- Published on
video-use: 영상 편집을 타임라인 UI가 아니라 에이전트 파이프라인으로 바꾸는 실험
- Authors

- Name
- Kyunghyun Park
- @devkhpark
AI Agent · Video Editing · Media Operations
영상 편집 자동화는 오래된 주제다. 하지만 2026년 6월 29일 GitHub Trending에 오른 browser-use/video-use를 단순한 “AI 영상 편집기”로 보면 핵심을 놓친다. 이 프로젝트가 흥미로운 이유는 편집 기능 목록보다 구조에 있다. 영상 편집을 사람이 타임라인을 직접 만지는 GUI 작업에서, 에이전트가 읽고 판단하고 실행하고 검수하는 운영 파이프라인으로 바꾸려는 시도이기 때문이다.

video-use README는 “raw footage를 폴더에 넣고 Claude Code와 대화하면 final.mp4가 나온다”고 설명한다. 표면적으로는 자동 컷 편집, 필러워드 제거, 컬러 그레이딩, 자막 번인, 애니메이션 오버레이 생성 같은 기능이 눈에 띈다. 하지만 진짜 메시지는 더 작고 단단하다. LLM에게 30,000 프레임을 모두 보게 하는 대신, 영상의 의사결정 표면을 단어 단위 타임스탬프, speaker diarization, waveform, filmstrip, cut candidate로 바꾼다.
이 글은 browser-use/video-use의 README, SKILL.md, install.md, GitHub API 메타데이터, 그리고 원조 프로젝트인 browser-use/browser-use의 포지셔닝을 기준으로 작성했다. 결론부터 말하면, video-use는 “에이전트가 영상을 잘 편집할 수 있나?”라는 질문보다 **미디어 작업을 에이전트가 다룰 수 있는 구조화된 작업면으로 바꿀 수 있나?**라는 질문에 더 가깝다.
GitHub Trending에서 읽어야 할 신호: 영상도 agent skill이 되고 있다
이 저장소는 2026년 6월 29일 위키의 GitHub Trending 스냅샷에서 13개 저장소 중 13위로 잡혔고, 트렌딩 카드 기준 하루 324개 스타를 얻었다. GitHub API 기준으로는 1만 개가 넘는 스타와 1,500개 안팎의 fork를 기록했다. 숫자만 보면 “인기 있는 오픈소스 영상 편집 도구” 정도로 보일 수 있다.
하지만 더 중요한 신호는 저장소 구조다. 최상위에는 README.md, install.md, SKILL.md, helpers/, skills/, pyproject.toml이 있다. 즉 이것은 독립 앱이라기보다 코딩 에이전트에게 설치해서 쓰게 만드는 skill package에 가깝다. README의 설치 프롬프트도 Claude Code, Codex, Hermes, Openclaw처럼 shell access를 가진 에이전트에 붙이는 방식을 전제로 한다.
이 방향은 최근 AI 개발 도구 흐름과 잘 맞는다. 에이전트가 브라우저를 조작하려면 DOM이나 접근성 트리 같은 구조화된 표면이 필요했던 것처럼, 에이전트가 영상을 편집하려면 픽셀 스트림이 아니라 편집 의사결정에 필요한 압축된 중간표현이 필요하다.
핵심은 “영상을 본다”가 아니라 “영상을 읽는다”이다
README에서 가장 중요한 문장은 “The LLM never watches the video. It reads it”이다. 이 한 문장이 video-use의 제품 철학을 거의 다 설명한다.

video-use는 두 개의 층으로 영상을 에이전트에게 제공한다.
- 항상 로드되는 오디오 transcript layer
- ElevenLabs Scribe로 source마다 word-level timestamp를 만든다.
- speaker diarization과
(laughter),(applause),(sigh)같은 audio event를 포함한다. - 여러 take를
takes_packed.md같은 작은 텍스트 표면으로 압축한다.
- 필요할 때만 보는 visual composite layer
timeline_view가 특정 구간의 filmstrip, waveform, word label, speaker track을 한 장의 PNG로 만든다.- 애매한 pause, retake 비교, cut point sanity check 같은 결정 지점에서만 호출한다.
README는 naive하게 30,000 프레임을 모두 모델에 넣으면 4,500만 토큰의 노이즈가 될 수 있지만, video-use 방식은 12KB 텍스트와 소수의 PNG로 충분하다고 주장한다. 수치 자체보다 중요한 건 관점이다. 멀티모달 모델이 커져도, 모든 것을 그대로 넣는 방식은 운영적으로 비싸고 불안정하다. 실무에서는 모델이 볼 수 있는 것보다 무엇을 보게 할지 설계하는 중간표현이 더 중요해진다.
