- Published on
AWS AgentCore Gateway와 Memory: 에이전트 운영은 이제 VPC와 네임스페이스 설계 문제다
- Authors

- Name
- Kyunghyun Park
- @devkhpark
AWS AgentCore · Gateway · Memory · MCP Proxy · Model Agility
AWS가 4월 말에 낸 AgentCore 관련 글들을 한꺼번에 보면, 메시지는 꽤 선명하다. 에이전트 경쟁은 “어떤 모델을 쓰느냐”에서 끝나지 않는다. 실제 기업 환경에서는 에이전트가 어떤 내부 리소스에 접근하고, 어떤 장기 메모리를 읽고, 어떤 tool call을 남기고, 모델을 어떻게 교체할 수 있는지가 더 큰 병목이 된다.

이번 글은 AWS Machine Learning Blog의 AgentCore Gateway private resource access, AgentCore Memory namespace design, serverless MCP proxy on AgentCore Runtime, Generative AI Model Agility Solution을 함께 읽고, 한국 개발팀과 AI 제품 운영팀이 지금 설계해야 할 포인트를 정리한 것이다.
기준 시점: 2026-05-02에 확인한 공개 자료 기준이다. AgentCore, Bedrock, VPC, IAM, MCP 관련 기능과 리전·권한·가격 정책은 바뀔 수 있으므로 실제 도입 전 AWS 공식 문서를 다시 확인해야 한다.
핵심 thesis: 에이전트는 모델 API가 아니라 운영 주체가 됐다
요즘 “AI agent”라는 말은 너무 쉽게 쓰인다. 채팅창에서 tool call 몇 번 돌리면 에이전트라고 부르고, 워크플로 자동화 UI에 LLM을 붙여도 에이전트라고 부른다. 하지만 프로덕션에 올리는 순간 질문은 완전히 달라진다.
- 이 에이전트가 내부 API에 접근해도 되는가?
- 접근한다면 public internet을 거쳐도 되는가?
- 한 사용자의 장기 메모리가 다른 사용자에게 노출될 가능성은 없는가?
- tool call 입력을 정책에 맞게 검사하고 감사 로그로 남길 수 있는가?
- 지금 쓰는 모델을 다른 모델로 바꿀 때 품질·비용·지연시간을 비교할 수 있는가?
AWS의 AgentCore 흐름은 이 질문들에 대한 인프라 답변에 가깝다. 즉 에이전트를 “프롬프트가 긴 앱 기능”이 아니라 네트워크, IAM, 메모리, 관측성, 평가, 모델 마이그레이션을 가진 운영 주체로 본다.
이 관점은 다소 지루하지만 중요하다. 데모에서는 모델이 얼마나 똑똑한지가 보인다. 운영에서는 모델이 무엇에 접근했고, 무엇을 기억했고, 무엇을 호출했고, 왜 실패했는지가 더 중요하다.
AgentCore Gateway: private resource 접근은 에이전트의 첫 번째 보안 경계다
AWS의 AgentCore Gateway private resource access 글은 아주 현실적인 문제에서 시작한다. 프로덕션 에이전트는 내부 API, 데이터베이스, private resource에 접근해야 한다. 그런데 이 리소스들은 보통 VPC 안에 있고, public internet에 그대로 열면 안 된다.
AWS가 제시하는 구조는 AgentCore Gateway가 VPC 내부 endpoint에 접근할 수 있도록 Resource Gateway와 Resource Configuration을 이용하는 방식이다. 여기서 중요한 포인트는 “VPC에 연결된다”가 아니라 접근 범위를 전체 VPC가 아니라 특정 resource로 좁힌다는 점이다.
