- Published on
Alibaba Zvec: RAG 벡터 DB가 서버에서 앱 안으로 들어올 때 생기는 변화
- Authors

- Name
- Kyunghyun Park
- @devkhpark
Alibaba Zvec · 인프로세스 벡터 데이터베이스 · RAG · 에이전트 메모리 · 하이브리드 검색
AI 앱을 만들 때 벡터 데이터베이스는 보통 “따로 띄우는 인프라”로 취급됐다. 임베딩을 만들고, 외부 벡터 DB에 넣고, 검색 API를 호출하고, 그 결과를 다시 LLM 프롬프트에 붙이는 식이다. 이 구조는 확장성과 운영 분리를 주지만, 작은 팀이나 제품 초기 단계에서는 꽤 무겁다. 별도 서버, 네트워크 왕복, 스키마 관리, 인덱스 튜닝, 백업, 권한, 관측성까지 한꺼번에 따라오기 때문이다.
Alibaba의 Zvec는 이 전제를 살짝 뒤집는다. README는 Zvec를 open-source, in-process vector database라고 소개한다. 즉 “벡터 검색 서버를 하나 더 붙인다”가 아니라, 애플리케이션 안에 직접 임베드되는 벡터 검색 런타임에 가깝다. 2026년 6월 12일 공개된 v0.5.0 릴리스는 여기에 full-text search, hybrid retrieval, DiskANN, Go/Rust SDK, Zvec Studio까지 더했다.

이 글의 결론부터 말하면 이렇다. Zvec의 의미는 “또 하나의 벡터 DB”가 아니라, RAG와 에이전트 메모리를 제품 코드 가까이 끌어오는 설계 신호다. 모든 팀이 당장 외부 벡터 DB를 버려야 한다는 뜻은 아니다. 다만 로컬 우선, 저지연, 엣지 배포, 프라이버시, 작은 팀의 운영비 절감이 중요한 제품이라면 이제 선택지가 조금 더 선명해졌다.
기준 시점: 이 글은 2026-06-17에 확인한 Zvec GitHub README, v0.5.0 릴리스 노트, 공식 문서, GitHub API 메타데이터를 기준으로 작성했다. 벤치마크와 API는 빠르게 바뀔 수 있으니 실제 도입 전 공식 문서를 다시 확인해야 한다.
왜 지금 Zvec를 볼 만한가: 벡터 DB의 중심축이 “클러스터”만은 아니게 됐다
Zvec 저장소의 설명은 간단하다. “A lightweight, lightning-fast, in-process vector database.” GitHub API 기준으로 저장소는 Python/C++ 기반의 Apache-2.0 프로젝트이고, README는 Alibaba Group 내부에서 production-grade, low-latency similarity search로 battle-tested됐다고 설명한다. 저장소 구조도 단순한 데모가 아니다. src/, python/, examples/, tests/, thirdparty/, tools/가 있고, PyPI와 npm 배포 배지, Go/Rust SDK 언급, Zvec Studio 같은 보조 도구가 붙어 있다.
이런 프로젝트가 의미 있는 이유는 벡터 검색이 이제 AI 앱의 “부가 기능”이 아니라 기본 실행 경로에 들어왔기 때문이다. RAG, semantic search, 추천, long-term memory, agent workspace search, customer support retrieval, multimodal asset search는 모두 검색 지연시간과 운영 안정성에 민감하다. 벡터 DB가 외부 서비스로만 존재하면 제품팀은 매번 아래 비용을 감수해야 한다.
- 애플리케이션과 검색 서버 사이의 네트워크 왕복
- 별도 배포 단위와 장애 지점
- 작은 데이터셋에도 필요한 클러스터 운영 습관
- 개발·테스트·온프레미스·엣지 환경에서의 재현성 문제
- 개인정보나 사내 문서가 외부 관리형 서비스로 나가는 정책 리스크
인프로세스 벡터 DB는 이 중 일부를 줄인다. 검색 엔진이 앱 프로세스 안으로 들어오면 설치와 배포는 단순해지고, 작은 규모에서는 지연시간과 운영 복잡도가 낮아진다. 특히 “회사 전체 검색 플랫폼”이 아니라 “제품 기능 하나에 붙는 RAG 인덱스”라면 이 차이가 꽤 크다.
