- Published on
Microsoft VibeVoice ASR: 60분 음성을 한 번에 읽는 오픈소스 음성 런타임의 의미
- Authors

- Name
- Kyunghyun Park
- @devkhpark
Microsoft · VibeVoice ASR · long-form speech-to-text · vLLM 음성 런타임
Microsoft의 VibeVoice가 다시 GitHub Trending에 올라온 건 단순한 스타 수 이벤트로만 볼 일이 아니다. 더 흥미로운 신호는 저장소가 말하는 방향이다. VibeVoice-ASR은 “음성을 텍스트로 바꾼다”에서 멈추지 않고, 긴 오디오를 누가, 언제, 무엇을 말했는지까지 구조화해 내는 long-form voice intelligence 런타임을 지향한다.
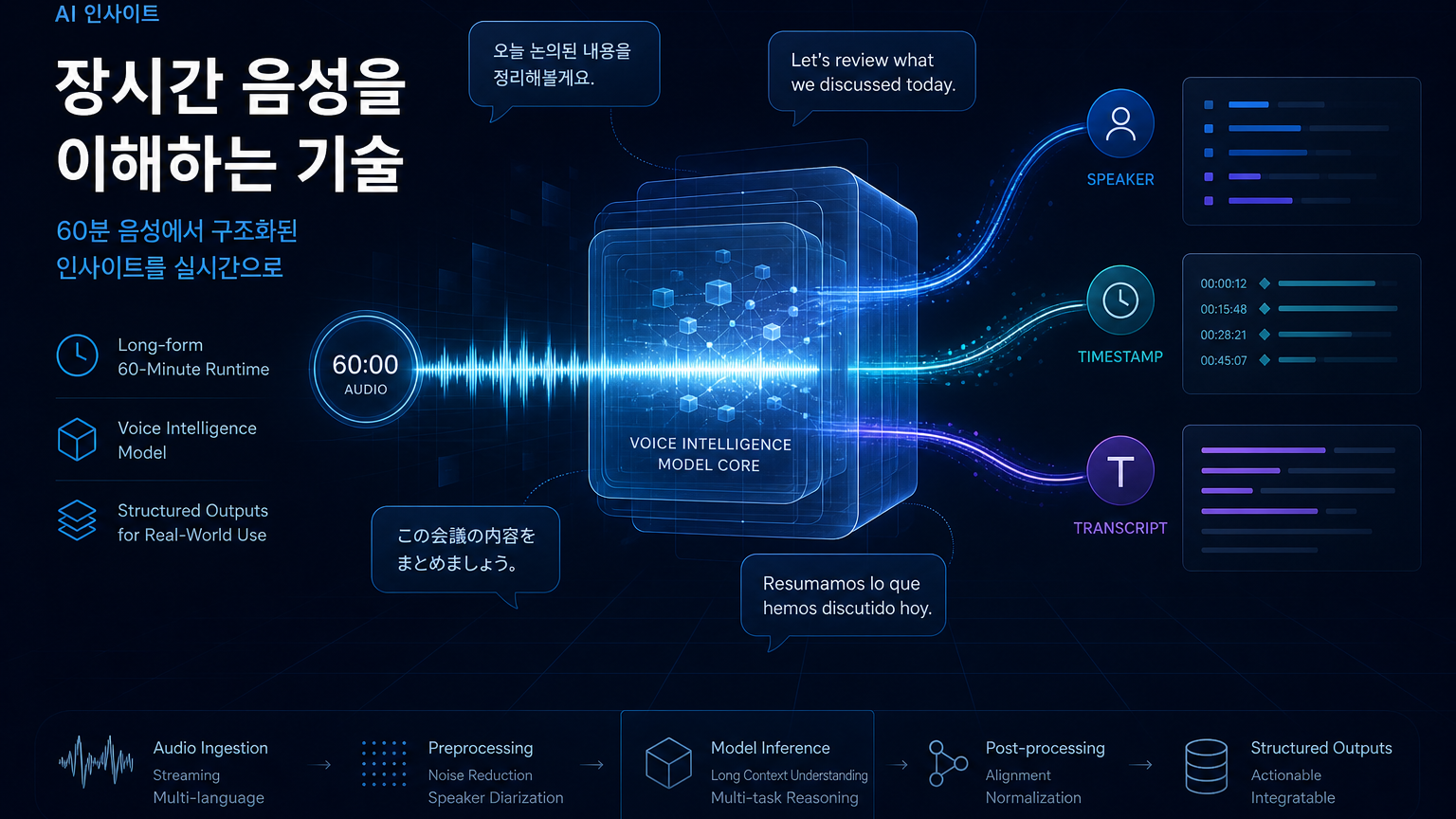
이 글의 결론부터 말하면 이렇다. VibeVoice ASR의 핵심은 음성 인식 품질 경쟁보다 “긴 오디오를 제품 데이터 구조로 바꾸는 운영 계층”에 있다. 회의록, 콜센터, 강의, 인터뷰, 팟캐스트, 리서치 녹취처럼 30분~1시간 단위의 음성을 다루는 팀에게 중요한 것은 짧은 샘플의 WER만이 아니다. speaker tracking, timestamp, domain term, streaming serving, fine-tuning, 비용과 지연시간까지 같이 봐야 한다.
