- Published on
Microsoft pg_durable: AI 워크플로를 Postgres 안으로 당기는 durable execution의 의미
- Authors

- Name
- Kyunghyun Park
- @devkhpark
Microsoft · pg_durable · PostgreSQL durable execution · AI workflow infrastructure
Microsoft의 pg_durable이 GitHub Trending에 오른 건 단순한 데이터베이스 확장 하나가 주목받았다는 의미를 넘는다. 이 프로젝트가 던지는 질문은 꽤 실용적이다. AI 파이프라인과 백그라운드 작업의 상태가 이미 Postgres에 있다면, 왜 워크플로 상태만 꼭 외부 오케스트레이터·큐·워커로 흩어져야 하는가?

pg_durable의 핵심은 “Postgres에서 오래 걸리는 SQL을 실행한다”가 아니다. README는 이 확장을 PostgreSQL inside durable execution이라고 설명한다. SQL로 워크플로 그래프를 정의하고, 각 단계를 체크포인트로 남기며, 재시작·실패·긴 대기 이후에도 마지막 성공 지점부터 이어가게 만드는 방식이다. Microsoft는 이 흐름을 “compute close to data”라는 방향과 연결하고, Azure HorizonDB에도 pg_durable이 들어간다고 안내한다.
기준 시점: 이 글은 2026-06-08에 확인한 Microsoft pg_durable GitHub README, GitHub 저장소 메타데이터,
docs/SCENARIOS.md,docs/ARCHITECTURE.md,docs/api-reference.md,docs/http-security.md,docs/pg_durable_spec.md기준이다. 확장 API, 지원 PostgreSQL 버전, HTTP feature flag, Azure HorizonDB 제공 형태는 빠르게 바뀔 수 있으니 실제 적용 전 원문을 다시 확인해야 한다.
왜 AI 팀이 Postgres durable execution을 봐야 하나
AI 제품의 백엔드는 겉으로는 모델 호출이 전부인 것처럼 보이지만, 실제 운영 병목은 대개 그 주변에 있다.
- 문서를 받아 chunk로 나누고 embedding을 만든다.
- 각 chunk를
pgvector나 검색 인덱스에 upsert한다. - 실패한 API 호출은 재시도하되, 이미 성공한 chunk는 다시 처리하지 않는다.
- 긴 배치 중간에 서버가 재시작되어도 어느 문서까지 처리했는지 보존해야 한다.
- 결과 상태를 대시보드, 고객 지원, 운영 runbook에서 바로 조회해야 한다.
이런 작업은 “한 번의 요청-응답”이 아니다. 오래 걸리고, 실패하고, 재시작되고, 부분 성공을 남긴다. 그래서 많은 팀은 pg_cron, jobs table, queue, worker, retry counter, Airflow, Temporal, Step Functions 같은 조합을 붙인다. 문제는 시간이 지나면 워크플로의 진짜 상태가 여러 시스템에 퍼진다는 점이다.
pg_durable은 이 문제를 반대로 푼다. 상태가 Postgres에 있다면 워크플로도 Postgres에 두자는 것이다. README는 특히 vector embedding pipelines, ingest pipelines, scheduled maintenance, fan-out aggregation, external API workflows를 예시로 든다. AI 팀이 읽어야 할 대목은 바로 여기다. RAG·에이전트·문서 처리 제품에서 가장 흔한 백그라운드 작업이 pg_durable의 1차 타깃에 들어간다.
