- Published on
OpenAI Workspace Agents: ChatGPT가 "대화창"에서 "업무 실행면"으로 바뀌는 이유
- Authors

- Name
- Kyunghyun Park
- @devkhpark
OpenAI Workspace Agents · ChatGPT · Responses API · Privacy Filter
OpenAI가 4월 22일에 한꺼번에 내놓은 공개 신호를 묶어 보면, 이번 변화의 핵심은 새 모델 이름이 아니다. 오히려 ChatGPT가 혼자 쓰는 대화형 도구에서 팀이 공유하는 작업 실행면(execution surface)으로 이동하고 있다는 점이 더 중요하다. Introducing workspace agents in ChatGPT, Workspace agents, Responses API WebSockets, OpenAI Privacy Filter, Making ChatGPT better for clinicians를 함께 보면 이 방향이 더 또렷해진다.
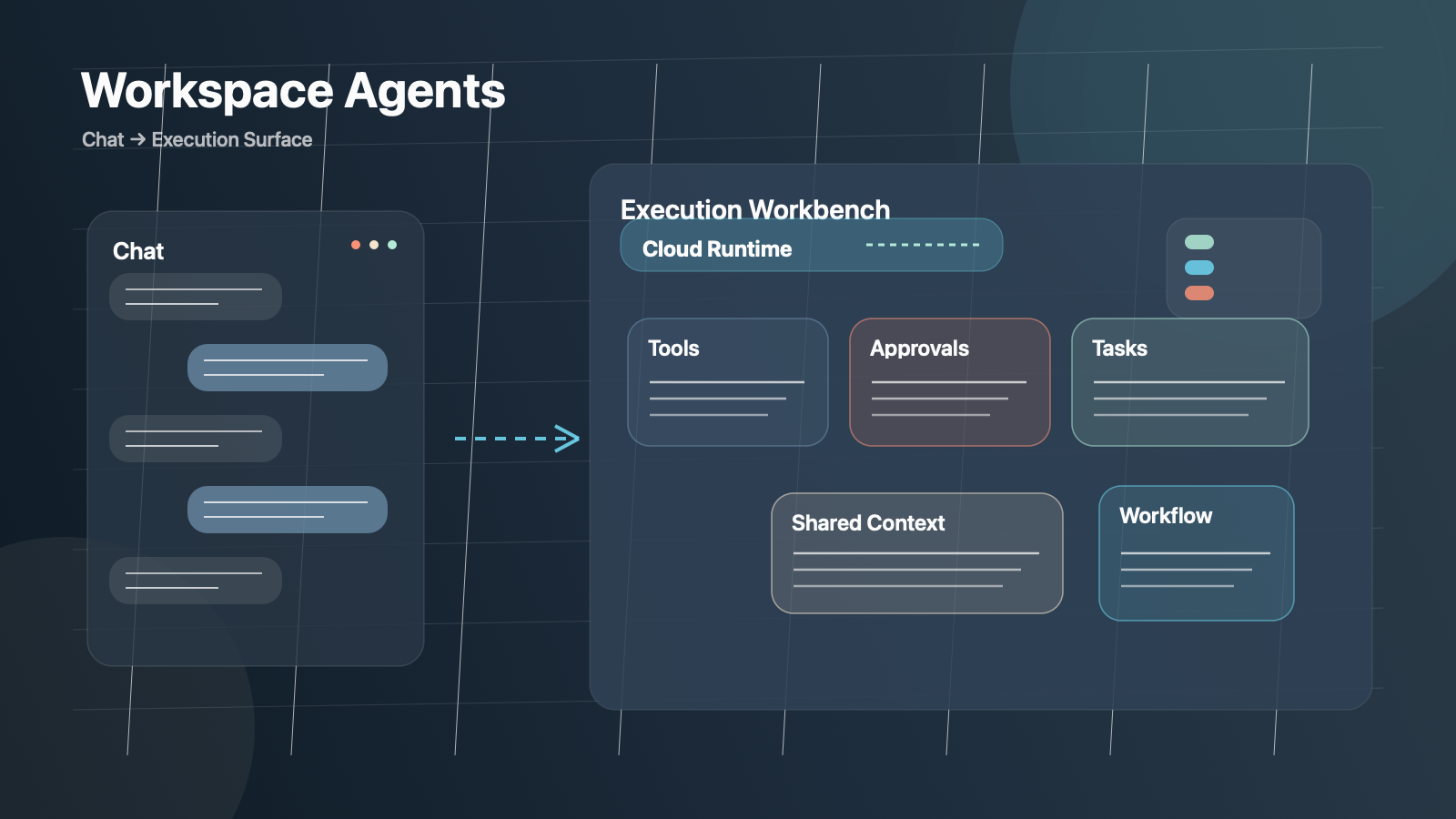
많은 사람이 workspace agents를 GPTs의 다음 버전 정도로 읽을 수 있다. 하지만 공식 글을 자세히 보면 OpenAI가 밀고 있는 것은 단순한 프롬프트 템플릿 시장이 아니다. 클라우드에서 오래 돌고, 조직 권한 안에서 움직이고, 승인과 공유를 전제로 하며, 특정 업무 흐름을 반복 실행하는 에이전트 계층이다.