기준 시점: 이 글은 2026-06-07에 확인한 Microsoft VibeVoice GitHub README, VibeVoice-ASR 문서, Hugging Face Transformers 모델 카드, vLLM 배포 문서, LoRA fine-tuning 문서, arXiv 기술 보고서 기준이다. 모델 파일, 라이선스, API 형태, 의존성은 빠르게 바뀔 수 있으니 실제 적용 전 원문을 다시 확인해야 한다.
왜 지금 VibeVoice를 봐야 하나: “STT API”가 아니라 긴 음성 데이터 파이프라인이다
VibeVoice README는 프로젝트를 “Open-Source Frontier Voice AI”라고 소개한다. 그중 개발자 입장에서 가장 실용적인 축은 VibeVoice-ASR이다. 문서는 이 모델을 60분 길이의 long-form audio를 single pass로 처리하고, 결과를 speaker, timestamp, content가 포함된 구조적 transcription으로 생성하는 unified speech-to-text model이라고 설명한다.
여기서 중요한 단어는 “single pass”다. 기존 ASR 파이프라인은 긴 파일을 짧게 자르고, 각 조각을 인식한 뒤, 후처리로 speaker diarization과 timestamp를 붙이는 경우가 많다. 이 방식은 구현은 단순하지만 운영에서는 자주 삐걱거린다.
- 조각 경계에서 문맥이 끊긴다.
- 같은 화자를 다른 화자로 보거나, 반대로 여러 화자를 합쳐버린다.
- 회의 중 반복되는 약어, 제품명, 사람 이름이 흔들린다.
- “전체 대화 흐름”을 봐야 이해되는 발화가 잘못 해석된다.
VibeVoice-ASR이 주장하는 방향은 이 병목을 줄이는 것이다. 모델 카드와 문서는 64K token length 안에서 최대 60분 연속 음성을 받아 speaker tracking과 semantic coherence를 유지한다고 설명한다. 물론 실제 성능은 도메인·음질·화자 수·GPU 환경에 따라 검증해야 한다. 그래도 제품 설계 관점에서 보면 방향은 선명하다. 음성을 짧은 파일들의 묶음이 아니라, 하나의 긴 컨텍스트로 다루려는 시도다.
