- Published on
olmOCR가 보여준 문서 AI의 다음 병목: OCR이 아니라 검증 가능한 데이터 파이프라인이다
- Authors

- Name
- Kyunghyun Park
- @devkhpark
AllenAI · olmOCR · PDF-to-Markdown · Document AI · RAG 데이터 파이프라인
AI 제품을 만들 때 “문서를 넣으면 답해주는 챗봇”은 가장 쉬운 데모처럼 보인다. 하지만 실제 운영에 들어가면 병목은 모델이 아니라 훨씬 더 지루한 곳에서 터진다. PDF의 읽기 순서가 깨지고, 표가 문장처럼 흘러가고, 수식의 x와 y가 바뀌고, 헤더·푸터가 매 페이지마다 반복되고, 스캔 품질이 낮은 문서가 임베딩 저장소를 오염시킨다.
AllenAI의 olmOCR가 오늘 GitHub Trending에서 다시 눈에 띈 이유도 여기에 있다. 이 프로젝트는 단순히 “OCR을 잘한다”는 도구가 아니다. 더 정확히 말하면 문서 AI의 원재료를 검증 가능한 텍스트 데이터로 바꾸는 오픈소스 파이프라인에 가깝다.
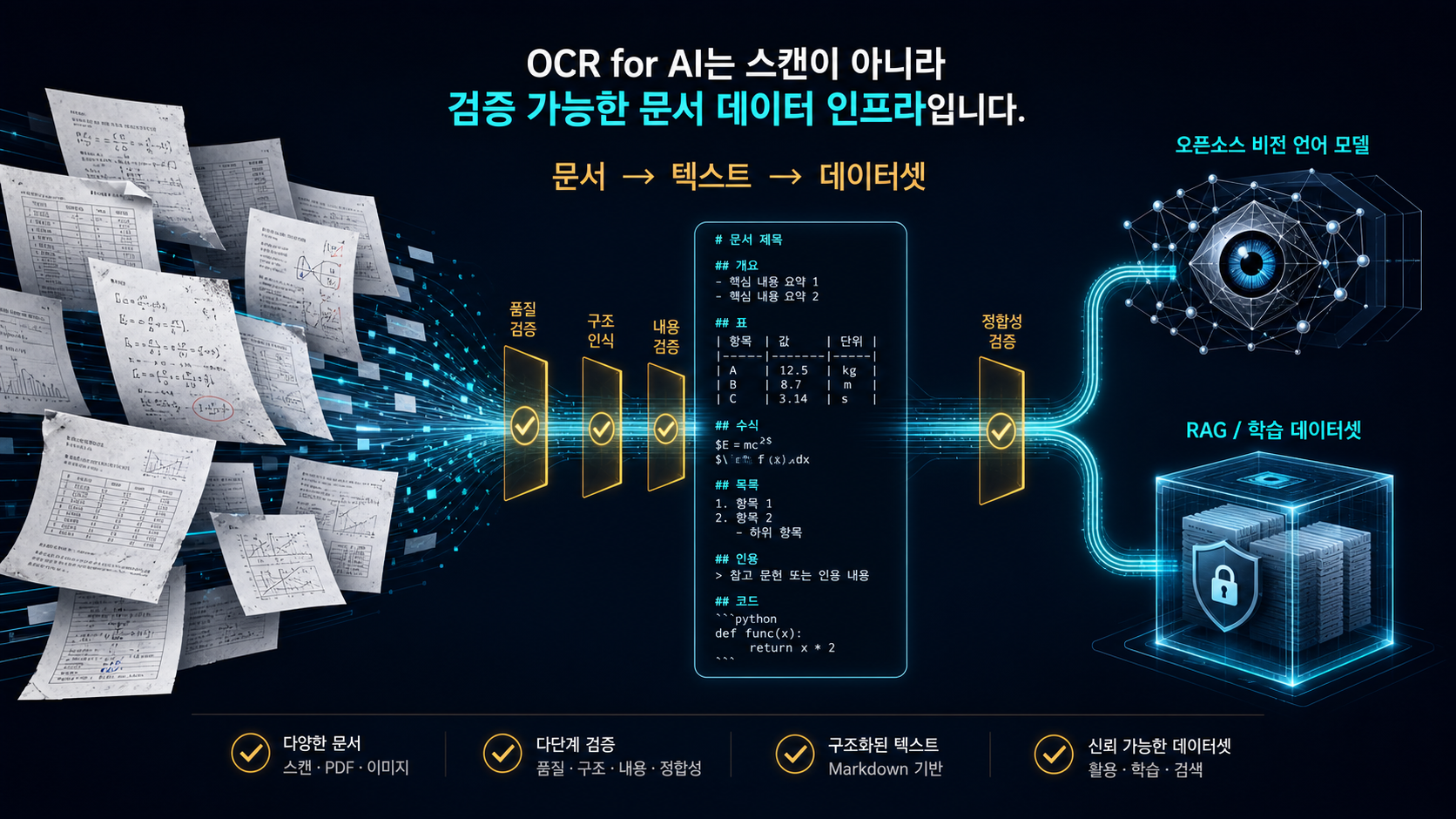
이 글의 핵심 주장은 단순하다. PDF·스캔 문서·표·수식·다단 레이아웃이 많은 조직에서는 이제 “OCR 엔진을 고른다”보다 문서 변환을 측정 가능한 데이터 엔지니어링 문제로 다룰 수 있느냐가 더 중요해진다. olmOCR는 그 방향을 꽤 선명하게 보여준다.