이 글은 OpenAI의 1차 공식 소스만 기준으로, 왜 workspace agents가 단순한 제품 기능이 아니라 운영 계층의 변화인지 정리한다. 특히 한국의 개발자, SaaS 운영자, 내부 도구 빌더 관점에서 무엇을 준비해야 하는지도 같이 본다.
한 줄 논지: OpenAI는 ChatGPT를 더 똑똑한 채팅창으로 확장하는 것이 아니라, 팀 단위의 반복 업무를 맡는 클라우드 실행면으로 재설계하고 있다.
이번 발표의 본질은 GPTs 업그레이드가 아니라 "공유 가능한 장기 실행 작업자"다
OpenAI의 Introducing workspace agents in ChatGPT 포스트는 처음부터 포지셔닝이 분명하다. workspace agents는 shared agents, complex tasks, long-running workflows, organization permissions and controls라는 표현으로 설명된다. 이 네 가지 키워드는 그냥 마케팅 문구가 아니다.
기존 GPTs가 개인 생산성 보조와 프롬프트 재사용에 가까웠다면, workspace agents는 처음부터 다음 조건을 전제로 한다.
- 팀이 함께 쓰는 공유 자산일 것
- Slack 같은 외부 표면으로 배포될 것
- 조직의 권한/승인 체계를 벗어나지 않을 것
- 사용자가 자리를 비워도 계속 작업할 것
- 반복적인 업무 흐름을 사람이 아닌 에이전트가 맡을 것
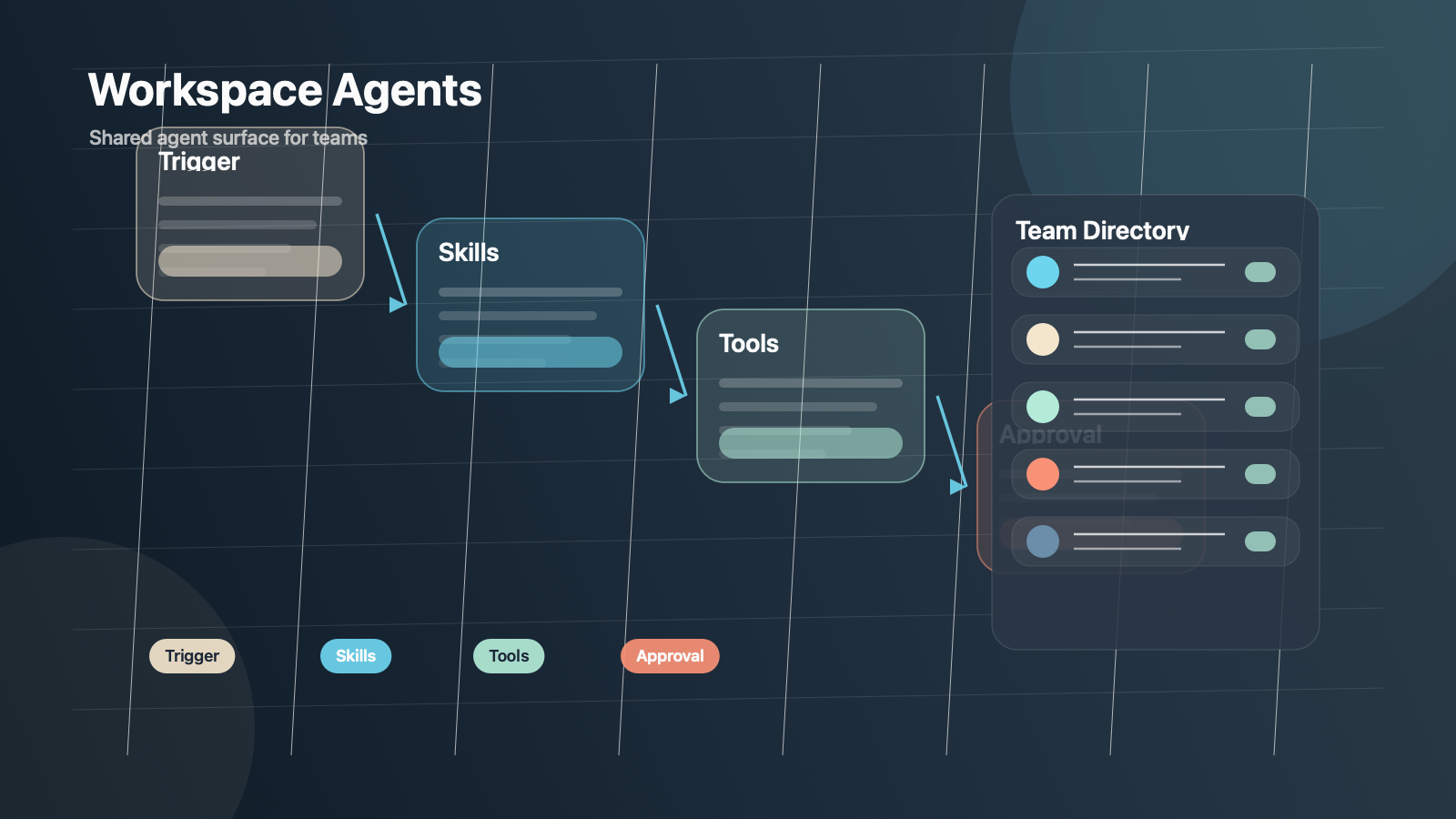
OpenAI Academy의 Workspace agents 문서는 이 구조를 더 명확하게 쪼갠다. 에이전트는 trigger, process and skills, tools and systems의 세 요소로 설명되고, 특히 적합한 업무의 조건으로 repeatable, structured, time-based or event-driven, tool-based를 제시한다.