이건 browser-use가 웹 페이지를 스크린샷 덩어리로 다루지 않고 에이전트가 조작 가능한 구조로 바꾸려 했던 흐름과 닮았다. video-use는 같은 아이디어를 영상 편집 도메인으로 옮긴 셈이다.
자동 편집기가 아니라, 재현 가능한 EDL 생성기처럼 봐야 한다
README의 pipeline은 단순하다.
Transcribe → Pack → LLM Reasons → EDL → Render → Self-Eval
이 흐름에서 에이전트의 역할은 “감으로 영상을 예쁘게 만든다”가 아니다. 먼저 source를 inventory하고, 편집 전략을 제안하고, 사용자의 확인을 받은 뒤, cut decision을 EDL 형태로 만들고, ffmpeg 기반 렌더링과 자체 검수를 수행한다.
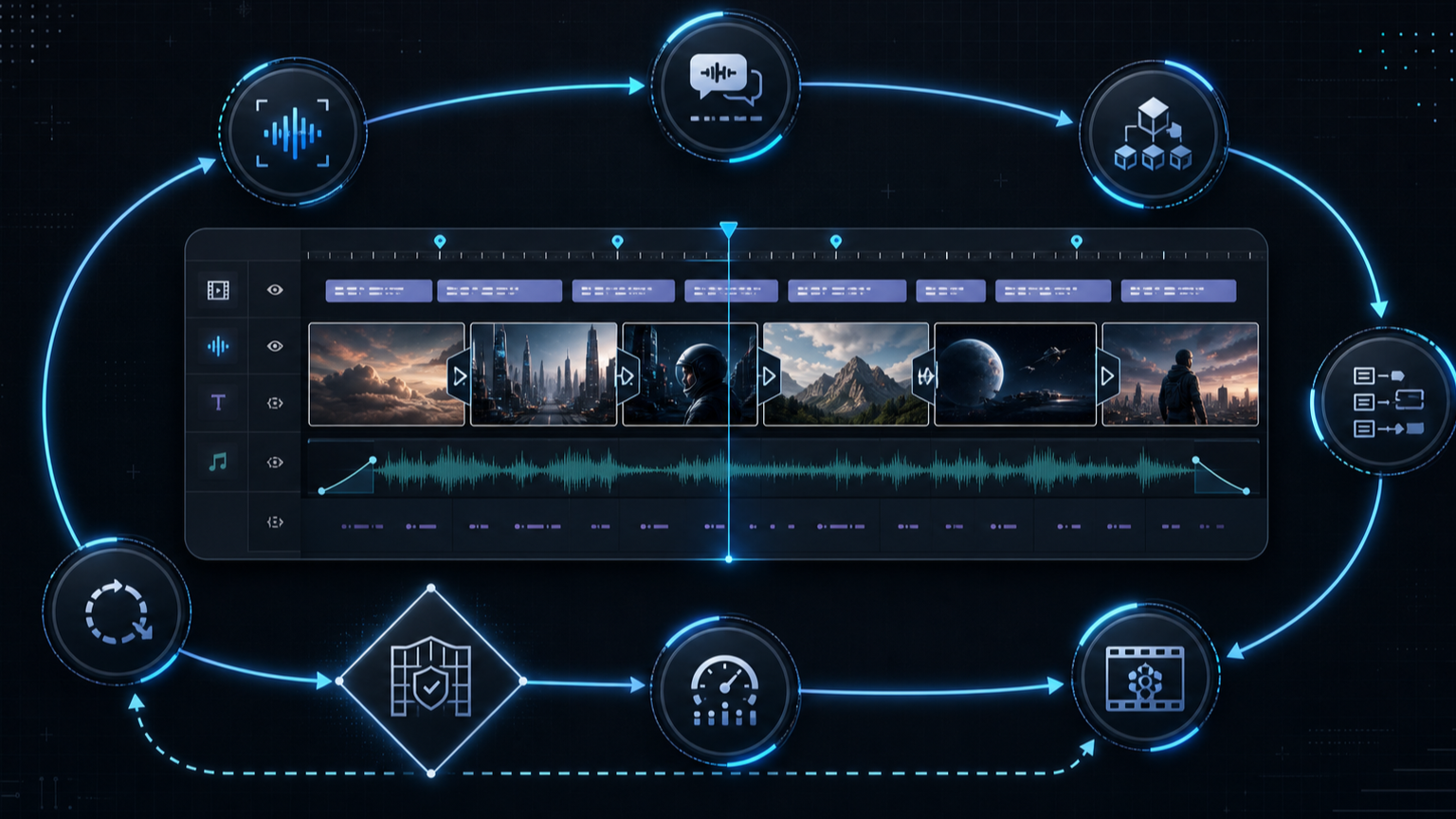
SKILL.md의 hard rules는 이 프로젝트가 왜 “데모”보다 “운영 규칙”에 가까운지 보여준다. 예를 들어 다음 같은 규칙이 강하게 박혀 있다.