왜 지금 문서 OCR이 다시 중요해졌나
LLM과 RAG가 널리 쓰이면서 문서는 다시 핵심 데이터 원천이 됐다. 계약서, 매뉴얼, 정책 문서, 연구 논문, 제품 스펙, 고객 응대 기록, 공공 보고서, 레거시 스캔 자료는 대부분 “사람이 보기 좋은 형식”으로 저장돼 있다. 문제는 LLM이 원하는 입력은 사람이 보는 PDF가 아니라 자연스러운 순서로 정렬된 텍스트와 구조 정보라는 점이다.
olmOCR의 논문 제목은 이 방향을 노골적으로 말한다. Unlocking Trillions of Tokens in PDFs with Vision Language Models. 논문 초록은 PDF가 언어모델 학습을 위한 수조 개의 고품질 토큰을 제공할 수 있지만, 다양한 포맷과 시각적 레이아웃 때문에 충실한 추출이 어렵다고 설명한다. 즉 PDF는 그냥 파일 포맷이 아니라 아직 제대로 열지 못한 데이터 광산이다.
여기서 기존 OCR과 문서 AI의 요구사항이 갈라진다.
- 검색 가능한 텍스트만 있으면 되는가?
- 표의 행·열 의미가 보존돼야 하는가?
- 수식의 변수 하나가 틀리면 안 되는가?
- 다단 논문에서 본문 순서가 자연스럽게 이어져야 하는가?
- 헤더·푸터·페이지 번호 같은 반복 노이즈를 제거해야 하는가?
- 같은 파이프라인을 수십만~수백만 페이지에 안정적으로 돌려야 하는가?
RAG나 학습 데이터 구축에서는 마지막 질문들이 더 중요하다. 문서를 대충 텍스트로 바꾸면 벡터DB에는 무언가 들어가지만, 답변 품질은 조용히 망가진다.
olmOCR의 포인트는 “텍스트 추출”이 아니라 “linearization”이다
GitHub README에서 olmOCR는 PDF, PNG, JPEG 기반 문서를 clean Markdown으로 변환하고, 수식·표·손글씨·복잡한 포맷을 지원하며, 헤더와 푸터를 자동 제거하고, 그림·다단 레이아웃·인셋이 있어도 자연스러운 reading order로 변환한다고 설명한다.