이건 꽤 중요한 구분이다. OpenAI가 직접 말하듯이, 브레인스토밍이나 탐색적 글쓰기는 여전히 일반 채팅이 더 맞을 수 있다. 반대로 workspace agents는 사람이 매번 같은 문맥을 다시 설명하고 여러 도구를 오가며 손으로 이어 붙이던 업무를 맡도록 설계된다.
즉 이제 경쟁 포인트는 "질문에 얼마나 똑똑하게 답하느냐"만이 아니다. 얼마나 반복 가능한 workflow를 안정적으로 캡슐화하느냐가 더 중요해진다.
왜 지금 중요할까: 에이전트가 실제로 쓸 만해지려면 런타임이 먼저 빨라져야 한다
workspace agents가 진짜 제품 계층이 되려면, UI보다 먼저 해결돼야 하는 문제가 있다. 바로 agent loop의 지연시간이다. OpenAI의 Speeding up agentic workflows with WebSockets in the Responses API는 이 점을 아주 노골적으로 보여 준다.
이 글에서 OpenAI는 Codex가 버그를 고칠 때 내부적으로 어떤 루프를 도는지 설명한다. 관련 파일을 찾고, 읽고, 수정하고, 테스트를 돌리고, 결과를 다시 API에 보내고, 다음 액션을 결정하는 식의 왕복이 반복된다. 문제는 모델 추론이 빨라질수록, 오히려 API 서비스 오버헤드와 요청 왕복이 병목이 되기 시작한다는 점이다.
OpenAI가 공개한 핵심 메시지는 이렇다.
- 예전에는 GPU 추론이 가장 느린 구간이었지만 이제는 아니다.
- 에이전트형 workflow에서는 수십 번의 request-response 왕복이 누적된다.
- 그래서 단순 HTTP 호출 반복이 아니라 persistent connection이 필요해졌다.
- 그 해결책 중 핵심이 WebSockets 기반 Responses API 개선이다.
- OpenAI는 이 최적화로 agent loop를 종단 간 40% 더 빠르게 만들었다고 설명한다.