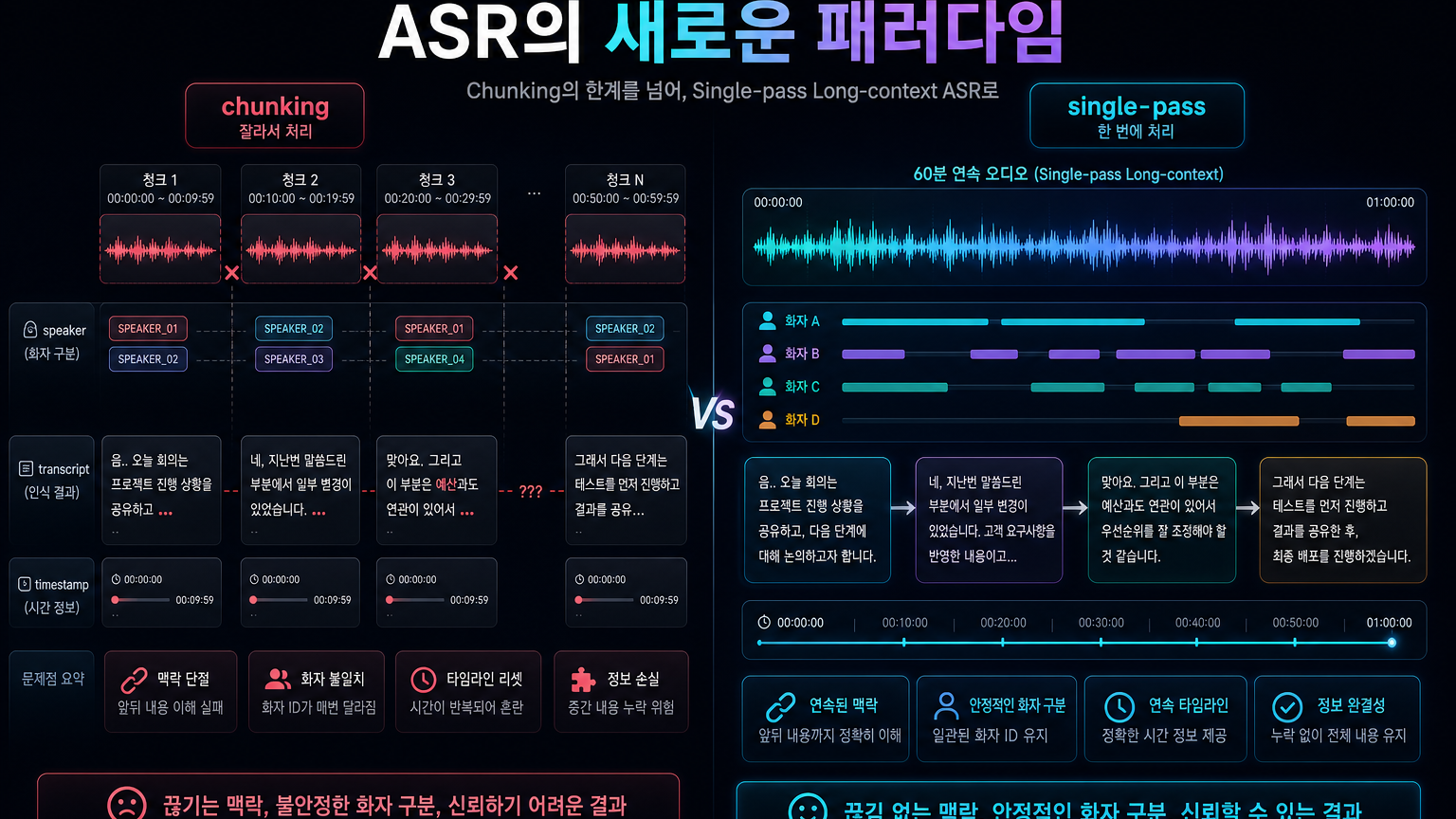
60분 single-pass가 제품 UX를 바꾸는 지점
긴 음성 처리에서 개발자가 실제로 원하는 출력은 대개 순수 텍스트가 아니다. 예를 들어 회의록 제품이라면 다음 정보가 필요하다.
- 누가 말했는가 — 화자 구분과 speaker label
- 언제 말했는가 — timestamp와 segment boundary
- 무엇을 말했는가 — transcript와 문장 단위 정리
- 어떤 맥락인가 — 회의 주제, 제품명, 고객명, 내부 약어
- 다음 워크플로로 어떻게 넘길 것인가 — 요약, 액션 아이템, 검색 인덱스, CRM/티켓 연결
VibeVoice-ASR 문서가 “Who, When, What”을 전면에 둔 이유도 여기에 있다. 음성 인식 모델이 단순 텍스트 덤프만 내보내면 이후 LLM 요약 단계에서 다시 구조를 복원해야 한다. 반대로 ASR 단계에서 speaker와 timestamp가 같이 나오면, 그 다음 단계는 훨씬 안정적이다.
