- Published on
Supermemory: AI 에이전트 경쟁은 이제 기억 레이어에서 갈린다
- Authors

- Name
- Kyunghyun Park
- @devkhpark
Supermemory · AI 에이전트 메모리 · Agent Memory API · RAG 이후의 컨텍스트 레이어
AI 에이전트 제품을 만들 때 가장 과소평가되는 병목은 모델 호출이 아니다. 진짜 병목은 사용자와 조직의 맥락을 얼마나 안정적으로 기억하고, 업데이트하고, 검색해서 다음 행동에 넣을 수 있느냐다. Supermemory가 흥미로운 이유도 여기에 있다. 이 프로젝트는 “빠른 메모리 API” 정도가 아니라, 에이전트 애플리케이션의 기억 레이어를 제품화하려는 시도에 가깝다.

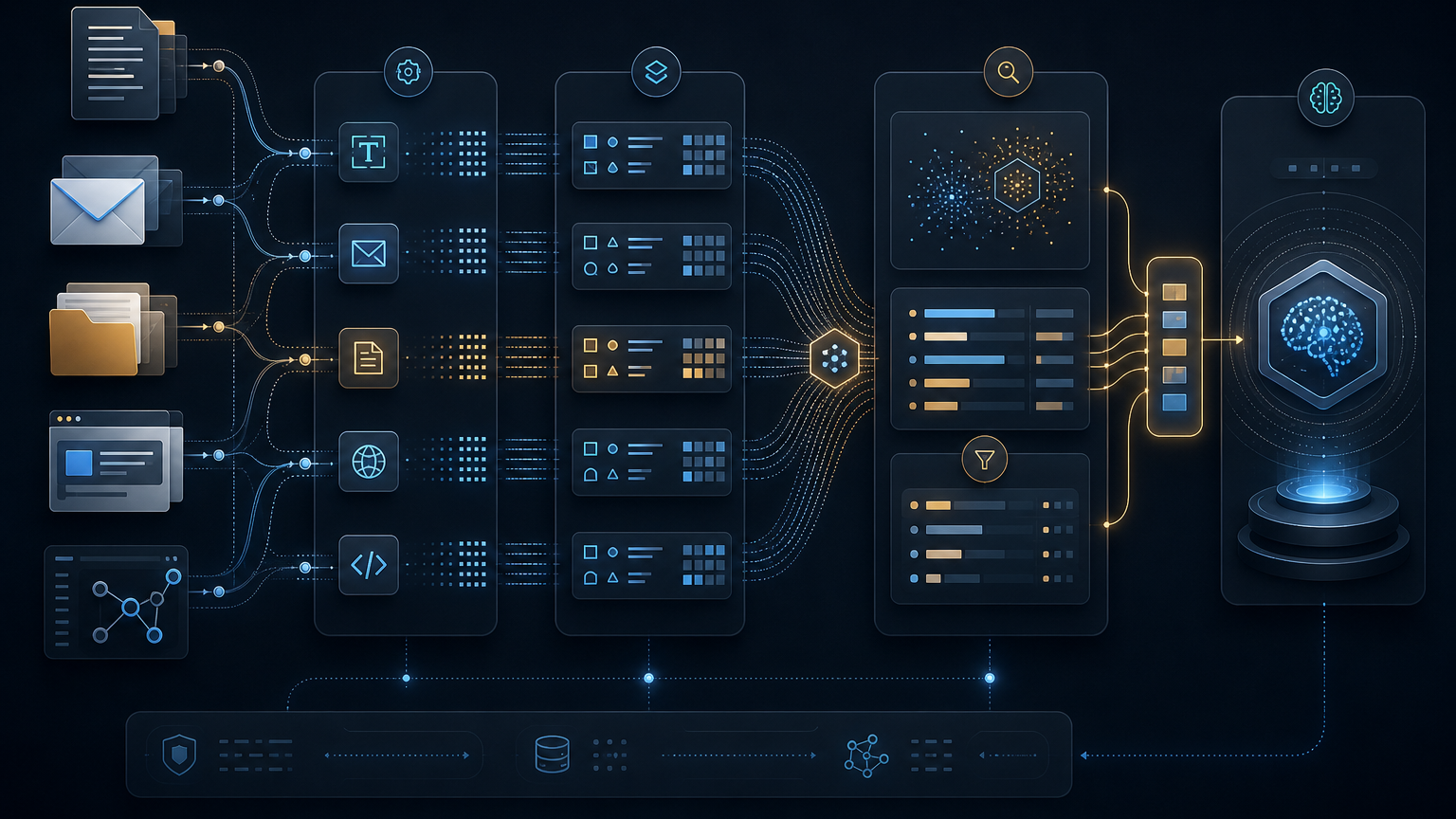
2026-06-01 기준 supermemoryai/supermemory는 GitHub Trending에 다시 등장했고, GitHub API 기준 약 2.3만 스타, 2천 개 이상의 포크를 가진 TypeScript 기반 MIT 라이선스 프로젝트다. 공식 README는 Supermemory를 “AI를 위한 memory and context layer”로 설명하고, 문서의 llms-full.txt는 User Profiles, Memory Graph, Retrieval, Extractors, Connectors라는 다섯 개 컨텍스트 계층을 하나의 API로 제공한다고 정리한다.
이 글의 결론부터 말하면 이렇다. 에이전트 제품의 차별화는 더 긴 프롬프트를 넣는 능력보다, 기억을 제품 운영 단위로 다루는 능력에서 갈릴 가능성이 높다. Supermemory는 그 방향을 꽤 선명하게 보여준다.
왜 지금 “메모리”가 다시 중요해졌나
