형은 다르다. 실제 도입 전에는 내부 incident postmortem, synthetic incident, read-only snapshot을 이용해 자체 평가셋을 만들어야 한다. 모델 교체보다 먼저 해야 할 일은 우리 조직의 장애 진단 채점 기준을 정하는 것이다.
결론: SRE 자동화의 병목은 모델 지능이 아니라 운영 설계다
ITBench-AA는 AI 에이전트 업계에 좋은 찬물을 끼얹는다. frontier 모델이 코드를 잘 쓰고, 도구를 잘 부르고, 긴 추론을 한다고 해서 곧바로 엔터프라이즈 SRE를 자동화할 수 있는 것은 아니다. Kubernetes 사고 진단처럼 실제 운영 환경에 가까워질수록 모델은 증상과 원인을 헷갈리고, 너무 많이 조사하고, 너무 많은 후보를 제출한다.
하지만 이 결과를 비관적으로만 볼 필요는 없다. 오히려 좋은 벤치마크가 생겼다는 점이 중요하다. 이제 에이전트 자동화는 “멋진 데모”에서 “반복 가능한 운영 평가”로 이동하고 있다. 한국의 개발팀과 플랫폼팀이 이 흐름에서 챙겨야 할 것은 최신 모델 이름보다 다음 질문이다.
우리 운영 환경에서 AI 에이전트가 무엇을 읽고, 어디까지 판단하고, 어떤 형식으로 멈추며, 언제 사람에게 넘길 것인가?
ITBench-AA의 메시지는 단순하다. 에이전트가 운영자가 되려면 더 똑똑한 답변만으로는 부족하다. 정확한 관측, 제한된 행동, 구조화된 진단, 비용 통제, 검증 가능한 벤치마크가 함께 있어야 한다.
참고한 주요 sources
- ITBench-AA: Frontier Models Score Below 50% on the First Benchmark for Agentic Enterprise IT Tasks — Hugging Face / IBM Research
- ITBench-AA Benchmark Leaderboard — Artificial Analysis
- ITBench GitHub Repository — IBM / itbench-hub
- ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks — arXiv