- 자막은 모든 overlay 뒤, filter chain의 마지막에 적용해야 한다.
- segment는 lossless
-c copyconcat 중심으로 처리해야 한다. - 모든 segment boundary에는 30ms audio fade를 넣어 pop을 막아야 한다.
- cut edge는 단어 경계에 snap해야 한다.
- Scribe timestamp drift를 고려해 30–200ms padding을 둬야 한다.
- transcript는 source 단위로 cache하고, 원본이 바뀌지 않으면 재전사하지 않아야 한다.
- 전략 확인 전에는 cut을 만지지 않는다.
- session output은 source folder의
edit/아래에만 쓴다.
이런 규칙은 화려하지 않다. 하지만 운영에서는 이런 디테일이 성패를 가른다. “AI가 영상 편집을 해준다”는 말은 쉬운데, 실제로는 오디오 pop, 자막 misalignment, overlay ordering, timestamp drift, 재인코딩 손실, cut boundary의 어색함 같은 작은 실패가 바로 품질을 무너뜨린다.
그래서 video-use의 가치는 편집 알고리즘 자체보다 에이전트에게 프로덕션 정확성 규칙을 skill로 주입하는 방식에 있다. 에이전트가 창의적인 판단을 하되, 깨지면 안 되는 부분은 문서화된 hard rule로 묶는다. 최근 agent skill, plugin, MCP 생태계가 가는 방향과도 정확히 맞물린다.
애니메이션 오버레이가 중요한 이유: 에이전트가 하위 제작자를 spawn한다
README에는 HyperFrames, Remotion, Manim, PIL을 통해 animation overlay를 만들고, 여러 animation을 parallel sub-agent로 생성한다는 설명이 있다. 이 대목은 그냥 “예쁜 효과도 넣는다” 정도로 읽으면 아깝다.
영상 제작은 본질적으로 다단계 작업이다.
- main cut을 잡는다.
- 설명이 필요한 구간을 찾는다.
- 해당 구간에 맞는 그래픽/자막/애니메이션을 설계한다.
- overlay를 render한다.
- 최종 timeline에 합성한다.
- boundary와 subtitle visibility를 검수한다.
사람 편집자도 이걸 한 덩어리로 하지 않는다. 편집, 모션, 자막, 컬러, 사운드가 나뉜다. video-use가 흥미로운 지점은 이 분업 구조를 에이전트 구조로 옮긴다는 점이다. 즉 main agent가 전체 전략과 timeline을 잡고, 필요할 때 animation slot마다 sub-agent를 병렬로 띄우는 구조다.
이건 앞으로 미디어 제작 AI의 중요한 방향이 될 가능성이 높다. 단일 모델이 한 번에 완성본을 뱉는 방식보다, 작업을 작은 제작 단위로 나누고 각 단위의 산출물을 검수 가능한 파일로 남기는 방식이 제품화에 더 유리하다.
한국 개발자와 운영자에게 중요한 실무 해석
video-use를 당장 도입해야 한다는 뜻은 아니다. 오히려 지금 봐야 할 것은 도구 자체보다 설계 패턴이다.