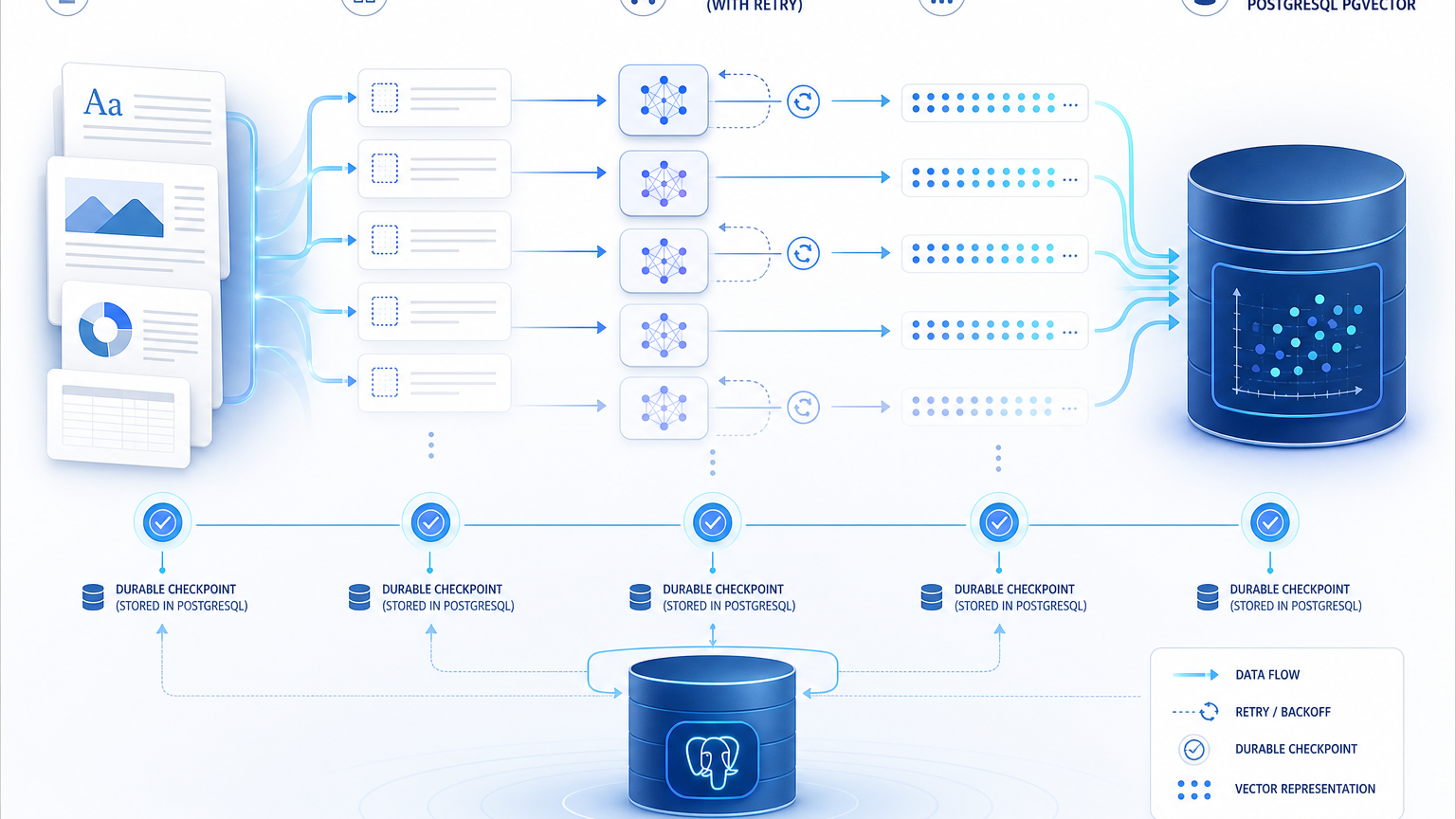
핵심 아이디어: SQL 함수가 아니라 체크포인트가 있는 워크플로 그래프
pg_durable의 API를 보면 접근 방식이 선명하다. 사용자는 df.start(...)로 durable function을 시작하고, ~> 연산자로 순차 실행을 만들고, & 또는 df.join(...)으로 병렬 실행을 만들고, |=>로 결과를 변수에 바인딩한다. API reference는 plain SQL string이 자동으로 df.sql() node로 감싸지는 auto-wrap 규칙도 설명한다.
예를 들어 단순한 SQL 한 줄을 실행하는 것과 durable workflow를 실행하는 것은 다르다.