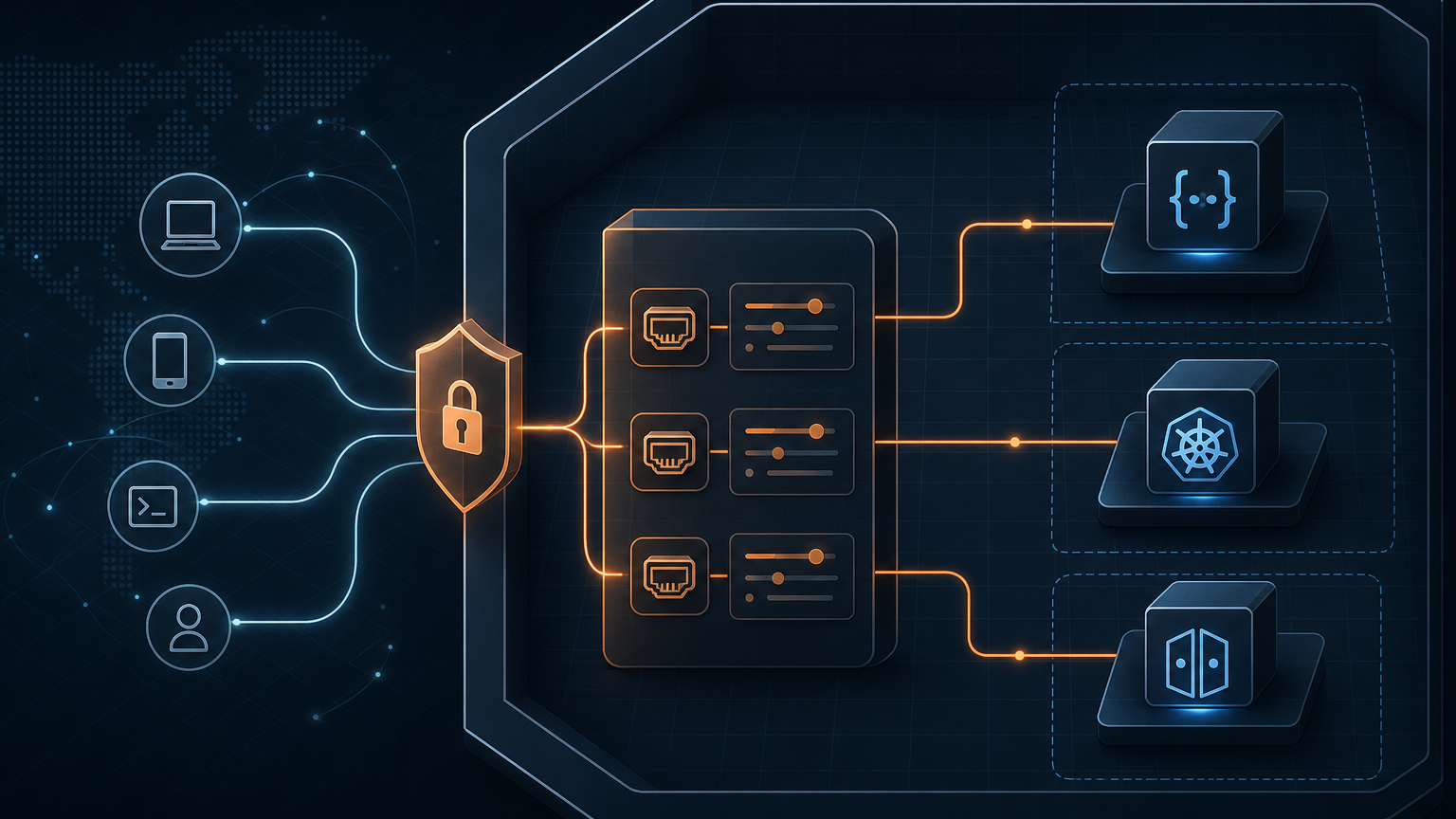
AWS 글은 세 가지 시나리오를 다룬다.
- private Amazon API Gateway endpoint에 연결한다.
- Amazon EKS에서 돌고 있는 MCP server와 통합한다.
- private REST API에 접근한다.
이 조합이 말하는 바는 분명하다. 에이전트가 기업 내부 시스템을 다루려면 단순히 API key를 넣는 수준으로는 부족하다. 네트워크 경계, endpoint 단위의 scope, cross-account 구조, subnet, ENI, Resource Gateway 같은 인프라 요소가 에이전트 설계의 일부가 된다.
한국 개발팀 관점에서는 여기서 바로 실무 질문이 나온다.
- 사내 업무 에이전트가 접근할 내부 API 목록은 누가 승인하는가?
- 에이전트별로 접근 가능한 endpoint를 분리할 것인가, 공통 gateway를 둘 것인가?
- tool server가 Kubernetes 안에 있다면 ingress, service, 인증, 네트워크 정책을 어떻게 묶을 것인가?
- 외부 LLM provider를 쓰더라도 tool 실행 경로는 private network 안에 유지할 수 있는가?
앞으로 “AI agent 보안”은 prompt injection 방어만으로 설명하기 어렵다. 실제 사고는 모델 출력뿐 아니라 잘못 열린 리소스 경로에서 날 가능성이 크다.
AgentCore Memory: 장기 기억은 저장소보다 네임스페이스 설계가 먼저다
에이전트 메모리도 비슷하다. 많은 팀이 “사용자 선호를 기억하자”, “이전 대화를 기억하자” 수준으로 시작하지만, 운영 단계에서는 메모리 구조가 곧 보안 구조가 된다.