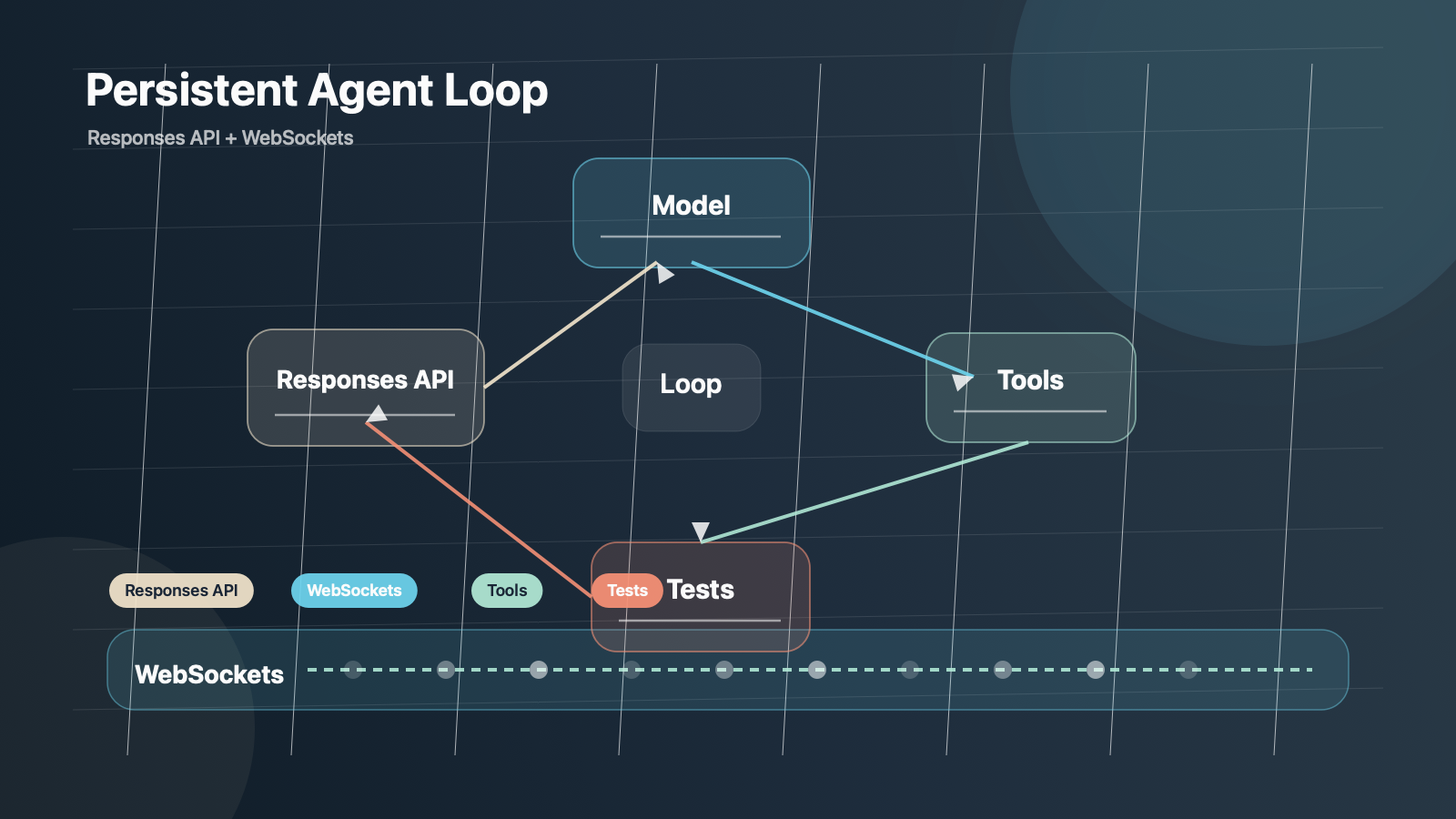
이건 단순한 인프라 튜닝이 아니다. 에이전트를 제품으로 팔려면 "생각하는 모델" 못지않게 "계속 일하는 런타임"이 중요하다는 뜻이다.
개발자 관점에서 보면 함의는 더 직접적이다.