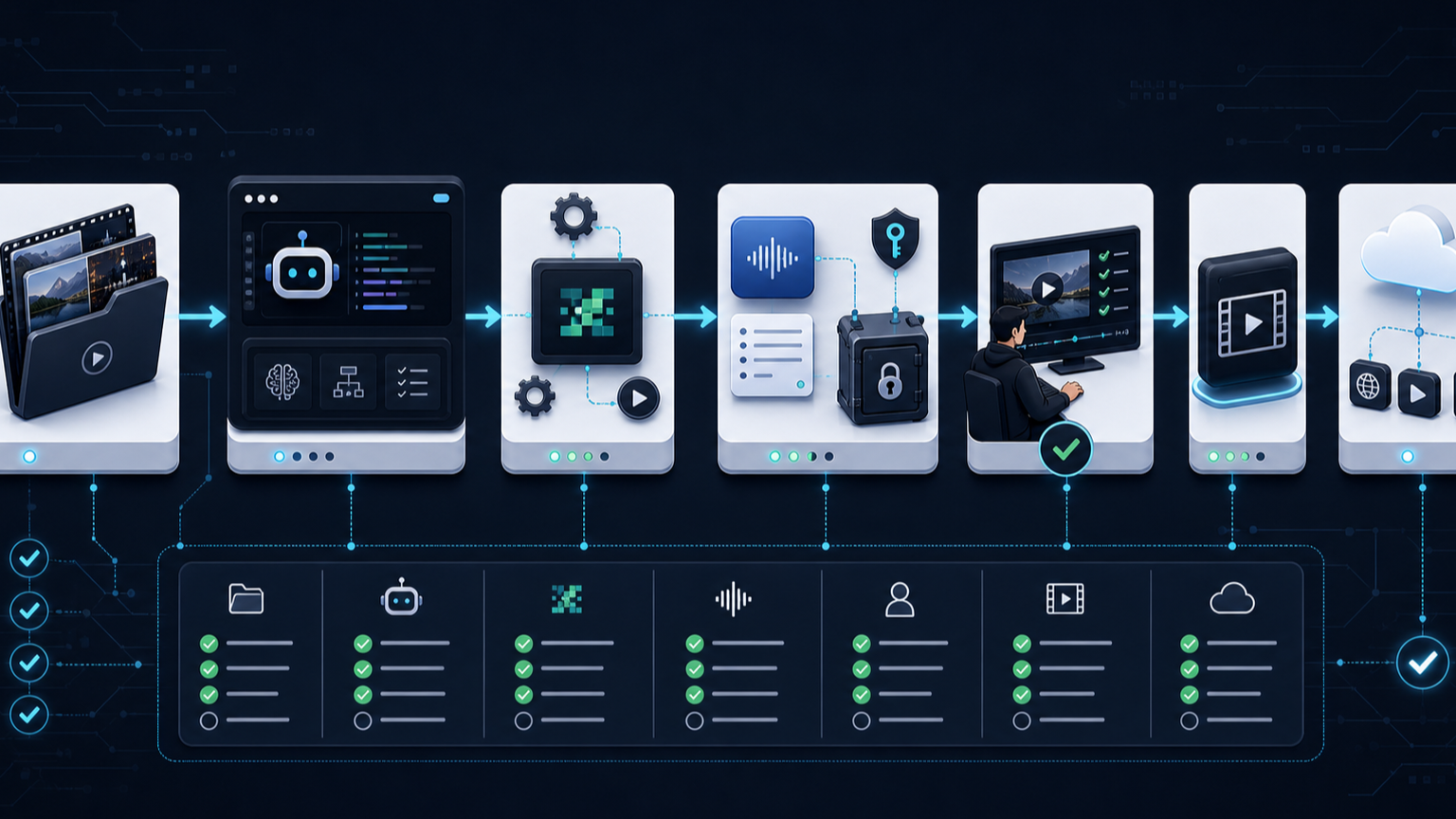
1) 멀티모달 에이전트의 병목은 모델 성능보다 representation이다
“비디오를 이해하는 모델”이 있어도 모든 프레임을 다 넣는 방식은 비용과 지연시간, 디버깅 측면에서 나쁘다. 실무에서는 source를 어떤 텍스트/이미지/메타데이터 표면으로 바꿔 에이전트에게 줄지가 더 중요하다. video-use의 transcript + timeline view 구조는 이 점을 잘 보여준다.
2) 에이전트 도구는 UI보다 파일 시스템과 CLI에 먼저 붙는다
video-use는 완성형 SaaS UI보다 ffmpeg, Python helper, skill file, .env, raw footage folder, edit/final.mp4 같은 운영 표면을 전제로 한다. 개발자 도구 관점에서는 자연스럽다. 에이전트는 GUI보다 shell, files, logs, intermediate artifacts에서 훨씬 강하게 작동한다.
3) 품질은 “모델이 알아서”가 아니라 hard rules로 만든다
영상 편집은 감각적인 작업이지만, 깨지면 안 되는 규칙도 많다. 자막 순서, audio fade, word boundary, output timeline offset 같은 것은 취향이 아니라 correctness다. video-use의 SKILL.md는 에이전트 제품에서 domain-specific hard rules가 얼마나 중요한지 보여준다.
