- Published on
LMCache가 보여주는 LLM 서빙의 새 병목: KV 캐시는 비용 구조다
- Authors

- Name
- Kyunghyun Park
- @devkhpark
키워드: LMCache · KV cache · LLM inference · vLLM · agent serving economics
이번 글의 결론은 간단하다. LLM 제품의 비용 병목은 점점 “어떤 모델을 쓰느냐”에서 “이미 계산한 컨텍스트를 얼마나 잘 재사용하느냐”로 내려가고 있다. GitHub Trending에 올라온 LMCache/LMCache는 이 변화를 꽤 선명하게 보여준다.
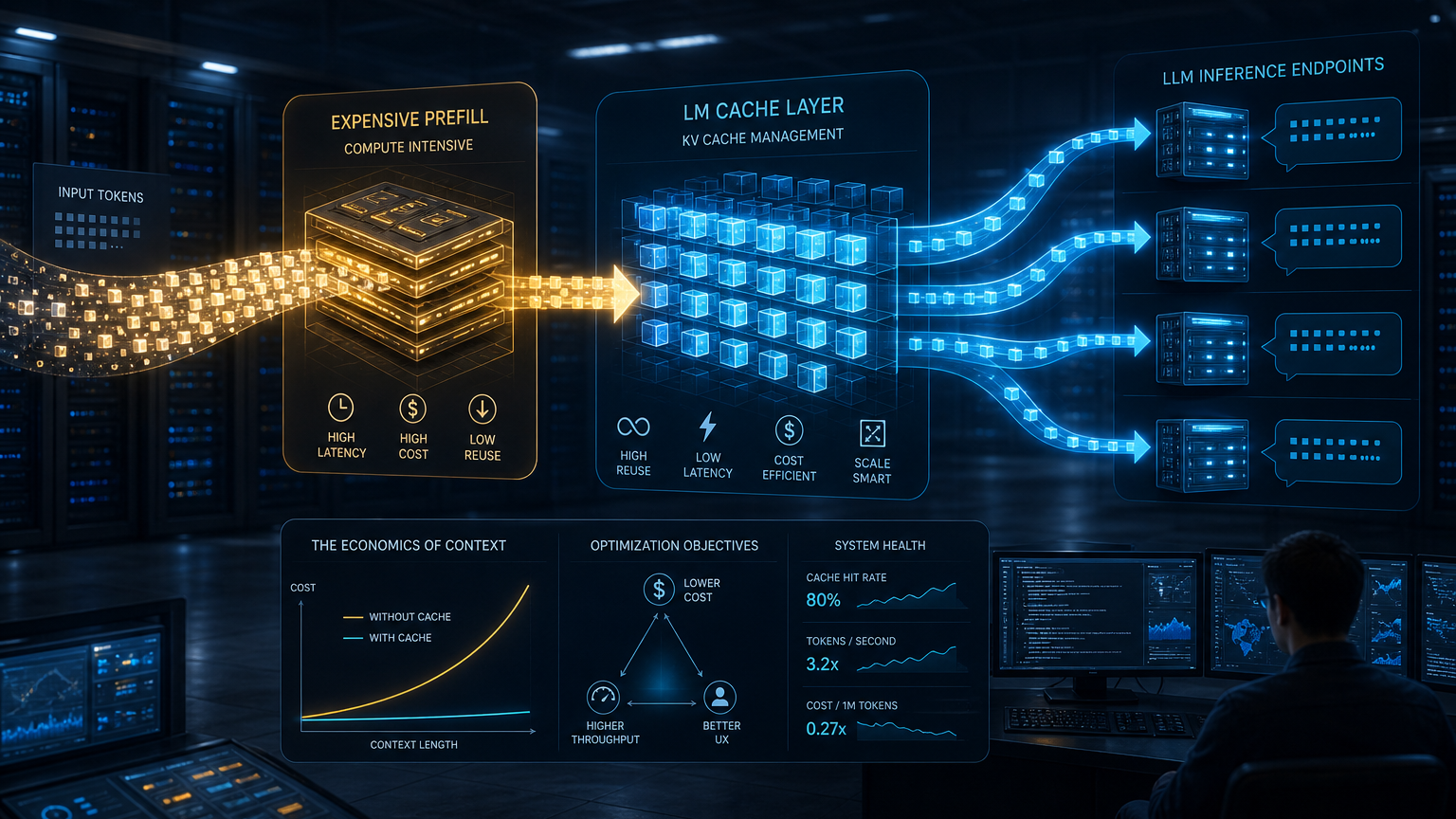
LMCache README는 이 프로젝트를 “A KV Cache Management Layer for Scalable LLM Inference”라고 설명한다. 저장소 메타데이터만 보면 Python 기반 오픈소스 추론 도구이고, 토픽도 kv-cache, vllm, inference, cuda, rocm처럼 익숙하다. 하지만 핵심은 더 실무적이다. LMCache 문서는 “LLM이 각 텍스트를 한 번만 prefill하게 하고, 재사용 가능한 텍스트의 KV cache를 저장해 serving engine instance 전반에서 다시 쓴다”고 설명한다. 공식 문서의 표현을 빌리면 이 방식은 prefill delay, 즉 time to first token(TTFT)을 줄이고 GPU cycle과 메모리를 아낀다.