에이전트 제품 경쟁은 모델 품질만으로 안 끝난다. 이제는 장기 세션 유지, 상태 캐시, 도구 호출 오버헤드, 승인 흐름, 실패 복구가 모두 제품 품질이다.
Responses API는 단순 응답 API가 아니라 에이전트용 transport 계층으로 변하고 있다. WebSockets 지원은 채팅 UX가 아니라 multi-step tool-use loop를 위한 변화다.
코딩 에이전트에서 검증된 패턴이 다른 업무용 agent로 퍼질 가능성이 높다. Codex 루프에서 먼저 드러난 병목은 앞으로 sales ops, support triage, reporting, compliance workflow에서도 같은 문제로 나타난다.
요컨대 workspace agents는 제품이고, WebSockets는 그 제품을 실제로 돌아가게 만드는 배관이다. 둘은 따로 보면 안 된다.
OpenAI가 같이 내놓은 것은 "기능"보다 운영 계층이다
이번 흐름을 더 흥미롭게 만드는 건 workspace agents 하나만 나온 게 아니라는 점이다. 같은 48시간 안에 OpenAI는 OpenAI Privacy Filter와 Making ChatGPT better for clinicians도 같이 공개했다. 이 둘을 함께 보면 OpenAI가 어디로 가는지 더 선명해진다.
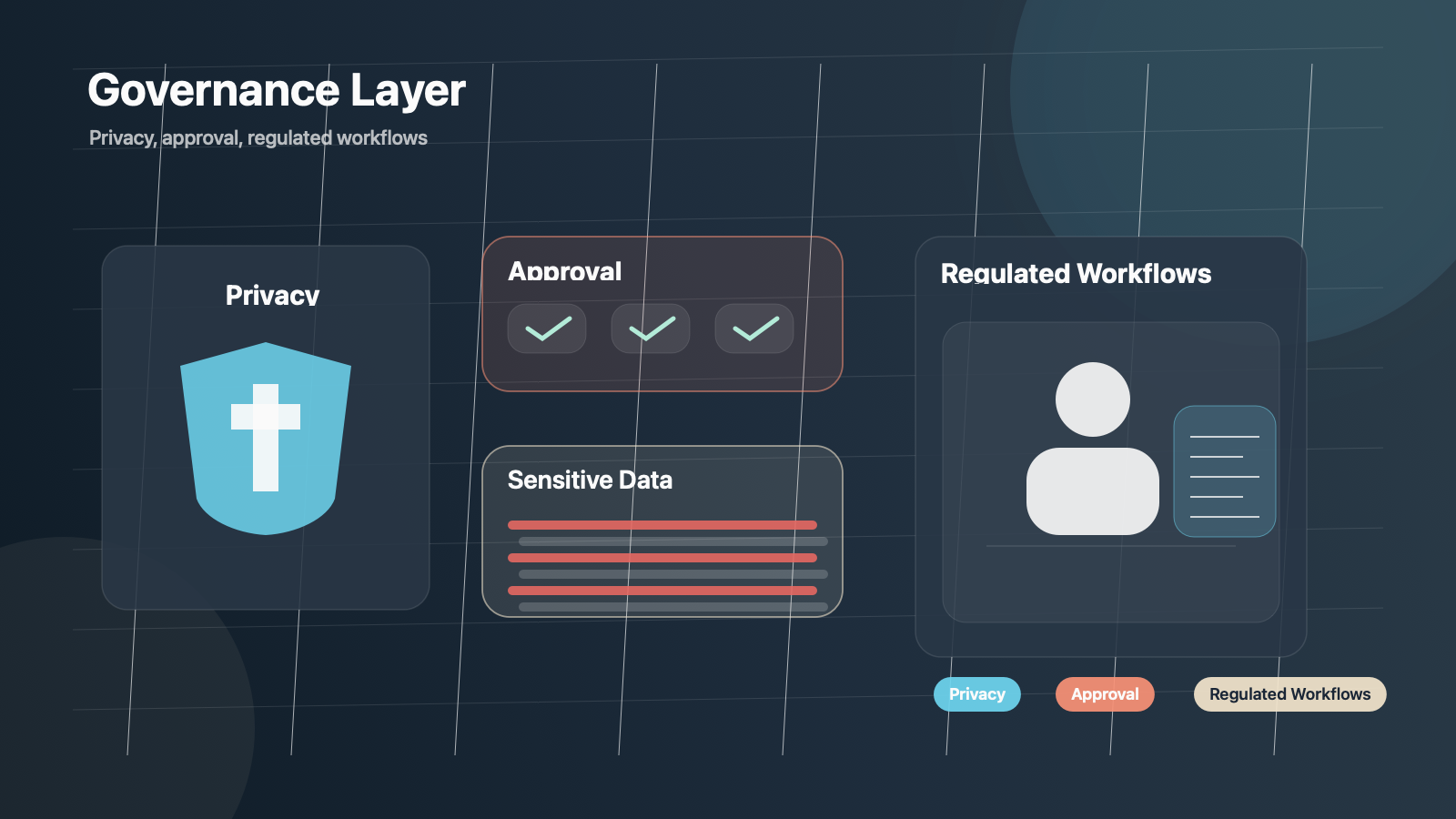
Privacy Filter는 PII 탐지와 마스킹을 위한 open-weight 모델이다. OpenAI는 이 모델이 긴 텍스트를 한 번에 처리하고, 문맥 기반으로 PII를 감지하며, 로컬 실행도 가능하다고 설명한다. 게다가 training, indexing, logging, review pipeline에 바로 넣을 수 있다고 못 박는다.