4) API key와 외부 서비스 의존성을 운영 설계에 넣어야 한다
install.md는 ElevenLabs API key를 명시적으로 요구한다. transcription 품질과 word-level timestamp가 핵심이기 때문이다. 이 말은 곧, 자동 영상 편집 파이프라인을 제품에 넣을 때도 transcription provider, quota, privacy, source file handling, cache invalidation을 설계해야 한다는 뜻이다.
5) “완성본 생성”보다 “검수 가능한 중간 산출물”이 중요하다
takes_packed.md, edl.json, cached transcript, preview, verification frame, final render처럼 중간 산출물이 남는 구조는 나중에 사람이 개입하거나, 에이전트가 실패를 복구하거나, 품질 문제를 추적하기 좋다. 미디어 AI를 운영 도구로 만들려면 이 흔적이 필요하다.
한계와 주의할 점
아직 이 접근에는 분명한 한계도 있다.
첫째, README 기준으로 video-use는 Claude Code와 shell access를 가진 에이전트 환경에 강하게 기대고 있다. 일반 사용자용 영상 편집 앱이라기보다는 개발자/크리에이터 운영자용 실험에 가깝다.
둘째, transcription provider에 대한 의존성이 있다. word-level timestamp, speaker diarization, audio event가 품질의 중심이라면, 입력 언어와 잡음 환경, speaker 수, 비용 정책이 결과를 크게 흔들 수 있다.
셋째, “AI가 편집한다”는 말은 책임 소재를 흐리기 쉽다. 실제 업무에서는 원본 보관, consent, 저작권, 음성/얼굴 처리, 자막 정확도, 최종 검수 권한을 명확히 해야 한다. 특히 한국 기업 환경에서는 영상에 고객 얼굴, 내부 회의, 영업 자료, 제품 로드맵이 섞일 수 있다. 자동화 전에 data boundary부터 잡아야 한다.
넷째, animation overlay를 sub-agent로 만드는 구조는 강력하지만, 동시에 품질 편차를 만든다. Remotion, Manim, HyperFrames 같은 렌더러를 섞을수록 dependency, runtime, 스타일 일관성, 실패 복구도 같이 운영해야 한다.
그래서 어떤 팀이 먼저 써볼 만한가
가장 먼저 실험해볼 팀은 “영상을 많이 만들지만 전문 편집팀이 항상 붙지는 않는” 조직이다.
- 개발자 유튜브나 제품 업데이트 영상을 자주 만드는 팀
- 세일즈/CS 교육 영상을 내부적으로 빠르게 편집해야 하는 팀
- 데모 영상, 튜토리얼, 릴리즈 노트를 반복 생산하는 스타트업
- 녹화된 인터뷰, 팟캐스트, 웨비나를 짧은 클립으로 재가공하는 팀
- AI coding agent를 이미 쓰고 있고, shell 기반 workflow에 익숙한 팀
반대로 브랜드 캠페인, 고급 광고, 영화적 편집처럼 인간 편집자의 미세한 감각이 핵심인 작업에는 아직 보조 도구로 보는 편이 안전하다. 이 도구의 강점은 “최고의 편집 감각”보다 반복되는 영상 운영 업무를 텍스트·CLI·검수 가능한 산출물로 바꾸는 것에 있다.
결론: 영상 편집도 에이전트가 다룰 수 있는 작업면으로 재설계되고 있다
browser-use/video-use는 완성형 제품이라기보다 방향성을 보여주는 신호에 가깝다. 웹 자동화에서 에이전트가 DOM과 action surface를 필요로 했듯, 영상 편집에서도 에이전트는 raw pixel stream보다 transcript, timeline view, EDL, render helper, self-eval checkpoint를 필요로 한다.
이 관점에서 보면 video-use의 의미는 분명하다. 영상 AI의 다음 경쟁은 “모델이 얼마나 영상을 잘 이해하느냐”만이 아니다. 영상을 에이전트가 읽고 조작하고 검수할 수 있는 운영 단위로 얼마나 잘 쪼개느냐가 중요해진다.
한국 개발자와 빌더에게도 이건 좋은 힌트다. AI 기능을 붙일 때 모델 호출만 생각하면 데모에서 멈춘다. 반대로 source representation, domain hard rules, intermediate artifacts, self-evaluation loop, human approval gate를 함께 설계하면 도구가 된다. video-use가 보여주는 건 바로 그 차이다.