SELECT df.start('SELECT 1');
이 호출은 단순히 현재 세션에서 쿼리를 실행하는 게 아니다. df.start()가 instance를 만들고, background worker가 작업을 집어 들고, 상태와 결과를 df.list_instances(), df.status(), df.result() 같은 함수로 조회할 수 있게 만든다. docs/SCENARIOS.md는 connection drop, crash, PostgreSQL restart 이후에도 함수 상태를 추적할 수 있는 패턴으로 소개한다.
아키텍처 문서는 이 과정을 두 단계로 나눈다.
- Graph construction — 사용자 트랜잭션에서 DSL 함수와 SQL operator가
df.nodes에 노드를 만들고df.start()가 instance를 생성한다. - Graph execution — background worker가 orchestration을 집어 들고, node를 실행하고, 각 SQL activity를 checkpoint한다.
여기서 중요한 건 “SQL을 더 길게 쓴다”가 아니라 작업 단위가 그래프와 체크포인트로 승격된다는 점이다. AI 파이프라인으로 치면 “문서 10만 개를 처리하는 스크립트”가 아니라 “각 문서·chunk·API 호출·upsert 단계가 복구 가능한 실행 그래프”가 된다.
기존 방식과 다른 점: glue code를 줄이는 대신 데이터베이스 책임이 커진다
대부분의 팀은 백그라운드 작업을 이렇게 만든다.
- Postgres에 jobs table을 만든다.
- queue에 job id를 넣는다.
- worker가 job을 꺼내 처리한다.
- 실패하면 retry counter를 올린다.
- 중간 산출물과 상태를 또 다른 테이블에 적는다.
- 운영자는 queue, worker log, database row를 함께 봐야 한다.
이 방식은 나쁘지 않다. 다만 작은 팀이나 데이터베이스 중심 제품에서는 glue code가 빠르게 커진다. 특히 AI 제품은 외부 모델 API, rate limit, 긴 inference, chunk 단위 부분 실패가 많아서 retry와 idempotency 코드가 제품 코드보다 길어지는 경우가 흔하다.