이건 왜 중요할까? workspace agents가 조직 내부 문서, 고객 정보, 메시지, CRM, 의료 문맥 같은 민감한 표면으로 들어가면, 가장 먼저 부딪히는 벽은 성능이 아니라 개인정보와 규정 준수다. Privacy Filter는 바로 그 벽을 낮추는 조각이다.
한편 Making ChatGPT better for clinicians는 훨씬 더 직접적인 제품 패키징 사례다. 여기서 OpenAI는 clinician workflow를 위해 다음 요소를 한 묶음으로 제시한다.
- complex clinical questions에 맞춘 frontier models
- referral letters, prior auth, patient instructions 같은 repeatable skills
- trusted clinical search
- deep research across medical journals
- optional HIPAA support
- account security and privacy
이 조합은 시사점이 크다. OpenAI가 말하는 에이전트는 더 이상 "똑똑한 봇"이 아니다. 오히려 다음에 가깝다.
- 특정 산업용 workflow shell
- 조직 정책을 반영한 skills 묶음
- 승인과 보안이 포함된 작업 실행기
- 민감한 데이터 파이프라인에 꽂을 수 있는 운영 부품
즉 OpenAI는 agent를 demo surface가 아니라 regulated work surface로 밀고 있다.
그래서 workspace agents는 SaaS 기능 추가가 아니라 제품 전략 문제다
한국의 개발자나 스타트업이 이 흐름에서 읽어야 할 건 "우리도 agent 붙여야지" 같은 가벼운 결론이 아니다. 더 중요한 질문은 앞으로 우리가 만드는 제품의 고유 표면이 어디에 남는가다.
workspace agents가 강해질수록 ChatGPT 자체가 다음 역할을 흡수할 가능성이 있다.
- 주간 리포트 생성
- 리드 스코어링과 후속 메일 초안 작성
- 제품 피드백 triage
- 내부 IT 요청 검토와 티켓 발행
- 규정 준수 체크리스트 기반 리뷰
- 문서 요약과 승인용 초안 작성
이런 업무가 모두 ChatGPT 안의 공유 agent, Slack 진입점, 연결된 앱, 승인 흐름으로 해결되기 시작하면, 독립 SaaS가 살아남는 자리는 달라진다. 앞으로는 단순히 "AI를 붙였다"보다 아래 셋 중 하나를 확보해야 한다.
1. 고유한 데이터 표면
남들이 쉽게 연결할 수 없는 데이터, 문맥, 사내 운영 규칙이 있어야 한다. workspace agents는 일반적인 반복 업무를 빠르게 흡수할 수 있기 때문이다.
2. 강한 실행 책임
실패했을 때 비용이 큰 업무, 예를 들어 회계 마감, 의료 문서, 법무 검토, 구매 승인처럼 추적성·감사성·책임 주체가 중요한 곳에서는 여전히 전용 제품 가치가 크다.
3. 더 깊은 운영 계층
단순 생성보다 배포, 관측, 비용 추적, 권한 통제, 로깅, 품질 관리가 중요한 도메인이라면 기회가 남아 있다. OpenAI가 지금 하는 것도 결국 이 운영 계층 확장이다.