예를 들어 고객 인터뷰 분석 파이프라인을 생각해보자. “고객이 어떤 불편을 말했다”는 문장만으로는 부족하다. 누가 말했는지, 어느 시점에 반론이 나왔는지, 같은 고객이 앞뒤에서 어떤 맥락을 깔았는지가 중요하다. 긴 컨텍스트 ASR은 이 정보를 잃지 않게 하는 첫 번째 방어선이다.
개발자 입장에서는 이 차이가 제품 기능으로 바로 이어진다.
- 긴 회의 파일을 조각내지 않고 한 번에 처리하는 업로드 UX
- speaker별 발화 검색
- 특정 timestamp로 돌아가는 재생 링크
- 회의 전체의 topic drift 분석
- 후속 LLM agent가 “앞에서 A가 말한 내용”을 참조하는 워크플로
즉 VibeVoice-ASR을 볼 때는 “Whisper보다 낫나?” 같은 단순 비교보다, 긴 음성 컨텍스트를 downstream AI 작업에 얼마나 잘 넘겨주는가를 봐야 한다.
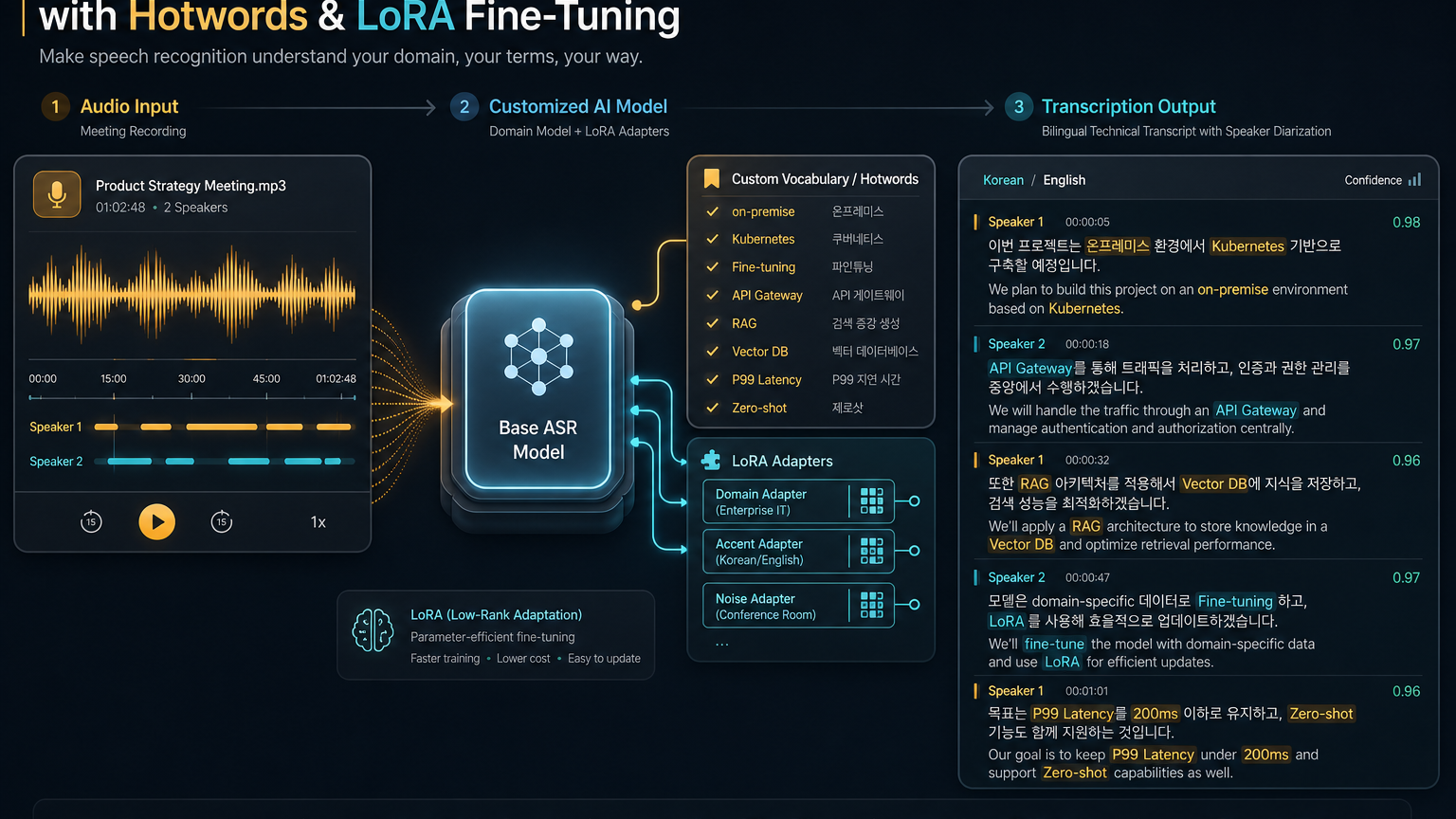
50개 이상 언어와 hotword: 한국 팀에게 중요한 건 “한국어 지원”보다 도메인 단어다
Hugging Face의 VibeVoice-ASR-HF 모델 카드는 Transformers 호환 버전이라고 소개하며, 영어·중국어·일본어·한국어를 포함한 50개 이상 언어를 나열한다. 이 자체도 의미가 있지만, 한국 개발팀에게 더 중요한 포인트는 Customized Hotwords다.
대부분의 실무 음성 데이터는 일반 뉴스나 교과서 문장이 아니다. 사내 제품명, 고객사명, API 이름, 사람 이름, 약어, 혼합 언어가 계속 나온다. 예를 들어 “MXC”, “vLLM”, “LoRA”, “Contentlayer”, “Vercel Blob” 같은 단어는 일반 ASR이 쉽게 틀릴 수 있다. 한국어 문장 안에 영어 기술 용어가 섞이면 더 그렇다.