AWS의 AgentCore Memory namespace 글은 이 점을 직접 짚는다. AgentCore Memory에서 namespace는 장기 메모리 record를 조직하고 검색하고 접근 제어하는 기준이다. AWS는 이를 파일시스템 path, DynamoDB partition key, S3 folder hierarchy와 비슷한 정신 모델로 설명한다.
예를 들어 한 사용자의 preference는 /actor/customer-123/preferences/ 아래 둘 수 있고, 특정 session summary는 /actor/customer-123/session/session-789/summary/ 같은 구조로 둘 수 있다. 중요한 건 이 path가 단순한 이름표가 아니라 retrieval granularity와 isolation boundary를 결정한다는 점이다.
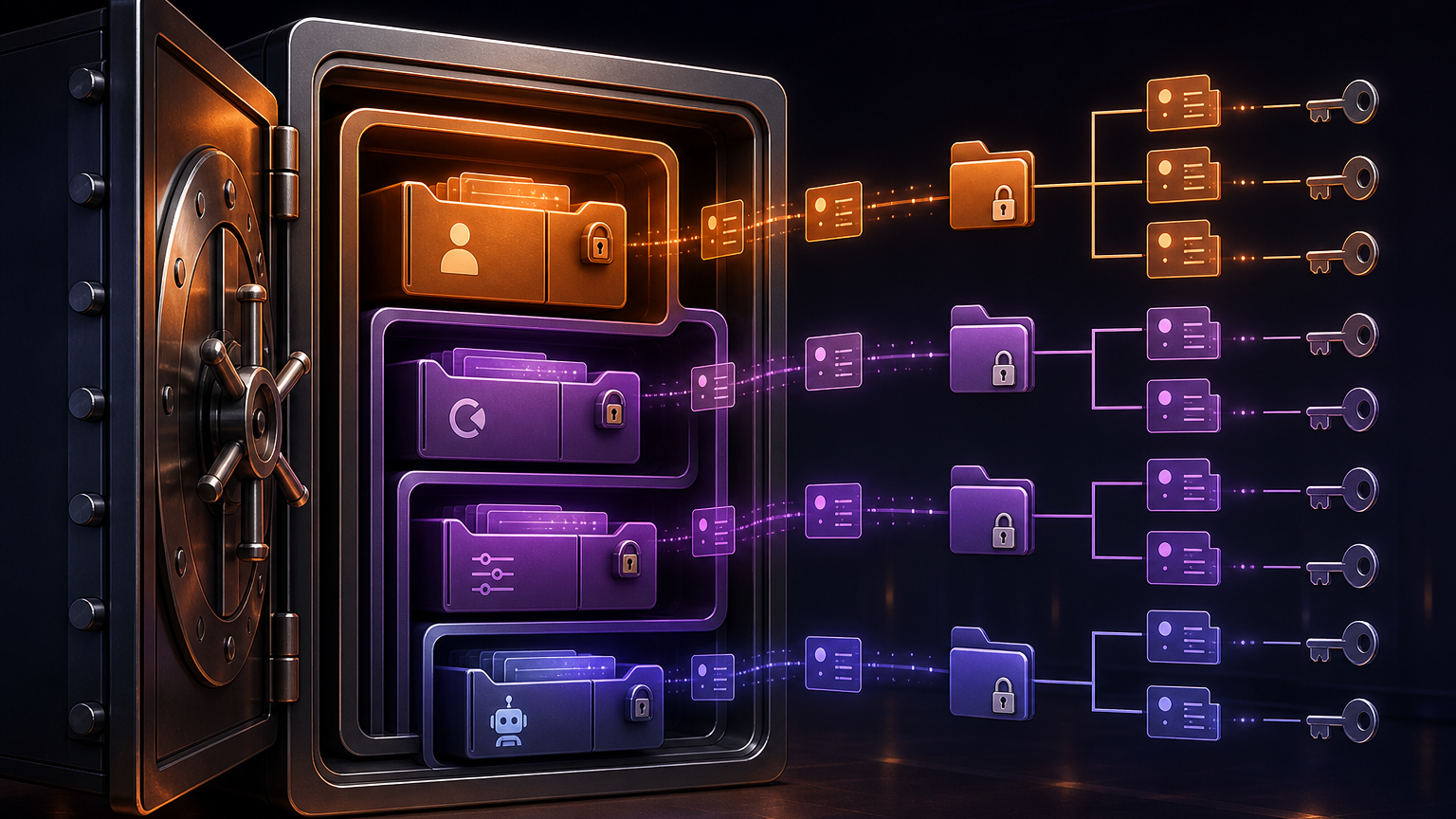
메모리 설계를 대충 하면 두 가지 문제가 생긴다.