실무적으로 어떻게 대응해야 하나
이 흐름은 단순 감상이 아니라 실제 제품 설계에 영향을 준다. 지금 시점에서 한국 팀이 가져가야 할 실무 포인트는 다음 다섯 가지다.
1) "에이전트"보다 "반복 workflow"부터 정의하라
OpenAI Academy가 강조하듯 좋은 agent 후보는 repeatable하고 structured하며 tool-based한 일이다. 먼저 팀 안에서 주간 단위로 반복되는 작업을 찾아야 한다. 에이전트는 아이디어가 아니라 운영 루틴에서 나온다.
2) 승인 지점을 먼저 설계하라
workspace agents의 진짜 차별점은 자동화 자체보다 approval-aware workflow다. 고객 메시지 발송, 티켓 생성, 예산 변경, 민감 문서 요약처럼 실수 비용이 큰 영역은 자동 실행보다 초안 + 승인 구조로 가야 한다.
3) 민감 데이터 경계를 분리하라
Privacy Filter가 따로 나온 이유를 가볍게 보면 안 된다. 앞으로 agent 설계는 프롬프트 엔지니어링보다 어떤 데이터가 모델에 들어가기 전에 마스킹되는가가 더 중요해질 수 있다. 로그, 인덱싱 데이터, 리뷰 파이프라인부터 경계를 나눠야 한다.
4) 런타임을 측정하라
WebSockets 글이 말해주는 건 단순하다. 에이전트는 생각보다 네트워크 왕복과 도구 호출 비용에 많이 묶인다. tool call 수, 평균 loop 길이, approval 대기 시간, 재시도율 같은 지표를 먼저 잡아야 한다.
5) vertical packaging을 준비하라
clinicians용 패키징이 보여주듯, 앞으로 승부는 범용 assistant보다 산업별 묶음에서 날 가능성이 높다. 의료, 회계, 제조, 고객지원, 광고운영처럼 도메인별 workflow + trust layer + evaluation을 묶는 쪽이 더 강하다.
실전 해석: 지금 OpenAI가 파는 것은 모델이 아니라 "업무용 운영면"이다
이번 흐름을 한 문장으로 압축하면 이렇다. OpenAI는 더 똑똑한 모델을 파는 회사에서 끝나지 않으려 한다. 대신 조직이 실제 일을 맡기는 실행면을 선점하려 한다.
- workspace agents는 공유 가능한 장기 실행 workflow
- Responses API WebSockets는 그 workflow를 버티게 하는 runtime 배관
- Privacy Filter는 민감 데이터 처리를 위한 안전 부품
- clinicians 패키징은 규제 산업용 수직 번들 사례
이 조합은 꽤 위협적이다. 왜냐하면 이건 기능 몇 개의 추가가 아니라, 앞으로 많은 SaaS의 "상위 orchestration layer"를 OpenAI가 가져가겠다는 신호이기 때문이다.
반대로 기회도 있다. OpenAI가 모든 산업의 디테일을 직접 장악할 수는 없다. 그래서 각 산업의 데이터 구조, 승인 문화, 감사 요구사항, 실패 비용을 가장 잘 아는 팀에게는 여전히 자리가 남는다. 다만 그 자리는 단순한 UI 껍데기가 아니라 운영 규칙과 도메인 책임을 가진 제품이어야 한다.
결론
workspace agents를 GPTs의 확장판 정도로 보면 이번 변화를 놓치기 쉽다. OpenAI가 실제로 보여 준 것은 더 크다. ChatGPT는 이제 개인용 대화 도구에서 벗어나, 공유되고, 오래 돌고, 승인받고, 민감 데이터를 다루며, 산업별 workflow를 수행하는 실행면으로 이동하고 있다.
그래서 앞으로 중요한 질문은 "어떤 모델이 더 똑똑한가"보다 다음에 가까워진다.
- 누가 더 오래 실행되는가
- 누가 더 안전하게 배치되는가
- 누가 더 많은 도구와 권한 체계를 흡수하는가
- 누가 더 좋은 산업별 작업 표면을 제공하는가
OpenAI의 4월 22일 묶음은 바로 그 방향 전환을 확인해 주는 신호다. 앞으로 agent 경쟁은 채팅 품질이 아니라 운영 가능한 실행면의 밀도에서 갈릴 가능성이 높다.