이건 검색 키워드 관점에서도 좋다. “LLM inference optimization”, “KV cache”, “vLLM prefix caching”, “agent serving cost”를 찾는 개발자들은 대체로 모델 리뷰가 아니라 운영 해법을 원한다. 답해야 할 질문은 “LMCache가 빠르다더라”가 아니라, 어떤 워크로드에서 캐시 계층을 따로 운영할 만큼 효과가 생기는가다.
왜 지금 KV 캐시인가
Transformer 추론에서 prefill은 입력 토큰을 읽고 attention에 필요한 key/value 상태를 만드는 단계다. 짧은 단발성 요청만 있다면 이 비용은 그냥 요청 비용의 일부로 보인다. 하지만 실제 AI 제품은 점점 그렇지 않다.
- 에이전트는 같은 시스템 프롬프트, 툴 설명, 프로젝트 컨텍스트를 여러 턴에 걸쳐 반복해서 읽는다.
- RAG 서비스는 같은 문서 조각이나 긴 정책 문서를 여러 사용자 요청에 붙인다.
- 코딩 에이전트는 repository map, 작업 지침, 이전 실행 결과를 반복적으로 컨텍스트에 넣는다.
- 멀티턴 분석 도구는 대화가 길어질수록 “새 질문”보다 “이미 넣은 긴 배경”이 더 커진다.
이때 병목은 모델이 답변 토큰을 생성하는 decode만이 아니다. 같은 긴 입력을 다시 prefill하는 비용이 누적된다. vLLM도 Automatic Prefix Caching을 통해 이전 요청의 KV cache를 재사용하는 기능을 문서화하고 있다. 다만 prefix caching이라는 이름 그대로, 기본적으로는 같은 prefix가 반복되는 패턴을 강하게 전제한다.
LMCache의 포인트는 여기서 한 단계 더 나간다. 공식 문서 첫 페이지는 LMCache가 “not necessarily prefix”인 재사용 텍스트의 KV cache까지 serving engine instance 전반에서 재사용할 수 있다고 설명한다. 즉 단순한 per-process prefix cache가 아니라, 여러 추론 엔진 사이에 놓이는 KV cache management layer로 포지셔닝한다.

LMCache가 실제로 추가하는 운영 표면
LMCache Quickstart를 보면 제품 방향이 더 분명하다. vLLM과 함께 쓸 때 두 가지 모드가 나온다.
첫째는 in-process mode다. LMCacheConnectorV1을 통해 vLLM 프로세스 안에서 LMCache를 붙이는 방식이다. 빠르게 실험하기에는 편하다.
둘째는 문서가 추천하는 multiprocess(MP) mode다. 이 경우 LMCache는 별도 서버로 뜨고, vLLM은 LMCacheMPConnector로 붙는다. Quickstart는 lmcache server --l1-size-gb 20 --eviction-policy LRU --chunk-size 16 같은 예시를 보여주고, vLLM 쪽에서는 --kv-transfer-config로 connector와 role을 지정한다. ZMQ 포트는 vLLM과의 연결에 쓰이고, HTTP frontend는 management와 metrics endpoint를 제공한다.
이 차이가 중요하다. in-process cache는 라이브러리 기능에 가깝지만, MP mode는 운영 컴포넌트다. 별도 프로세스, 캐시 용량, eviction policy, observability, 여러 engine instance 간 공유가 생긴다. 즉 팀은 이제 “모델 서버를 몇 개 띄울까”만이 아니라 “캐시 서버를 어디에 두고, 얼마를 할당하고, 어떤 요청을 캐시할까”를 설계해야 한다.