첫째, 검색 품질이 떨어진다. 모든 기억을 한 바구니에 넣으면 에이전트는 현재 작업과 무관한 context를 끌고 온다. 장기 기억이 많아질수록 irrelevant context retrieval은 품질 문제이자 비용 문제가 된다.
둘째, 보안 경계가 흐려진다. 한 사용자, 한 tenant, 한 agent, 한 workspace의 기억이 같은 공간에서 섞이면 나중에 IAM 정책으로 보정하기 어렵다. 처음부터 namespace hierarchy를 access pattern 기준으로 짜야 한다.
실무적으로는 아래 원칙이 유용하다.
- 사용자 단위 memory와 agent 단위 memory를 섞지 않는다.
- session summary, preference, policy note, task history를 같은 namespace depth에 두지 않는다.
- retrieval query가 필요한 level과 IAM policy가 필요한 level을 함께 설계한다.
- “일단 저장하고 나중에 필터링”보다 “처음부터 잘못 검색될 수 없게 구조화”하는 편이 안전하다.
이건 벡터DB 선택보다 앞선 문제다. 메모리 시스템의 핵심은 저장소가 아니라 누가 어떤 기억을 어떤 granularity로 다시 읽을 수 있느냐다.
MCP proxy: tool call 사이에 정책을 넣을 수 있어야 한다
MCP는 에이전트가 외부 도구를 쓰게 하는 표준 인터페이스로 빠르게 퍼지고 있다. 하지만 tool 연결이 쉬워질수록 운영 리스크도 커진다. 파일 시스템, DB, CRM, 결제 API, 내부 admin endpoint가 모두 MCP tool로 연결된다면, 에이전트는 사실상 권한 있는 실행 주체가 된다.
AWS의 serverless MCP proxy 글은 이 지점에서 중요하다. 글의 핵심은 AgentCore Runtime 위에 stateless MCP proxy를 올려 upstream MCP server의 tool을 discovery하고, custom logic을 적용한 뒤 요청을 forwarding하는 구조다.
왜 proxy가 필요한가? AWS는 production MCP interaction에 governance, controls, observability가 필요하다고 설명한다. 예를 들어 tool input을 backend에 보내기 전에 sanitize하거나, 특정 format의 audit trail을 만들거나, protocol layer에서 민감한 데이터를 redact해야 할 수 있다.
이건 단순한 middleware가 아니다. 에이전트 제품에서는 MCP proxy가 사실상 정책 삽입 지점이 된다.
- tool 호출 전 input validation
- PII·secret·customer data redaction
- 내부 감사 포맷에 맞춘 로그 생성
- 조직별 허용 tool 제한
- prompt injection 의심 패턴 차단
- tool call 결과의 후처리 및 masking
에이전트가 실패했을 때 “모델이 그렇게 말했다”는 설명은 충분하지 않다. 어떤 tool이 어떤 입력으로 호출됐고, 어느 계층에서 정책 검사가 됐고, 어떤 로그가 남았는지 보여줄 수 있어야 한다. 그래서 MCP proxy는 편의 기능이 아니라 compliance와 incident response의 일부다.
Model agility: 모델 교체는 나중에 하는 리팩터링이 아니라 처음부터 들어가는 운영 절차다
AWS가 같은 날 공개한 Generative AI Model Agility Solution도 이 흐름과 연결된다. 글은 LLM family 간 전환이나 같은 family 내 버전 업그레이드에 구조화된 migration approach와 standardized process가 필요하다고 말한다.
여기서 model agility는 “여러 모델을 골라 쓸 수 있다”는 마케팅 문구가 아니다. AWS가 강조한 포인트는 cost, latency, accuracy, quality를 비교하고, prompt conversion과 optimization을 수행하고, evaluation을 통해 source model과 destination model을 정량적으로 비교하는 절차다.

에이전트에서는 이 문제가 더 어렵다. 일반 챗봇은 최종 답변만 비교해도 어느 정도 판단할 수 있다. 하지만 에이전트는 중간 tool call, memory retrieval, retry, latency, 비용, failure mode가 모두 품질의 일부다.