LLM 제품의 첫 번째 세대는 대체로 “질문을 잘 답하는 모델” 중심이었다. 두 번째 세대는 도구 호출, MCP, 코드 실행, 브라우저 제어, 워크플로 자동화로 이동했다. 그런데 에이전트가 실제 업무를 맡기 시작하면 바로 다음 문제가 튀어나온다.
- 지난번에 사용자가 어떤 제약을 줬는지 기억해야 한다.
- 조직의 문서, 티켓, 메일, 코드 저장소에서 관련 맥락을 찾아야 한다.
- 오래된 정보와 최신 정보를 구분해야 한다.
- 사용자가 삭제하거나 잊어달라고 한 내용은 다시 꺼내면 안 된다.
- 팀 단위 제품에서는 개인별·조직별 권한 경계와 감사 로그가 필요하다.
단순 RAG는 이 문제의 일부만 푼다. 문서를 벡터화해 검색하는 것만으로는 “사용자가 최근에 마음을 바꿨다”, “이 지식은 더 이상 유효하지 않다”, “이 선호는 A 프로젝트에서만 적용된다” 같은 운영 맥락을 제대로 다루기 어렵다. 그래서 에이전트 시대의 메모리는 벡터 검색 기능 하나가 아니라 프로필·시간·출처·권한·검색·업데이트 정책을 묶은 상태 관리 레이어가 된다.

Supermemory README도 같은 문제의식에서 출발한다. “Your AI forgets everything between conversations. Supermemory fixes that.”라는 문장은 마케팅 문구처럼 보이지만, 실제 제품 설계 관점에서는 꽤 정확한 문제 정의다. 에이전트가 매번 새로 태어나면 사용자는 같은 정보를 반복해서 설명해야 하고, 제품은 사용자별 학습 효과를 누적하지 못한다.
Supermemory가 벡터DB와 다르게 포지셔닝하는 지점
Supermemory의 공식 문서에서 눈에 띄는 건 “검색”만 말하지 않는다는 점이다. llms-full.txt는 Supermemory가 다음 다섯 계층을 제공한다고 설명한다.
- User Profiles — 사용자 행동, 의도, 선호, 맥락에서 구조화된 프로필을 만든다.
- Memory Graph — 단순 벡터가 아니라 관계와 업데이트, 모순 처리를 고려하는 그래프 계층을 둔다.