pg_durable은 이 중 일부를 데이터베이스 안으로 당긴다. README가 말하듯 workflow definition은 SQL로 이동하고, retry state·progress tracking·checkpointing은 bespoke app code 대신 Postgres 내부 상태로 남는다. 운영자는 df.instances 같은 테이블과 SQL view를 통해 상태를 조회한다.
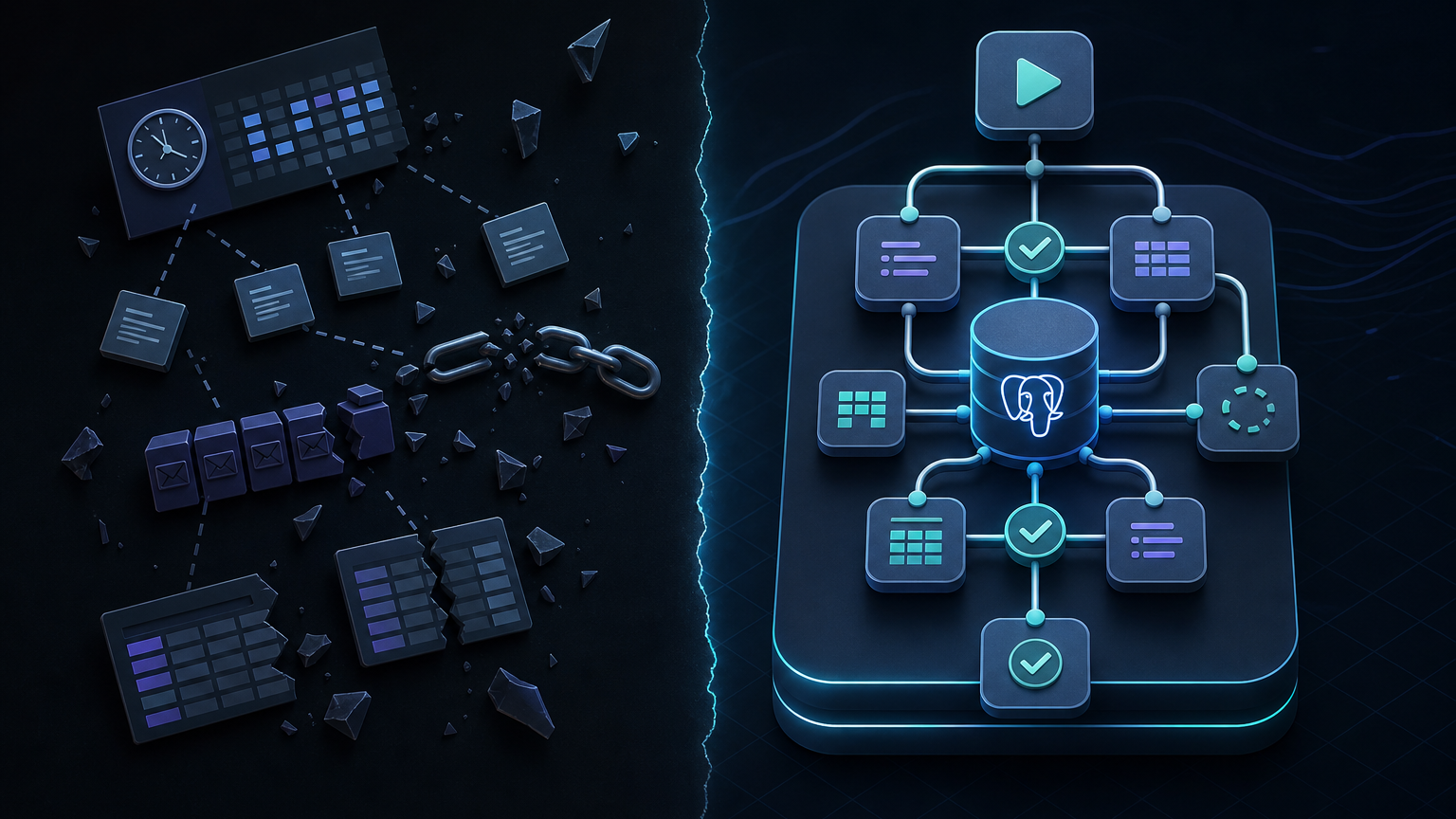
하지만 이건 공짜가 아니다. 책임이 앱 계층에서 데이터베이스 계층으로 이동한다. 확장을 설치할 수 있어야 하고, background worker를 운영할 수 있어야 하며, 데이터베이스가 단순 저장소가 아니라 실행 런타임 일부가 된다. 그래서 pg_durable은 모든 워크플로의 대체재라기보다 Postgres에 강하게 붙은 작업을 위한 선택지로 보는 편이 맞다.
AI embedding·RAG ingest에서 특히 잘 맞는 이유
가장 현실적인 적용처는 embedding pipeline이다. 문서 ingest 제품을 예로 들어보자.
documents테이블에 원문이 들어온다.chunks테이블에 분할 결과를 저장한다.- 각 chunk에 대해 embedding API를 호출한다.
- 결과 vector를
pgvector컬럼에 upsert한다. - 실패 chunk만 재시도한다.
- 작업 상태를 고객에게 보여준다.
이 작업의 source of truth는 이미 Postgres다. 그런데 워크플로 실행 상태가 외부 queue와 worker log에만 있으면 운영자는 “문서 row는 있는데 embedding은 왜 비었나”, “몇 번째 chunk에서 실패했나”, “재시도하면 중복 upsert가 생기나”를 계속 추적해야 한다.
pg_durable의 장점은 이런 상태를 SQL로 관찰할 수 있다는 점이다. docs/SCENARIOS.md는 ETL pipeline, scheduled data sync, parallel aggregation 같은 패턴을 제공한다. 이 패턴을 AI 쪽으로 옮기면 다음 의미가 된다.
- document-level workflow를
df.start()로 시작한다. - chunking, embedding, upsert, 검증을 순차 node로 나눈다.
- 독립 chunk는 병렬 branch로 처리한다.