공식 문서의 수치도 공격적이다. LMCache 문서는 vLLM과 결합하면 multi-round QA와 RAG를 포함한 여러 LLM use case에서 3-10배 delay saving과 GPU cycle reduction을 얻을 수 있다고 말한다. 물론 모든 워크로드에서 이 숫자가 그대로 나오지는 않는다. 하지만 방향은 명확하다. 컨텍스트 재사용률이 높은 서비스에서는 캐시 히트율이 곧 GPU 비용과 사용자 체감 지연시간으로 연결된다.
에이전트 워크로드에서 의미가 커지는 이유
LMCache README의 업데이트 내역도 흥미롭다. 2026년 5월 항목으로 “Agentic workload benchmark on AMD MI300X”가 걸려 있고, 해당 블로그는 739개의 익명화된 Claude Code conversation trace를 사용해 multi-turn agentic workload를 벤치마크했다고 설명한다. 환경은 MiniMax-M2.5, vLLM 0.19.0, LMCache, 2× AMD MI300X 조합이었다.
이 지점이 중요하다. LLM 서빙 벤치마크는 오래전부터 있었지만, 에이전트 워크로드는 일반 챗봇과 다르다. 요청 하나가 독립적으로 끝나지 않고, 같은 작업 상태가 여러 번 재사용된다. 도구 호출 후 다시 판단하고, 파일을 읽은 뒤 계획을 수정하고, 실패하면 같은 컨텍스트를 붙잡고 재시도한다. 이 구조에서는 “앞부분을 또 읽는 비용”이 계속 새어 나간다.
LMCache식 캐시 계층은 이 누수를 줄이는 방향이다. 특히 다음 패턴에서 효과가 크다.
| 워크로드 | 캐시가 잘 맞는 이유 | 주의점 |
|---|---|---|
| 코딩 에이전트 | 시스템 지침, repo map, 작업 로그가 여러 턴에서 반복된다 | 파일 변경 후 stale context를 어떻게 무효화할지 필요하다 |
| RAG QA | 같은 문서·정책·매뉴얼 조각이 여러 요청에 재등장한다 | retrieval 결과가 너무 매번 달라지면 hit rate가 낮다 |
| 고객지원/운영 copilot | 제품 정책, 고객 tier, 내부 절차가 반복된다 | 개인정보·권한 경계가 캐시에 섞이면 위험하다 |
| 긴 분석 세션 | 대화 초반의 긴 배경이 계속 prefix/near-prefix로 유지된다 | 요약·압축 정책과 함께 설계해야 한다 |
반대로 일회성 짧은 요청, 사용자별로 완전히 다른 문맥, 혹은 매우 민감해서 공유 캐시에 넣기 어려운 데이터가 중심이라면 캐시 계층의 복잡도가 이득을 먹어버릴 수 있다. KV cache는 공짜 최적화가 아니라 상태ful infrastructure다.
vLLM prefix caching과 어떻게 봐야 하나
여기서 “vLLM에도 automatic prefix caching이 있는데 왜 LMCache가 필요한가?”라는 질문이 자연스럽다. 답은 둘 중 하나를 고르는 문제가 아니라 계층을 나눠 보는 쪽에 가깝다.
vLLM의 prefix caching은 serving engine 내부 최적화로 이해하기 좋다. 같은 prefix가 반복되면 이미 계산된 KV block을 재사용해 prefill 비용을 줄인다. vLLM의 설계 문서도 block 단위 prefix caching과 해시 기반 lookup을 설명한다.
LMCache는 그 위나 옆에 놓이는 cache management layer다. Quickstart에서 MP mode를 추천하고, 여러 vLLM engine instance가 별도 LMCache server에 붙는 구조를 보여주는 이유가 여기에 있다. 한 프로세스 안에서 히트하는 캐시가 아니라, 여러 엔진과 저장 계층을 걸친 재사용 문제로 확장한다.
한국 팀에게 실무적으로는 이렇게 정리할 수 있다.
- 단일 vLLM 서버에서 반복 prefix가 많은지 먼저 측정한다.
- prefix caching으로 TTFT가 얼마나 줄어드는지 본다.