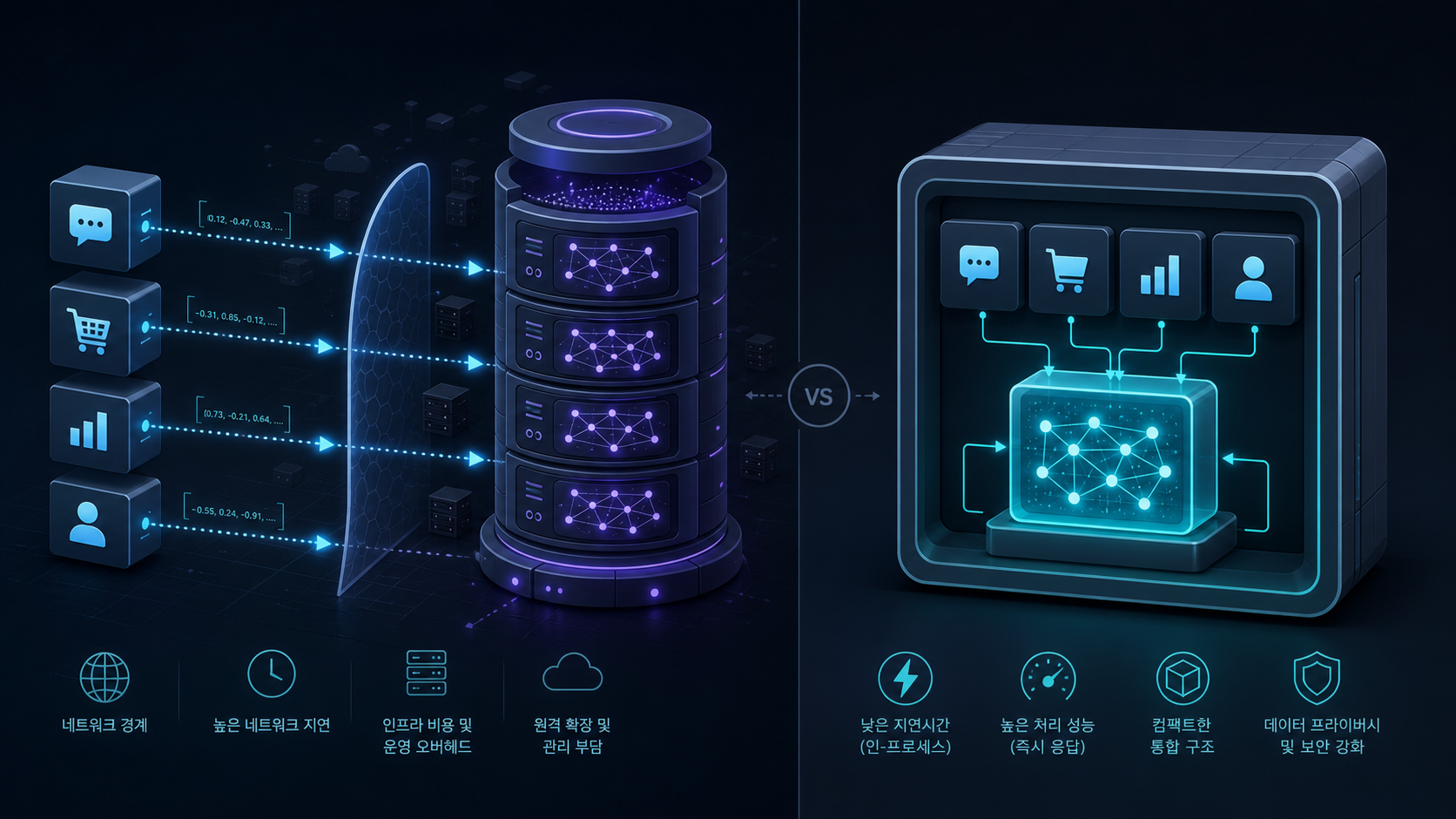
물론 이건 만능 해법이 아니다. 인프로세스 구조는 프로세스 리소스, 파일 시스템, 락, 백업, 멀티테넌시, 동시성, 장애 격리 같은 문제를 앱 쪽으로 끌고 온다. 큰 조직에서 이미 Milvus, Pinecone, Weaviate, Elasticsearch 계열 인프라를 운영하고 있다면 외부 서비스가 더 낫다. 하지만 모든 RAG가 “별도 벡터 DB 클러스터”를 필요로 하지는 않는다. Zvec가 보여주는 신호는 바로 이 지점이다.
v0.5.0의 핵심은 벡터 검색 하나가 아니라 하이브리드 검색 런타임이다
Zvec v0.5.0 릴리스 노트에서 가장 중요한 변화는 세 가지다.