- 실패한 node부터 재시작한다.
- 결과와 상태를 같은 데이터베이스에서 audit한다.
이건 “모델을 더 똑똑하게 만드는 기술”은 아니다. 대신 AI 제품이 실제 고객 데이터 위에서 굴러갈 때 필요한 운영 신뢰성 계층이다.
외부 API 호출과 보안: agent 워크플로에는 특히 조심해야 한다
AI 워크플로가 Postgres 안에 들어오면 바로 따라오는 질문이 있다. 외부 API 호출은 어떻게 할 것인가? embedding API, classification API, webhook, 내부 서비스 호출이 필요하기 때문이다.
pg_durable의 docs/http-security.md는 이 지점을 꽤 명시적으로 다룬다. df.http()는 build-time Cargo feature로 제어된다. 기본은 비활성화이며, production 성격의 http-allow-azure-domains, 테스트용 http-allow-test-domains, 로컬 개발용 http-allow-all 같은 선택지가 있다. 문서는 SSRF 방지를 위한 private/reserved IP blocklist, endpoint allow-list, PostgreSQL privilege check, audit logging을 설명한다.
이 설계는 AI agent 관점에서 중요하다. 데이터베이스 안에 “외부 HTTP 호출이 가능한 durable workflow”를 넣는 순간, 편의성과 위험이 동시에 커진다. embedding pipeline에는 유용하지만, 잘못 열면 데이터베이스가 내부망 호출 프록시처럼 악용될 수 있다. 그래서 pg_durable을 에이전트 워크플로에 붙일 때는 모델 성능보다 운영 정책이 먼저다.

실무 체크리스트는 단순하다.
- HTTP feature flag를 환경별로 분리한다.
- allow-list 없는
http-allow-all을 production에 쓰지 않는다. df.http()실행 권한을 역할별로 제한한다.- workflow input에 URL을 직접 받는 경우 SSRF·redirect·DNS rebinding을 검토한다.
- 결과와 실패 로그를 운영 대시보드에 노출한다.
AI 팀이 놓치기 쉬운 건 “워크플로 자동화”가 곧 “권한 자동화”라는 사실이다. pg_durable은 편리한 도구지만, HTTP와 agent loop를 붙이는 순간 보안 모델까지 같이 설계해야 한다.
Temporal, Airflow, Step Functions를 대체하나?
짧게 말하면 일부는 그렇고, 전부는 아니다.
pg_durable이 강한 곳은 데이터베이스 중심의 long-running workflow다. 상태가 Postgres에 있고, 주요 단계가 SQL 또는 Postgres 주변 작업이며, 운영자가 SQL로 관찰하고 싶은 경우에는 외부 오케스트레이터보다 간단할 수 있다. 특히 작은 팀이 AI ingest·embedding·분석 배치를 운영할 때는 queue와 worker를 따로 세우는 비용을 줄일 수 있다.
반대로 아래 조건에서는 기존 오케스트레이터가 더 자연스럽다.
- 워크플로가 여러 클라우드 서비스와 이질적 런타임을 넓게 오간다.
- 복잡한 애플리케이션 로직이 많고 SQL DSL로 표현하기 어렵다.
- 이미 Temporal/Airflow/Argo 운영 체계가 성숙하다.
- 데이터베이스에 확장과 background worker를 추가할 수 없다.
- 요청 지연시간이 밀리초 단위로 민감한 synchronous path다.
README도 비슷한 선을 긋는다. 단일 INSERT ... SELECT로 끝나는 작업, sub-millisecond synchronous request handling, 확장을 설치할 수 없는 환경, 대부분의 workflow가 Postgres 밖에 있는 경우에는 맞지 않는다고 설명한다.
즉 pg_durable은 “모든 워크플로를 SQL로 바꾸자”가 아니다. 더 정확한 메시지는 이렇다. 데이터에 붙은 AI 작업은 데이터베이스 밖으로 너무 빨리 밀어내지 말자.