그래서 모델 교체 절차에는 최소한 아래 항목이 들어가야 한다.
| 점검 항목 | 왜 중요한가 |
|---|---|
| task success rate | 최종 사용자가 원하는 작업을 실제로 끝냈는지 본다. |
| tool call accuracy | 올바른 도구를 올바른 순서와 인자로 호출했는지 본다. |
| private resource boundary | 새 모델이 허용되지 않은 리소스를 요구하지 않는지 확인한다. |
| memory retrieval quality | 장기 기억을 과하게 또는 부족하게 끌어오지 않는지 본다. |
| latency / cost | 모델 자체 비용보다 전체 agent loop 비용을 본다. |
| auditability | 실패 재현과 규제 대응에 필요한 trace가 남는지 본다. |
즉 model agility는 공급자 lock-in 회피 전략이기도 하지만, 더 본질적으로는 에이전트 운영 품질을 계속 측정하고 교체 가능한 상태로 유지하는 훈련이다.
한국 개발팀이 바로 가져갈 설계 체크리스트
AgentCore를 당장 쓰지 않더라도 이번 AWS 신호에서 배울 수 있는 건 많다. 특히 내부 도구를 쓰는 AI agent를 만들고 있다면 아래 체크리스트를 초기에 넣는 편이 좋다.
1) 에이전트별 private resource inventory를 만든다
에이전트가 접근해야 하는 내부 API, DB, queue, file store, SaaS connector를 목록으로 만든다. “나중에 필요하면 붙이자”가 아니라, agent scope별로 허용 resource를 먼저 정해야 한다.
2) tool server와 business API를 분리한다
모델이 직접 business API를 호출하게 하지 말고, 중간 tool server나 proxy 계층을 둔다. 이 계층에서 schema validation, permission check, logging, rate limit, redaction을 처리한다.
3) memory namespace를 access pattern 기준으로 설계한다
메모리를 user, tenant, workspace, session, agent role, memory type 기준으로 나눈다. 검색 편의만 보고 flatten하면 나중에 보안·품질 문제가 같이 온다.
4) MCP proxy 또는 interceptor 위치를 미리 정한다
MCP tool이 늘어날수록 중앙 정책 지점이 필요하다. 모든 tool server에 개별 보안 로직을 흩뿌리는 대신, proxy나 gateway에서 공통 정책을 적용할 수 있는 구조가 낫다.
5) 모델 교체 평가표를 제품 요구사항에 넣는다
모델을 바꾸고 싶을 때마다 임시 테스트를 만들면 늦다. 에이전트별 golden task, tool call trace, 비용·지연시간 기준, regression test를 기본 운영 자산으로 관리해야 한다.
SEO 관점에서 봐도 중요한 키워드는 “agent runtime”이다
한국어 검색에서는 아직 “AI 에이전트 만들기”, “MCP 서버”, “Bedrock AgentCore”, “에이전트 메모리”, “AI agent 보안” 같은 키워드가 각각 흩어져 있다. 하지만 실무 의미는 하나로 합쳐진다. 앞으로 개발팀이 찾게 될 답은 “에이전트를 어떻게 만든다”가 아니라 에이전트 런타임을 어떻게 운영한다에 가깝다.
이 관점에서 AgentCore Gateway와 Memory는 꽤 좋은 신호다. AWS는 모델 성능 발표보다 네트워크, memory namespace, MCP proxy, model migration 같은 더 지루한 구성요소를 전면에 놓고 있다. 바로 이 지루함이 프로덕션 AI의 핵심이다.
짧은 결론
AWS AgentCore Gateway와 Memory를 단순한 Bedrock 기능 추가로 보면 작게 보인다. 하지만 Gateway, Memory, MCP proxy, model agility를 함께 보면 다른 그림이 나온다. 에이전트는 이제 모델 API를 감싼 앱 기능이 아니라, private network와 IAM과 memory namespace와 감사 가능한 tool call을 가진 운영 주체가 되고 있다.
한국 개발팀에게 실무적인 결론은 명확하다. 에이전트 프로젝트를 시작할 때 프롬프트와 모델 선택만 먼저 정하지 말고, resource boundary, memory hierarchy, policy proxy, evaluation/migration 절차를 같이 설계해야 한다. 이 네 가지가 없으면 데모는 빨리 만들 수 있어도 운영 가능한 에이전트로 가는 길은 오히려 더 멀어진다.
참고 자료
- AWS Machine Learning Blog, Configuring Amazon Bedrock AgentCore Gateway for secure access to private resources, 2026-04-30.
- AWS Machine Learning Blog, Organizing Agents’ memory at scale: Namespace design patterns in AgentCore Memory, 2026-04-29.
- AWS Machine Learning Blog, Run custom MCP proxies serverless on Amazon Bedrock AgentCore Runtime, 2026-04-29.
- AWS Machine Learning Blog, AWS Generative AI Model Agility Solution: A comprehensive guide to migrating LLMs for generative AI production, 2026-04-30.