- Full-Text Search: 문자열 필드에 FTS 인덱스를 붙이고 자연어 또는 구조화 표현식으로 검색할 수 있다.
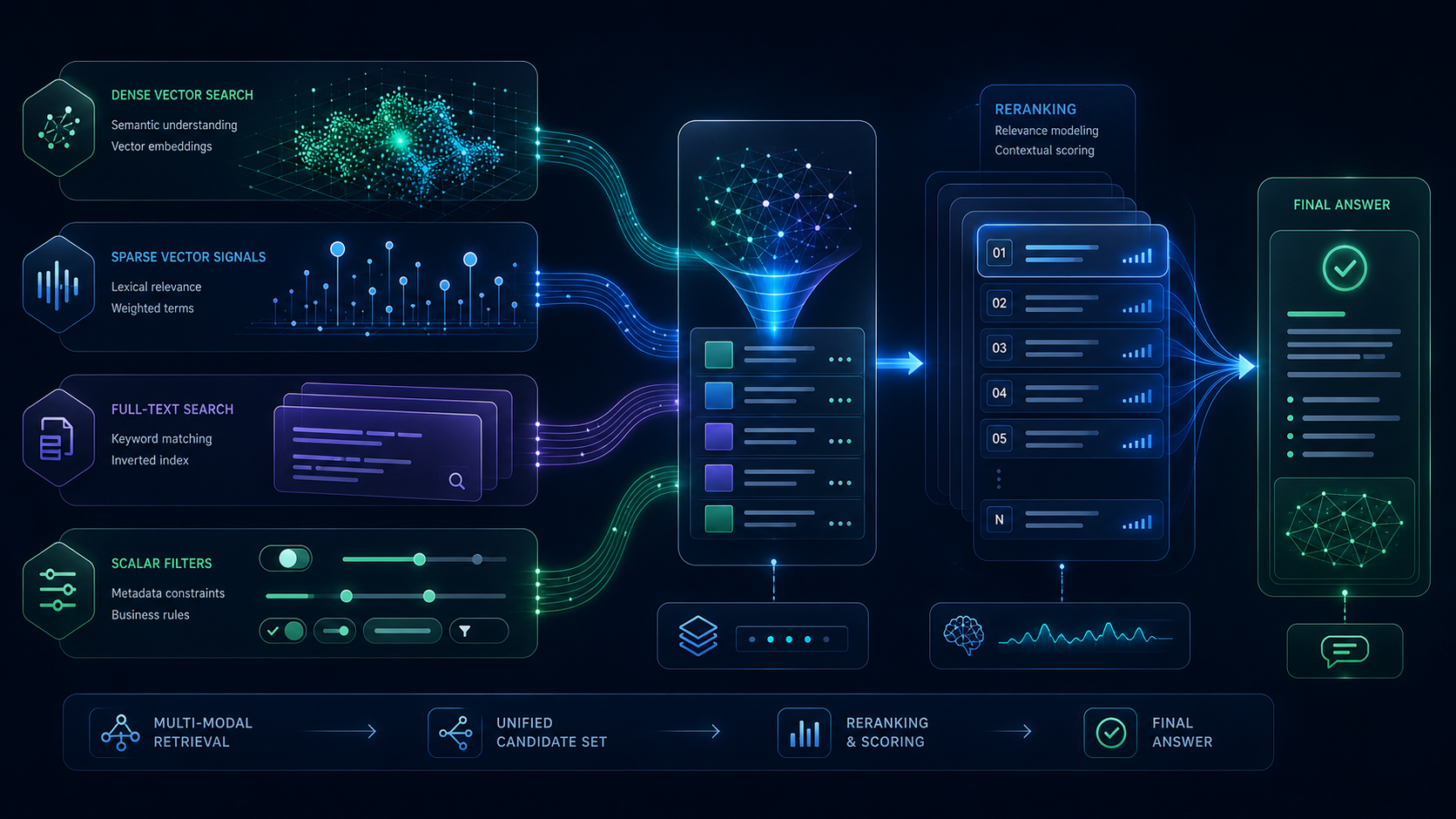
- Hybrid Retrieval: dense vector, sparse vector, scalar filter, text를 하나의
MultiQuery로 결합할 수 있다. - DiskANN Index: 인덱스 대부분을 RAM이 아니라 디스크에 두어 대규모 ANN 검색의 메모리 부담을 낮춘다.