실무 적용 전에 봐야 할 리스크
pg_durable은 흥미롭지만, 바로 production에 넣기 전에 봐야 할 지점이 있다.
첫째, 지원 환경이다. README는 PostgreSQL 17 & 18을 배지로 표시한다. 현재 운영 중인 managed Postgres가 확장 설치와 background worker를 허용하는지 확인해야 한다. RDS나 Cloud SQL 같은 환경에서는 확장 허용 여부가 가장 큰 제약이 될 수 있다.
둘째, 장애 도메인이다. 워크플로 상태와 데이터 상태가 같은 Postgres에 있는 건 장점이지만, 동시에 Postgres가 더 많은 책임을 진다는 뜻이다. 백업·복구·replication·failover 테스트를 workflow까지 포함해 해야 한다.
셋째, 개발자 경험이다. SQL-native workflow는 데이터 엔지니어에게는 자연스럽지만, 일반 애플리케이션 개발자에게는 낯설 수 있다. API reference가 제공하는 ~>, &, |=>, df.if, df.race, df.sleep, df.wait_for_signal 같은 DSL을 팀이 읽고 유지보수할 수 있어야 한다.
넷째, 관찰성이다. df.list_instances()와 상태 테이블은 시작점일 뿐이다. 실제 제품에서는 실패 사유, retry 횟수, stuck workflow, 외부 API latency, 비용 추적까지 대시보드로 연결해야 한다.
실무 해석: AI 인프라는 모델보다 “상태 관리”에서 차별화된다
요즘 AI 인프라 논의는 자주 모델, context window, agent capability로 쏠린다. 하지만 제품을 운영해보면 더 지루한 문제가 더 자주 터진다.
- 같은 문서가 두 번 embedding된다.
- 중간 실패 후 재시도하면 vector row가 꼬인다.
- 고객은 “처리 중” 화면만 보고 있고 운영자는 어느 단계인지 모른다.
- 모델 API rate limit 때문에 일부 chunk만 빠진다.
- worker가 죽었는데 queue에는 완료처럼 남는다.
pg_durable이 흥미로운 이유는 이 지루한 문제를 정면으로 본다는 점이다. AI 워크플로의 본질은 “모델 호출”이 아니라 상태가 있는 긴 작업을 안전하게 끝내는 것이다. 그리고 많은 AI 제품에서 그 상태는 이미 Postgres에 있다.
그래서 pg_durable은 당장 모든 팀이 도입해야 할 필수 기술이라기보다, 앞으로 AI backend 설계에서 자주 등장할 질문의 한 사례다. “워크플로 상태를 어디에 둘 것인가?” “데이터 가까이 compute를 두면 무엇이 단순해지는가?” “agent와 외부 API 호출을 데이터베이스 안으로 당길 때 보안 경계는 어떻게 잡을 것인가?”
결론: pg_durable은 Postgres를 AI 작업의 운영 런타임으로 보는 신호다
Microsoft pg_durable의 메시지는 꽤 선명하다. 데이터베이스는 더 이상 단순 저장소만이 아니다. 적어도 Postgres 중심의 제품에서는 장기 실행 작업, 재시도, 체크포인트, 병렬 실행, 외부 호출, audit까지 일부를 데이터베이스 가까이에 둘 수 있다.
한국 개발팀에게 실용적인 takeaway는 세 가지다.
- RAG·embedding·문서 ingest처럼 Postgres에 붙은 AI 작업은 durable execution 후보로 본다.
- 큐와 워커를 없애는 게 목표가 아니라, 상태가 흩어지는 비용을 줄이는 게 목표다.
- HTTP 호출과 agent loop를 붙일 때는 feature flag, allow-list, 권한, audit을 먼저 설계한다.
pg_durable은 아직 성숙도를 검증해야 할 영역이 많다. 그래도 방향은 중요하다. AI 인프라의 다음 병목은 모델 호출 자체보다, 그 호출 전후의 상태·재시도·복구·감사 가능성일 가능성이 크다. pg_durable은 그 병목을 Postgres 안에서 풀어보려는 꽤 직접적인 시도다.