VibeVoice-ASR 문서는 customized hotwords를 넣어 특정 이름, 기술 용어, 배경 정보를 recognition process에 반영할 수 있다고 설명한다. 이 기능이 중요한 이유는 정확도 숫자보다 운영 실패율 때문이다.
- 회의록에서 고객사명을 틀리면 검색과 CRM 연결이 깨진다.
- 강의 자막에서 프레임워크 이름을 틀리면 학습 자료 신뢰도가 떨어진다.
- 콜센터 녹취에서 제품명과 장애 코드가 틀리면 후속 분석이 무의미해진다.
그래서 한국어 지원 여부만 볼 게 아니라, 한국어+영어 혼합 도메인에서 단어 제어권을 얼마나 주는지를 봐야 한다. VibeVoice-ASR의 hotword와 context 입력은 이 지점에서 꽤 실용적인 신호다.
Transformers와 vLLM 지원의 의미: 모델 데모에서 API 서비스로 내려온다
README의 2026-03-06 업데이트는 VibeVoice ASR이 Transformers-compatible release에 들어갔다고 말한다. 별도 연구 코드만 있는 모델과 Transformers 생태계에 들어온 모델은 개발 경험이 다르다. 후자는 모델 로딩, 토크나이저, 추론 코드, 배포 자동화에 훨씬 익숙한 경로를 제공한다.
여기에 더해 VibeVoice 저장소는 vLLM ASR deployment 문서도 제공한다. 이 문서는 VibeVoice ASR을 vLLM 기반 고성능 API 서비스로 배포하고, OpenAI-compatible /v1/chat/completions endpoint와 streaming을 제공하는 플러그인 구조를 설명한다. 또 continuous batching, data parallel, multi-GPU 배포 같은 운영 포인트를 전면에 둔다.