여기서 주목할 것은 “벡터 검색 성능”보다 “검색 조합의 폭”이다. 실제 RAG 품질은 순수 embedding similarity만으로 결정되지 않는다. 문서 제목, 키워드, 날짜, 권한, 제품 카테고리, 사용자 세그먼트, 언어, 최신성, 엔티티명, 정확한 코드 심볼 같은 신호가 같이 들어간다. 그래서 실무 RAG는 점점 다음 구조로 간다.
- dense vector로 의미적으로 비슷한 후보를 찾는다.
- sparse vector나 keyword search로 정확한 용어를 놓치지 않는다.
- scalar filter로 권한, 날짜, 프로젝트, 고객 계정을 제한한다.
- reranker나 LLM judge로 최종 문맥을 정리한다.
Zvec가 FTS와 hybrid retrieval을 내장한다는 것은, 작은 제품팀도 외부 검색 엔진과 벡터 DB를 따로 붙이지 않고 한 런타임에서 꽤 많은 검색 패턴을 실험할 수 있다는 뜻이다.
개발자 입장에서 이 변화는 중요하다. “벡터 DB를 붙인다”는 작업은 사실 모델보다 데이터 모델링에 가깝다. 어떤 필드를 문서에 넣을지, 어떤 필드는 filterable하게 둘지, 어떤 텍스트 필드는 FTS 인덱스를 붙일지, 어떤 embedding dimension과 metric을 쓸지 결정해야 한다. Zvec Quickstart도 collection schema를 정의하고, FieldSchema, DataType.VECTOR_FP32, HnswIndexParam, metric type을 지정하는 흐름으로 시작한다.
즉 Zvec를 잘 쓰려면 “임베딩을 넣고 top-k를 뽑는다”에서 멈추면 안 된다. 제품의 검색 실패 유형을 먼저 봐야 한다.
- 사용자가 정확한 제품명·함수명·고객명을 찾는가?
- 의미적으로 비슷한 문서를 찾는가?
- 최근 문서가 더 중요한가?
- 권한 필터가 강제돼야 하는가?
- 같은 질문에서 sparse/dense 결과를 섞어야 하는가?
이 질문에 답한 뒤 schema와 index를 정해야 한다. Zvec v0.5.0은 그 설계 공간을 앱 내부로 가져온다.
DiskANN과 인덱스 선택: 벡터 검색은 결국 메모리·지연시간·정확도의 삼각형이다
Zvec 문서의 vector index 설명은 Flat, HNSW, HNSW-RaBitQ, DiskANN, IVF 같은 선택지를 언급한다. 문서가 강조하는 포인트는 단순하다. 인덱스 타입은 데이터 규모, 지연시간 요구, 정확도 허용치에 따라 달라진다. exact search는 정확하지만 규모가 커지면 느려지고, ANN은 정확도를 조금 양보해 속도와 리소스 효율을 얻는다.
Zvec v0.5.0의 DiskANN 추가가 눈에 띄는 이유도 여기에 있다. 릴리스 노트는 DiskANN이 인덱스의 대부분을 RAM 대신 디스크에 두어 메모리 사용량을 크게 줄이고, 메모리 제약이 있는 환경에서 대규모 ANN 검색을 가능하게 한다고 설명한다. 이건 “벤치마크에서 더 빠르다”보다 더 실무적인 이야기다.
많은 RAG 시스템은 처음에는 작다. 문서 수천 개, 고객별 지식베이스 수만 개, 제품 로그 일부 정도로 시작한다. 하지만 시간이 지나면 고객별 인덱스, 버전별 문서, 이벤트 로그, 대화 메모리, 이미지 임베딩, 코드베이스 임베딩이 쌓인다. 이때 모든 벡터를 RAM 중심으로만 다루면 비용 구조가 흔들린다. 반대로 디스크 기반 인덱스는 지연시간과 처리량을 다시 검증해야 한다.