- Retrieval — 하이브리드 벡터+키워드 검색과 리랭킹으로 필요한 맥락을 돌려준다.
- Extractors — PDF, 웹 페이지, 이미지, 오디오 같은 다양한 포맷을 이해하고 정규화한다.
- Connectors — Notion, Google Drive, S3, Gmail, 커스텀 소스 같은 외부 지식 저장소를 동기화한다.
이 구성이 중요한 이유는, 에이전트 제품에서 메모리는 입력 파이프라인 전체를 건드리기 때문이다. “사용자가 말한 문장을 저장한다” 수준으로는 부족하다. 어떤 자료에서 나온 지식인지, 언제 들어온 정보인지, 누구에게 적용되는 정보인지, 검색 결과로 다시 넣어도 되는 정보인지까지 관리해야 한다.
Supermemory가 README에서 LongMemEval, LoCoMo, ConvoMem 같은 메모리 벤치마크를 강조하는 것도 이 맥락이다. 공식 자료 기준으로 Supermemory는 LongMemEval 85.2%, LoCoMo #1, ConvoMem #1을 내세운다. 이 수치를 그대로 제품 품질 보증으로 받아들이면 곤란하지만, 적어도 Supermemory가 “그럴듯한 RAG 래퍼”가 아니라 장기 기억 문제 자체를 정면 주제로 삼고 있다는 신호로 읽을 수 있다.
개발자에게 중요한 건 API와 통합면이다
한국 개발자와 빌더 입장에서 가장 실무적인 질문은 “그래서 우리 앱에 어떻게 붙이나?”다. Supermemory는 이 부분을 꽤 공격적으로 밀고 있다.
공식 문서와 README 기준으로 Supermemory는 REST API, TypeScript SDK, Python SDK를 제공하고, 핵심 엔드포인트로 POST https://api.supermemory.ai/v3/add, POST https://api.supermemory.ai/v3/search를 제시한다. npm 레지스트리의 supermemory 패키지는 공식 TypeScript 라이브러리이며, 2026-06-01 확인 시점의 latest 버전은 4.21.1이다.