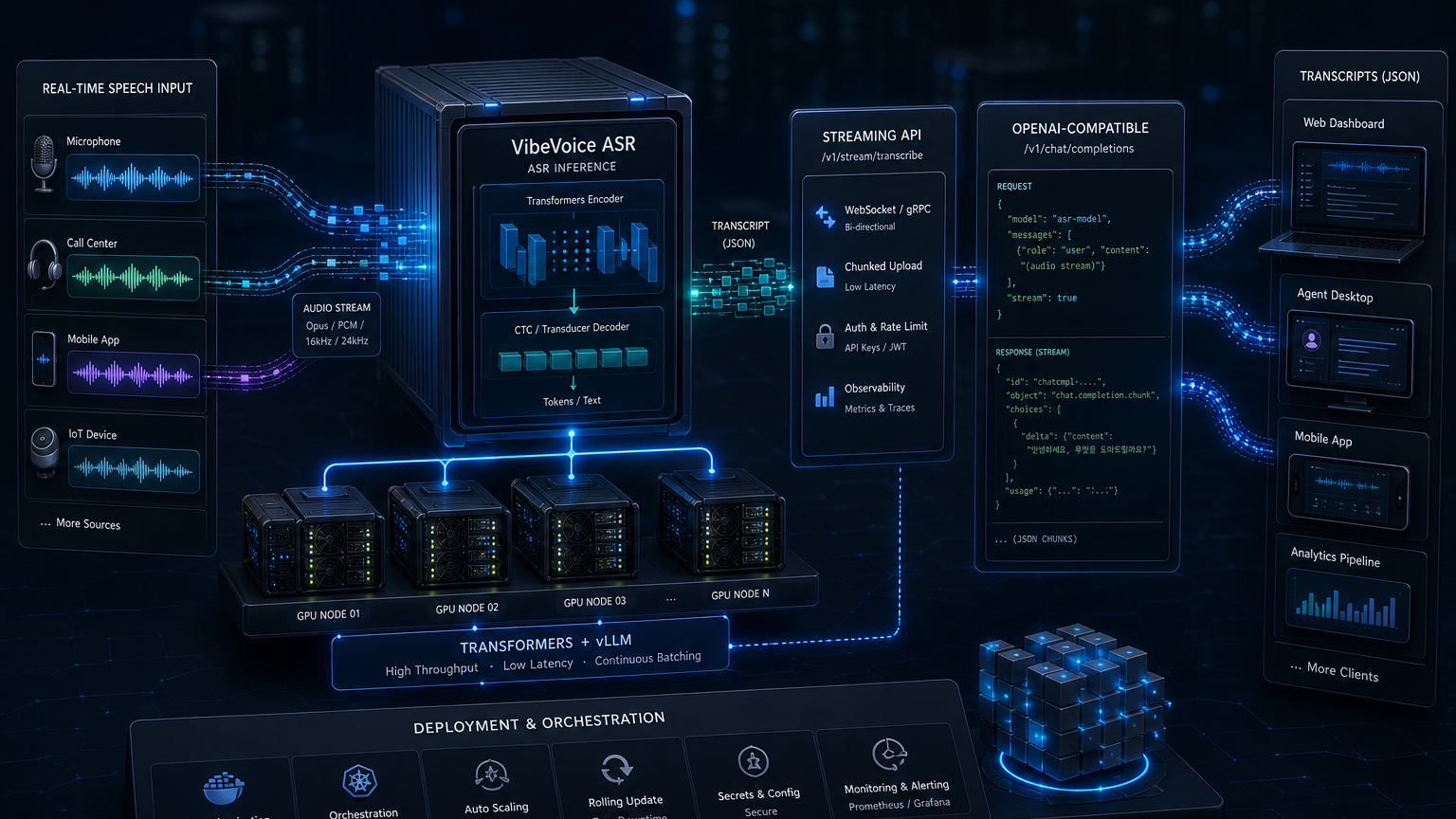
이건 꽤 중요하다. 오픈소스 음성 모델이 제품에 들어가려면 “노트북에서 한 번 돌아간다”로는 부족하다. 실제 서비스에서는 다음 질문이 바로 나온다.