그래서 Zvec 같은 프로젝트를 볼 때는 “우리 벤치마크보다 빠른가?”보다 아래 질문이 더 중요하다.
| 질문 | 왜 중요한가 |
|---|---|
| 데이터셋이 RAM에 들어가는가? | HNSW 계열과 DiskANN 계열의 선택이 달라진다. |
| 검색 실패 비용이 큰가? | recall을 얼마나 양보할 수 있는지 결정한다. |
| 업데이트가 잦은가? | 인덱스 빌드·optimize·merge 비용이 중요해진다. |
| 고객별 격리가 필요한가? | collection 설계와 파일 단위 배포가 중요해진다. |
| 엣지·온프레미스 배포가 필요한가? | 외부 관리형 DB보다 임베디드 구조가 유리할 수 있다. |
Zvec의 benchmarks 문서는 Alibaba 내부 production workloads에서 검증됐다는 식의 성능 주장을 제시한다. 하지만 실제 도입 판단은 반드시 자기 데이터로 해야 한다. 임베딩 분포, 차원 수, 필터 비율, top-k, 동시성, 업데이트 주기, 디스크 종류, CPU instruction set에 따라 결과가 크게 달라진다.
에이전트 메모리 관점: “기억”은 모델 기능이 아니라 검색·저장·정책의 조합이다
요즘 에이전트 제품에서 memory는 과장되기 쉬운 단어다. 모델이 사용자를 “기억한다”고 말하지만, 실제 구현은 대부분 저장소와 검색, 요약, 권한, 만료 정책의 조합이다. 이 관점에서 Zvec의 GitHub topic 중 llm-memory, rag, semantic-search, vector-database, local, embedded가 같이 붙어 있다는 점은 흥미롭다.
에이전트 메모리는 보통 세 계층으로 나뉜다.
- 짧은 작업 기억: 현재 세션의 파일, 명령, 대화 상태
- 프로젝트 기억: 코드베이스 구조, 문서, 과거 결정, 이슈 패턴
- 조직 기억: 팀 규칙, 고객별 컨텍스트, 운영 정책, 장기 지식
이 중 1번과 2번은 외부 클러스터보다 로컬·임베디드 검색이 더 편할 때가 많다. 예를 들어 개발자 데스크톱에서 코드베이스를 색인하거나, CI 작업에서 특정 브랜치 문서만 임시로 검색하거나, 고객사 온프레미스 환경에서 로그와 문서를 밖으로 내보낼 수 없는 경우다.
반대로 3번은 중앙화된 정책과 관측성이 더 중요할 수 있다. 누가 어떤 메모리를 읽었는지, 어떤 고객 데이터가 섞였는지, retention 정책이 지켜졌는지 봐야 하기 때문이다. 따라서 Zvec 같은 인프로세스 벡터 DB는 “중앙 벡터 플랫폼의 대체재”라기보다, 제품 내부 검색·로컬 RAG·엣지 에이전트 메모리의 하부 런타임 후보로 보는 편이 정확하다.
한국 개발팀이 실험한다면 이렇게 보는 게 좋다
Zvec를 바로 프로덕션 표준으로 정하기보다, 작은 실험으로 검증하는 편이 낫다. 추천하는 순서는 이렇다.
1) 외부 DB를 붙이기 전에 로컬 RAG 기준선을 만든다
팀 내부 문서, 고객 FAQ, 제품 매뉴얼, 코드베이스 일부처럼 작은 데이터셋을 하나 고른다. Zvec Quickstart처럼 schema를 만들고, embedding field와 scalar field를 분리한다. 이때 중요한 건 모델이 아니라 실패 케이스다. 검색 결과가 왜 틀리는지 기록해야 한다.
2) dense-only와 hybrid 검색을 비교한다
v0.5.0의 핵심이 hybrid retrieval이라면, dense vector만 쓰는 기준선과 FTS·filter를 섞은 기준선을 비교해야 한다. 한국어·영어가 섞인 문서, 제품명, 코드 심볼, 버전 번호, 고객사 이름은 dense vector만으로 놓치기 쉽다. 이런 케이스에서 FTS가 실제로 얼마나 보완하는지 봐야 한다.