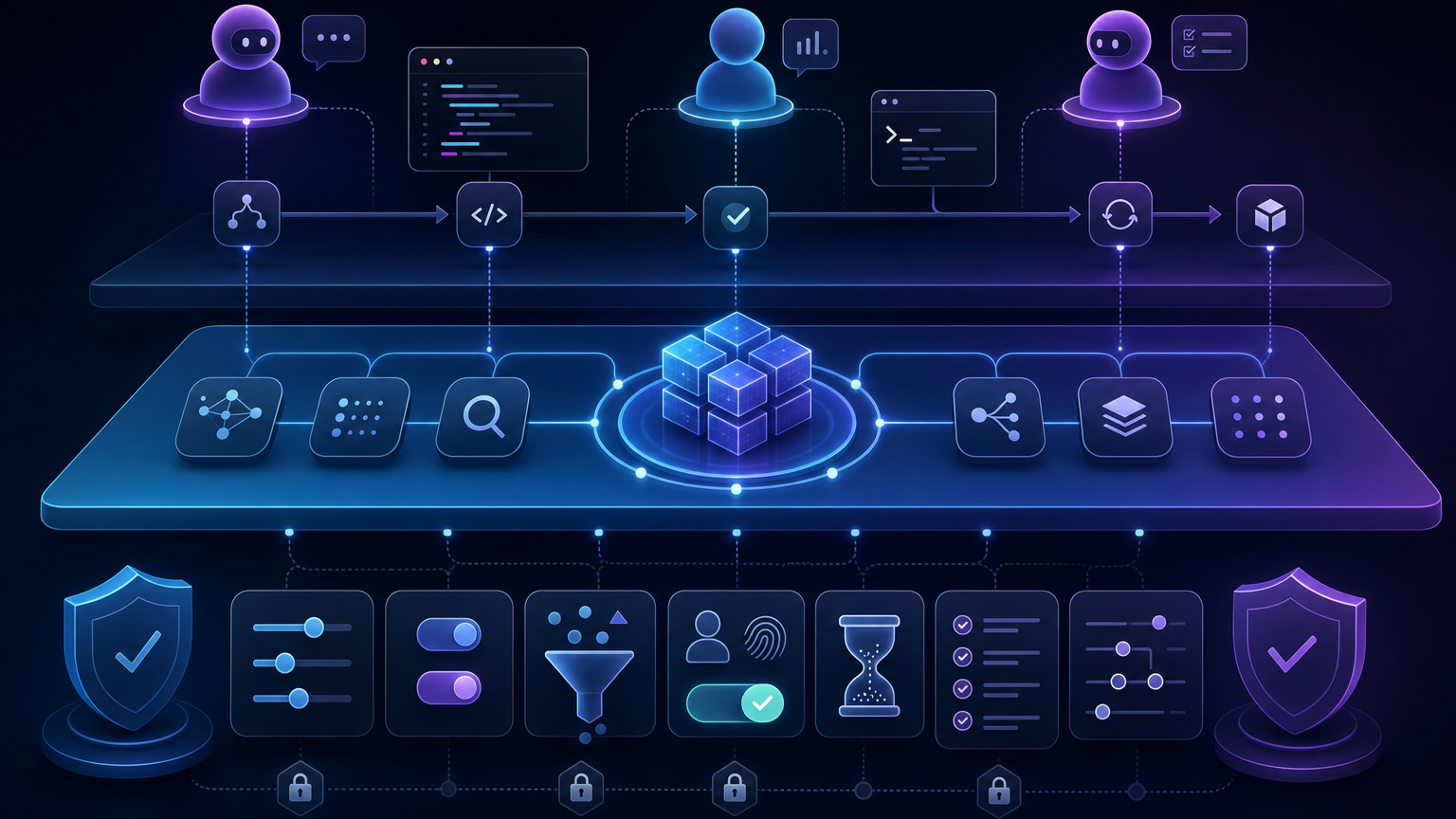
또 하나 중요한 부분은 통합 대상이다. Supermemory 문서는 TypeScript, Python, REST뿐 아니라 Claude Code, Cursor, OpenClaw, OpenCode, Windsurf, Vercel AI SDK, LangChain, LangGraph, CrewAI, OpenAI SDK, Mastra, Zapier, n8n, Pipecat 등을 언급한다. README에는 Claude Code, OpenCode, OpenClaw, Hermes용 플러그인도 별도로 소개된다.
이건 단순한 생태계 로고 나열이 아니다. 에이전트 메모리 레이어의 채택 경로는 두 갈래로 나뉜다.
- 애플리케이션 API 경로: SaaS, 내부 도구, AI 코파일럿 제품에 SDK/API로 붙인다.
- 개발자 도구 경로: Claude Code, Cursor, Hermes 같은 에이전트 런타임에 플러그인/MCP로 붙인다.
첫 번째는 제품 기능이고, 두 번째는 개발자 작업 환경이다. Supermemory가 둘 다 노리는 이유는 명확하다. 기억 레이어가 진짜로 유용해지려면 사용자의 업무 맥락이 애플리케이션 안에서만 생기지 않기 때문이다. 코드 리뷰, 문서 작성, 이슈 트리아지, 고객 응대, 노트 정리, 실험 기록이 모두 기억 후보가 된다.
Supermemory를 도입할 때 봐야 할 진짜 체크리스트
Supermemory 같은 메모리 API를 검토할 때 “검색이 빠른가?”만 보면 안 된다. 실제 도입에서는 아래 질문들이 더 중요하다.
1) 어떤 정보를 기억할 것인가
모든 대화를 저장하는 제품은 위험하다. 사용자 선호, 반복 업무 규칙, 프로젝트별 제약, 장기 문서 지식처럼 다시 쓸 가치가 있는 정보만 남겨야 한다. “기억할 만한 정보”와 “그냥 지나가는 대화”의 경계가 제품 경험을 결정한다.