| 질문 | 왜 중요한가 |
|---|---|
| 긴 오디오를 여러 사용자가 동시에 올리면 어떻게 큐잉할 것인가 | 처리 시간이 길어질수록 비용과 사용자 대기 시간이 커진다 |
| streaming partial result를 줄 수 있는가 | 긴 파일에서 “끝날 때까지 기다림”은 UX가 나쁘다 |
| GPU를 어떻게 나눌 것인가 | tensor parallel과 data parallel 전략이 비용을 좌우한다 |
| API가 기존 LLM 클라이언트와 닮았는가 | 앱 레이어 통합과 observability가 쉬워진다 |
| 모델 코드 수정 없이 붙일 수 있는가 | 업그레이드와 유지보수 리스크가 줄어든다 |
VibeVoice의 vLLM 문서는 이 질문을 직접 겨냥한다. 특히 OpenAI-compatible endpoint는 단순 편의 기능이 아니다. 이미 LLM API 호출, tracing, rate limit, queue, retry, billing을 갖춘 팀이라면 음성 인식도 비슷한 운영 표면으로 넣을 수 있다. 이건 음성 AI가 별도 미디어 파이프라인에서 LLM 인프라 운영 체계 안으로 들어오는 신호다.
LoRA fine-tuning은 “우리 회사 말투”와 “우리 도메인 단어”를 위한 안전장치다
VibeVoice 저장소에는 ASR LoRA fine-tuning guide도 있다. 문서는 toy dataset이 데모용 synthetic audio일 뿐이며, 실제 학습에는 real audio recordings와 accurate transcriptions를 준비해야 한다고 분명히 적는다. JSON label format은 audio duration, audio path, speaker별 segment, start/end timestamp, optional customized context를 포함한다.
이 형식은 제품 팀에게 꽤 현실적인 메시지를 준다. 음성 AI를 실제 도메인에 넣으면 결국 다음 문제가 생긴다.
- 특정 고객군의 억양이나 녹음 환경
- 내부 제품명과 약어
- 상담원 스크립트나 회의체 특유의 말버릇
- 한국어와 영어가 섞인 문장
- speaker label과 timestamp 품질 요구사항
hotword만으로 해결되는 문제가 있고, fine-tuning까지 가야 하는 문제가 있다. VibeVoice의 LoRA 경로는 후자를 위한 선택지를 제공한다. 물론 이 지점에서는 데이터 거버넌스가 더 중요해진다. 회의·콜센터·인터뷰 음성은 개인정보와 기업 기밀이 섞이기 쉽다. 오픈소스 모델을 쓴다고 해서 데이터 리스크가 사라지는 게 아니라, 오히려 학습·보관·삭제 정책을 더 명확히 해야 한다.
기술 보고서가 말하는 방향: ASR도 LLM식 long-context 문제로 바뀐다
VIBEVOICE-ASR Technical Report는 모델을 long-form, multi-speaker, timestamp-aware speech recognition 문제로 다룬다. 이 흐름은 요즘 AI 시스템의 큰 방향과 맞물린다. 텍스트 LLM이 짧은 prompt completion에서 long-context workflow로 이동했듯, 음성 인식도 짧은 utterance transcription에서 긴 오디오 이해로 이동하고 있다.
이 관점에서 ASR 모델의 경쟁축은 세 가지로 바뀐다.
- 길이 — 몇 분짜리 클립이 아니라 1시간 단위 파일을 얼마나 안정적으로 처리하는가
- 구조 — transcript만이 아니라 speaker/timestamp/context를 얼마나 잘 보존하는가
- 배포 — 연구 코드가 아니라 API, streaming, batching, multi-GPU 운영이 가능한가
VibeVoice-ASR은 이 세 가지를 한 저장소 안에서 묶으려 한다. 이것이 완성형이라는 뜻은 아니다. 오히려 초기 도입팀은 모델 크기, GPU 비용, 한국어 실제 품질, noisy audio, diarization edge case, 개인정보 처리까지 냉정하게 테스트해야 한다. 하지만 방향은 분명하다. 음성 인식은 이제 “파일을 텍스트로 변환하는 부가 기능”이 아니라, AI 제품의 입력 계층이 되고 있다.
실무 적용 체크리스트: 바로 붙이기 전에 확인할 것들
VibeVoice-ASR을 검토하는 팀이라면, 데모 품질보다 아래 항목을 먼저 확인하는 편이 좋다.