3) 메모리 예산을 먼저 정한다
인프로세스 구조는 편하지만, 앱 프로세스 리소스를 같이 먹는다. 컨테이너 메모리 제한, 서버리스 파일 시스템, 데스크톱 앱 번들 크기, 모바일/엣지 환경에서는 이 차이가 치명적일 수 있다. HNSW와 DiskANN을 비교할 때도 “평균 지연시간”만 보지 말고 p95/p99, RAM, 디스크 I/O, 인덱스 빌드 시간을 같이 봐야 한다.
4) 멀티테넌시와 보안 경계를 과소평가하지 않는다
임베디드 DB는 설치가 쉬운 만큼 데이터 격리 책임이 앱으로 올라온다. 고객별 collection을 나눌지, 파일 권한을 어떻게 둘지, 백업과 삭제 요청을 어떻게 처리할지, 로그에 검색 결과가 남는지 등을 먼저 정해야 한다. 특히 RAG는 원문 문서와 파생 임베딩, 요약 텍스트가 함께 움직이므로 개인정보·영업기밀 처리 정책을 따로 봐야 한다.
실무 해석: Zvec는 “벡터 DB 시장의 승자”가 아니라 배포 형태의 변화다
Zvec를 과장해서 “기존 벡터 DB를 대체한다”고 말할 필요는 없다. 대규모 SaaS, 복잡한 멀티테넌트 검색, 강한 운영 관측성, 수평 확장, 관리형 서비스가 필요한 팀에는 여전히 외부 벡터 DB와 검색 플랫폼이 맞다. 하지만 AI 기능이 점점 제품 안쪽으로 들어오면서, 모든 검색이 중앙 클러스터로 갈 필요도 없다.
내가 보는 핵심 변화는 세 가지다.
- RAG의 기본 단위가 작아진다. 큰 지식베이스 하나가 아니라, 기능별·고객별·프로젝트별 작은 검색 인덱스가 많아진다.
- 에이전트 메모리는 로컬 실행 환경과 가까워진다. 코드 에이전트, 데스크톱 에이전트, 온프레미스 워크플로에서는 외부 API보다 임베디드 검색이 자연스럽다.
- 검색 품질은 벡터만이 아니라 hybrid schema 설계가 좌우한다. dense, sparse, FTS, scalar filter, reranking을 어떻게 묶는지가 제품 품질을 만든다.
그래서 Zvec는 “새로운 DB 제품”이라기보다, AI 앱의 검색 계층이 더 작은 배포 단위로 쪼개지는 흐름을 보여주는 사례다. 이 흐름은 DuckDB가 분석 워크로드 일부를 앱과 노트북 안으로 끌어온 것과 비슷한 면이 있다. 모든 데이터 웨어하우스를 대체하지는 않지만, 개발자 경험과 배포 모델을 바꾼다.
결론: 벡터 검색도 이제 제품 코드의 일부로 설계해야 한다
Zvec가 오늘 당장 모든 팀의 표준 선택지가 될지는 알 수 없다. 프로젝트 성숙도, 문서 품질, 장기 유지보수, 대규모 장애 사례, 실제 벤치마크, 언어 바인딩 안정성은 더 봐야 한다. 하지만 방향은 분명하다. RAG와 에이전트 메모리가 제품의 핵심 기능이 되면서, 벡터 검색은 별도 인프라팀만의 일이 아니라 애플리케이션 설계 문제가 되고 있다.
한국 개발팀이라면 Zvec를 “가벼운 벡터 DB가 나왔다” 정도로 넘기기보다, 다음 질문으로 읽는 게 좋다.
우리 제품의 검색/메모리 계층은 정말 외부 클러스터여야 하는가, 아니면 앱 안에 붙는 작은 런타임으로 시작하는 편이 더 빠르고 안전한가?
이 질문에 대한 답은 팀마다 다르다. 하지만 이제 선택지는 하나가 아니다. Zvec 같은 인프로세스 벡터 DB는 RAG와 에이전트 메모리를 더 작고, 더 가까운 위치에서 설계할 수 있게 만든다. 이게 이번 업데이트의 가장 실용적인 의미다.