2) 기억의 수명은 어떻게 관리할 것인가
오래된 정보는 성능을 망칠 수 있다. 예를 들어 “이번 분기에는 AWS를 쓰지 않는다”는 말이 6개월 뒤에도 유효하다고 가정하면 잘못된 추천이 나온다. TTL, 업데이트 정책, 출처 표시, 사용자 삭제 요청은 메모리 제품의 필수 기능이다.
3) RAG와 메모리를 분리할 것인가, 결합할 것인가
문서 검색과 사용자 메모리는 다르다. 문서는 팀의 지식이고, 메모리는 사용자·상황·시간에 더 민감하다. Supermemory가 하이브리드 검색과 메모리 그래프를 강조하는 지점은 이 둘을 한 요청에서 다루려는 방향으로 보인다. 다만 제품 설계자는 문서 지식과 개인 기억을 UI와 권한 정책에서 분명히 구분해야 한다.
4) 감사와 동의는 어떻게 처리할 것인가
에이전트가 “사용자가 전에 이렇게 말했다”고 행동한다면, 사용자는 그 기억을 확인하고 수정할 수 있어야 한다. 팀 제품에서는 누가 어떤 메모리를 만들었고, 어떤 요청에서 사용됐는지 추적해야 한다. 메모리 레이어는 생산성 기능이면서 동시에 개인정보·보안 기능이다.
SEO 관점에서 이 주제가 좋은 이유
“AI 에이전트”와 “RAG”는 이미 넓은 키워드가 됐다. 반면 “AI 메모리”, “에이전트 메모리”, “LLM 장기 기억”, “MCP 메모리”, “사용자 프로필 기반 AI”, “context engineering”은 아직 실무 해석 글이 부족하다. Supermemory는 이 키워드들을 하나로 묶는 좋은 사례다.
특히 한국어권에서는 RAG를 “문서 검색”으로만 이해하는 경우가 많다. 하지만 에이전트 제품을 운영해보면 진짜 문제는 문서 검색보다 넓다. 사용자가 무엇을 선호하는지, 프로젝트별 맥락이 무엇인지, 어떤 기억을 언제 폐기해야 하는지, 여러 도구에서 생성된 기록을 어떻게 합칠지까지 포함된다. 이 글이 잡고 싶은 검색 의도도 바로 그 지점이다.
실무 해석: Supermemory는 “더 똑똑한 챗봇”보다 “상태 있는 에이전트”에 가깝다
Supermemory를 단순히 챗봇에 기억 기능을 붙이는 도구로 보면 반만 본 것이다. 더 중요한 해석은 상태 있는 에이전트 애플리케이션을 만들기 위한 인프라다.
지금까지 많은 AI 제품은 세션 중심이었다. 사용자가 대화창을 열고, 프롬프트를 넣고, 결과를 받으면 끝이다. 하지만 실제 업무 제품은 그렇지 않다. 고객사별 맥락, 사용자별 선호, 반복 업무 규칙, 사내 문서, 최신 티켓, 과거 결정이 모두 다음 행동에 영향을 준다. 결국 에이전트가 제대로 일하려면 “지금 받은 프롬프트”만이 아니라 “이 사용자가 과거에 만든 세계”를 읽어야 한다.
Supermemory가 흥미로운 이유는 바로 이 전환을 제품화하고 있다는 점이다. 메모리 API, SDK, MCP, 플러그인, 커넥터, 벤치마크를 한 번에 밀고 간다. 성공 여부와 별개로 방향은 분명하다. 앞으로 에이전트 제품의 경쟁은 모델 선택만으로 끝나지 않고, 기억을 어떻게 수집·정리·검색·삭제·감사하느냐로 이동한다.
한 줄 결론
Supermemory는 벡터DB 대체재라기보다, 에이전트 제품이 장기 기억을 운영 가능한 인프라로 다루기 시작했다는 신호다. AI 에이전트를 실제 제품에 넣으려는 팀이라면 “어떤 모델을 쓸까?” 다음 질문으로 **“우리 제품의 기억 레이어는 무엇인가?”**를 반드시 물어야 한다.