1) 입력 파일의 현실성
사내 회의, 원격 미팅, 콜센터 녹취, 강의 오디오는 품질이 제각각이다. 배경 소음, 겹침 발화, 마이크 거리, 압축률, 채널 분리 여부가 성능을 크게 흔든다. 대표 샘플 10개보다 실패 사례 30개를 먼저 모으는 편이 낫다.
2) 한국어와 code-switching
모델 카드가 한국어를 포함하더라도 실제 제품에서는 “한국어 문장 안의 영어 기술 용어”가 문제다. hotword와 customized context를 넣었을 때 얼마나 좋아지는지 별도 평가해야 한다.
3) 출력 스키마
나중에 요약·검색·CRM·티켓·노션·문서화로 넘길 거라면 transcript 문자열만 저장하지 말아야 한다. speaker, start/end, confidence 또는 후처리 상태, 원본 audio offset을 함께 저장해야 재처리와 감사가 가능하다.
4) 배포 비용과 지연시간
60분 single-pass는 UX상 매력적이지만, 서버 비용과 처리 시간이 제품 단가를 결정한다. vLLM 배포 문서가 말하는 continuous batching, tensor parallel, data parallel은 단순 최적화가 아니라 수익성 문제다.
5) 데이터 정책
회의·콜센터 음성은 민감하다. 오픈소스 모델을 자체 호스팅하면 외부 API 전송은 줄일 수 있지만, 대신 내부 저장·접근권한·학습 데이터 재사용·삭제 요청 대응 책임이 커진다.
Practical interpretation: 한국 개발팀에게 VibeVoice가 주는 힌트
VibeVoice-ASR을 당장 프로덕션에 넣을지 말지는 별개의 문제다. 하지만 이 프로젝트가 보여주는 방향은 꽤 실용적이다.
첫째, 음성 AI 제품은 STT API 선택 문제가 아니라 데이터 구조 설계 문제다. 긴 오디오를 speaker/timestamp/context와 함께 저장하는 순간, 후속 LLM 워크플로의 품질이 달라진다.
둘째, 오픈소스 음성 모델도 서빙 표면이 중요해지고 있다. Transformers와 vLLM 지원은 모델 접근성을 크게 바꾼다. 특히 이미 LLM serving을 운영하는 팀이라면 음성 모델도 같은 observability와 queue, billing, policy 레이어에 올리는 그림을 그릴 수 있다.
셋째, 한국어 제품에서는 hotword와 fine-tuning이 차별화 포인트가 된다. 일반 한국어 인식률보다 실제 고객명, 제품명, 내부 용어를 얼마나 덜 틀리는지가 더 중요할 때가 많다.
넷째, 음성은 agent의 좋은 입력 레이어가 된다. 회의·통화·강의·인터뷰가 구조화되면, 다음 단계의 agent는 단순 요약을 넘어 follow-up 작성, 이슈 생성, 고객 신호 추출, 코칭, 리서치 메모 생성까지 할 수 있다. 이때 ASR은 단순 전처리가 아니라 agent workflow의 첫 번째 기억 장치에 가깝다.
결론: VibeVoice ASR은 “오픈소스 Whisper 대체재”보다 큰 신호다
VibeVoice-ASR을 단순히 “Microsoft가 만든 오픈소스 음성 인식 모델”로만 보면 핵심을 놓친다. 더 중요한 건 60분 single-pass, speaker/timestamp 구조화, hotword, Transformers 호환, vLLM 배포, LoRA fine-tuning이 한 방향을 가리킨다는 점이다.
그 방향은 긴 음성을 AI 제품의 구조화된 입력 데이터로 바꾸는 런타임이다. 한국 개발팀이 회의록, 콜 분석, 교육, 리서치, 고객 인터뷰, 내부 지식화 제품을 만든다면 이 흐름은 꽤 중요하다. 앞으로의 경쟁은 “말을 얼마나 잘 받아쓰는가”를 넘어, “긴 대화 전체를 얼마나 덜 손상시키고 다음 AI 워크플로로 넘기는가”에서 갈릴 가능성이 크다.