- 여러 replica, 여러 GPU node, RAG/agent 세션이 섞이면서 같은 컨텍스트를 다시 prefill하는 비용이 커지면 LMCache 같은 외부 캐시 계층을 검토한다.
- 캐시 히트율, eviction, 개인정보 경계, tenant isolation, invalidation policy를 모델 선택만큼 중요하게 운영한다.
실무 해석: 캐시 히트율이 LLM 제품의 unit economics가 된다
많은 팀이 LLM 비용을 볼 때 아직도 “input token 가격 × output token 가격”으로만 계산한다. 이 계산은 API 소비자 입장에서는 맞지만, 자체 서빙이나 high-volume agent product를 운영하는 팀에게는 부족하다. 실제 비용은 다음 항목으로 갈라진다.
- prefill이 얼마나 반복되는가
- decode가 얼마나 오래 이어지는가
- 같은 컨텍스트가 한 프로세스 안에서만 반복되는가, 여러 replica에서 반복되는가
- 캐시를 GPU memory에 둘지, CPU memory에 둘지, disk/object storage까지 내릴지
- 캐시 miss가 사용자 지연시간에 얼마나 민감하게 드러나는가
- 캐시된 상태가 보안·권한·데이터 보존 정책을 위반하지 않는가
LMCache가 흥미로운 이유는 이 질문들을 제품 표면으로 끌어올린다는 점이다. 단순히 “모델이 빠르다”가 아니라 “prefill을 한 번만 하게 만들고, 재사용 가능한 KV를 운영 자산으로 다루자”는 접근이다.
특히 한국 스타트업이나 내부 AI 플랫폼 팀이라면 당장 세 가지를 해볼 만하다.
- 로그를 먼저 바꿔라. 요청별 input/output token만 보지 말고, 재사용 가능한 prompt segment, RAG chunk, system prompt version, session id를 별도 차원으로 남긴다.
- 워크로드를 분류하라. 고객지원 챗봇, 코딩 에이전트, 문서 QA, 리포트 생성은 캐시 이득이 다르다. “전체 평균 latency” 하나로 보면 신호가 묻힌다.
- 캐시를 보안 설계에 넣어라. KV cache는 원문 텍스트는 아니지만 모델 내부 상태다. tenant 간 공유, 민감 데이터 보존, invalidation 정책을 나중에 붙이면 늦다.
SEO 관점에서의 포지션
이 주제는 한국어로 아직 얇다. “vLLM 사용법”이나 “LLM 추론 최적화” 글은 늘고 있지만, KV cache를 제품 비용 구조와 에이전트 워크로드 관점에서 설명한 글은 많지 않다. 그래서 이 글의 타깃 검색 의도는 아래에 가깝다.
- LMCache란 무엇인가
- LLM KV cache가 왜 중요한가
- vLLM prefix caching과 LMCache 차이
- RAG/agent 서비스에서 TTFT 줄이는 법
- 자체 LLM 서빙 비용 최적화 체크리스트
여기서 중요한 건 도구 소개로 끝내지 않는 것이다. LMCache가 오늘 Trending에 올랐다는 사실은 신호일 뿐이다. 더 큰 흐름은 LLM serving stack이 점점 CDN, cache, observability, policy가 붙은 웹 인프라처럼 변하고 있다는 점이다. 모델 API만 호출하던 팀도, 제품 규모가 커지면 결국 이 레이어를 이해해야 한다.
결론
LMCache는 “빠른 KV cache 라이브러리”보다 “LLM 제품의 반복 컨텍스트 비용을 운영 가능한 계층으로 분리하려는 시도”로 보는 편이 맞다. vLLM prefix caching이 엔진 내부의 좋은 출발점이라면, LMCache의 MP mode와 cache management layer는 여러 엔진·여러 워크로드·여러 저장 계층으로 문제가 커질 때 필요한 다음 단계다.
지금 당장 모든 팀이 LMCache를 붙일 필요는 없다. 하지만 RAG, 코딩 에이전트, 내부 copilot, 장문 분석 제품을 운영한다면 한 가지 질문은 던져야 한다.
우리 서비스는 같은 컨텍스트를 몇 번이나 다시 prefill하고 있는가?
이 질문에 답하지 못하면, 모델을 바꿔도 비용은 계속 샌다. 반대로 답할 수 있다면, 다음 최적화는 모델 교체가 아니라 캐시 히트율을 제품 지표로 올리는 것일 수 있다.