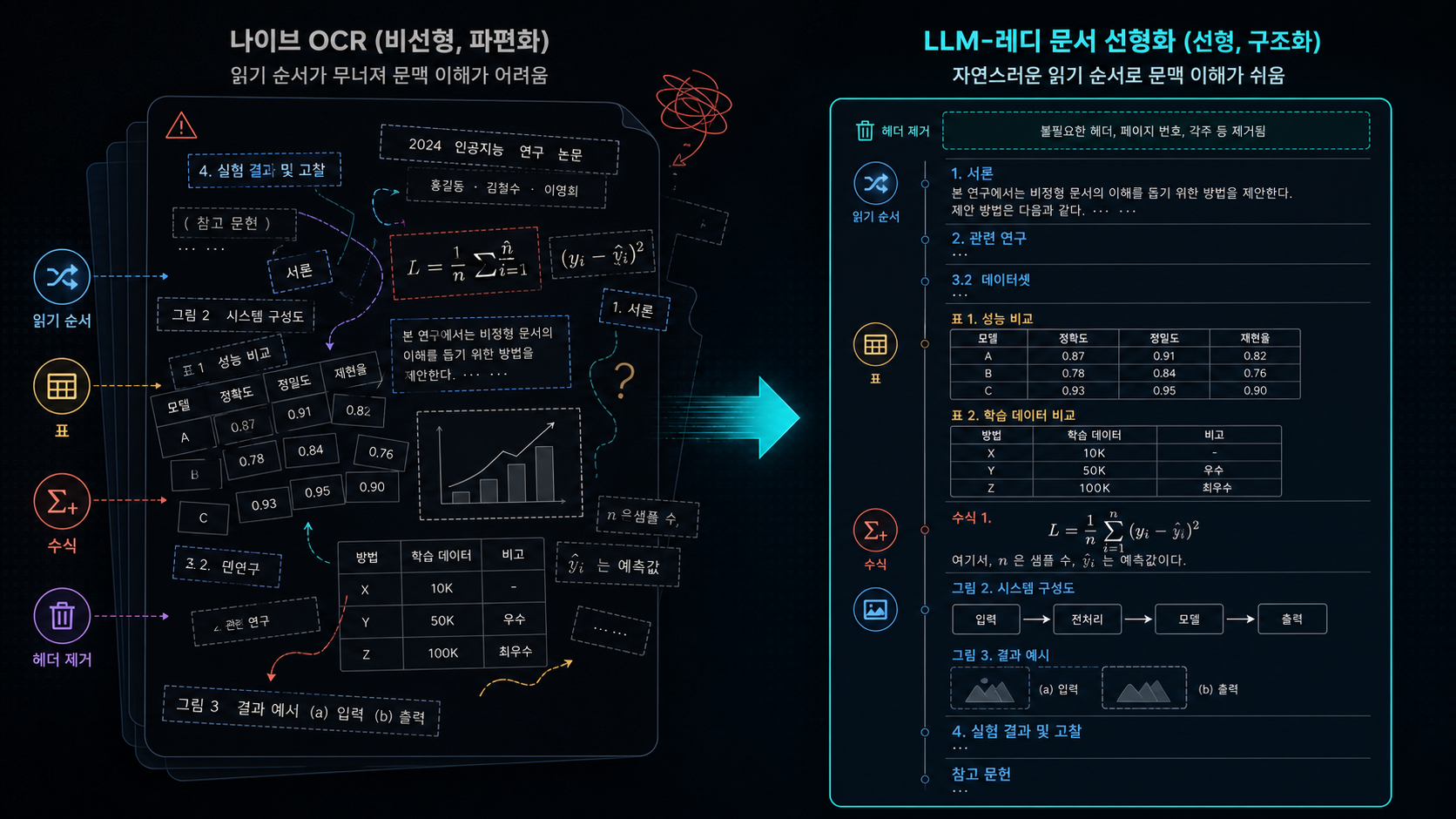
여기서 키워드는 OCR보다 linearization이다. 문서 한 페이지는 2차원이다. 사람은 시각적으로 제목, 본문, 표, 각주, 이미지 캡션, 사이드바를 구분한다. 하지만 LLM 입력은 결국 1차원 시퀀스다. 그래서 문서 AI의 핵심 문제는 “글자를 읽었는가”가 아니라, 2차원 문서 구조를 어떤 순서와 형식의 텍스트로 펼쳤는가다.
예를 들어 다단 논문에서 왼쪽 열 첫 문단 다음에 오른쪽 열 첫 문단을 붙이면 문맥은 깨진다. 표를 행 단위로 보존하지 못하면 숫자는 남아도 의미는 사라진다. 수식에서 첨자 하나가 잘못 추출되면 검색 결과는 그럴듯해도 실제 답변은 틀릴 수 있다.
그래서 olmOCR 같은 도구를 볼 때는 “OCR 정확도 몇 퍼센트”보다 아래 질문이 더 실무적이다.
- 문서의 자연스러운 읽기 순서를 얼마나 잘 복원하는가?
- 표, 리스트, 수식, 섹션 구조를 Markdown에 얼마나 안정적으로 남기는가?
- 헤더·푸터·페이지 번호 같은 반복 노이즈를 얼마나 제거하는가?
- 실패한 페이지를 나중에 재처리하거나 검증할 수 있는가?
- 비용과 속도가 대량 처리에 맞는가?
이 관점에서 olmOCR는 단순한 OCR 라이브러리라기보다, 문서 원천을 LLM 데이터로 바꾸는 중간 계층이다.
벤치마크 방식이 흥미롭다: edit distance보다 “단위 테스트”에 가깝다
olmOCR-Bench 문서는 평가 철학을 꽤 명확히 밝힌다. 이 벤치마크는 문서 페이지에 대한 여러 “fact”를 테스트한다. 예를 들어 OCR 결과 안에 특정 문장이 정확히 포함돼 있는지 확인하는 식이다. README는 edit distance 같은 soft metric을 피한다고 설명한다. 이유도 실무적이다. 문서 안에 여러 기사나 블록이 있을 때 상대적 순서가 약간 달라도 의미상 맞을 수 있고, 반대로 수식에서 x와 y가 바뀌는 작은 편집 거리는 이해에 치명적일 수 있기 때문이다.
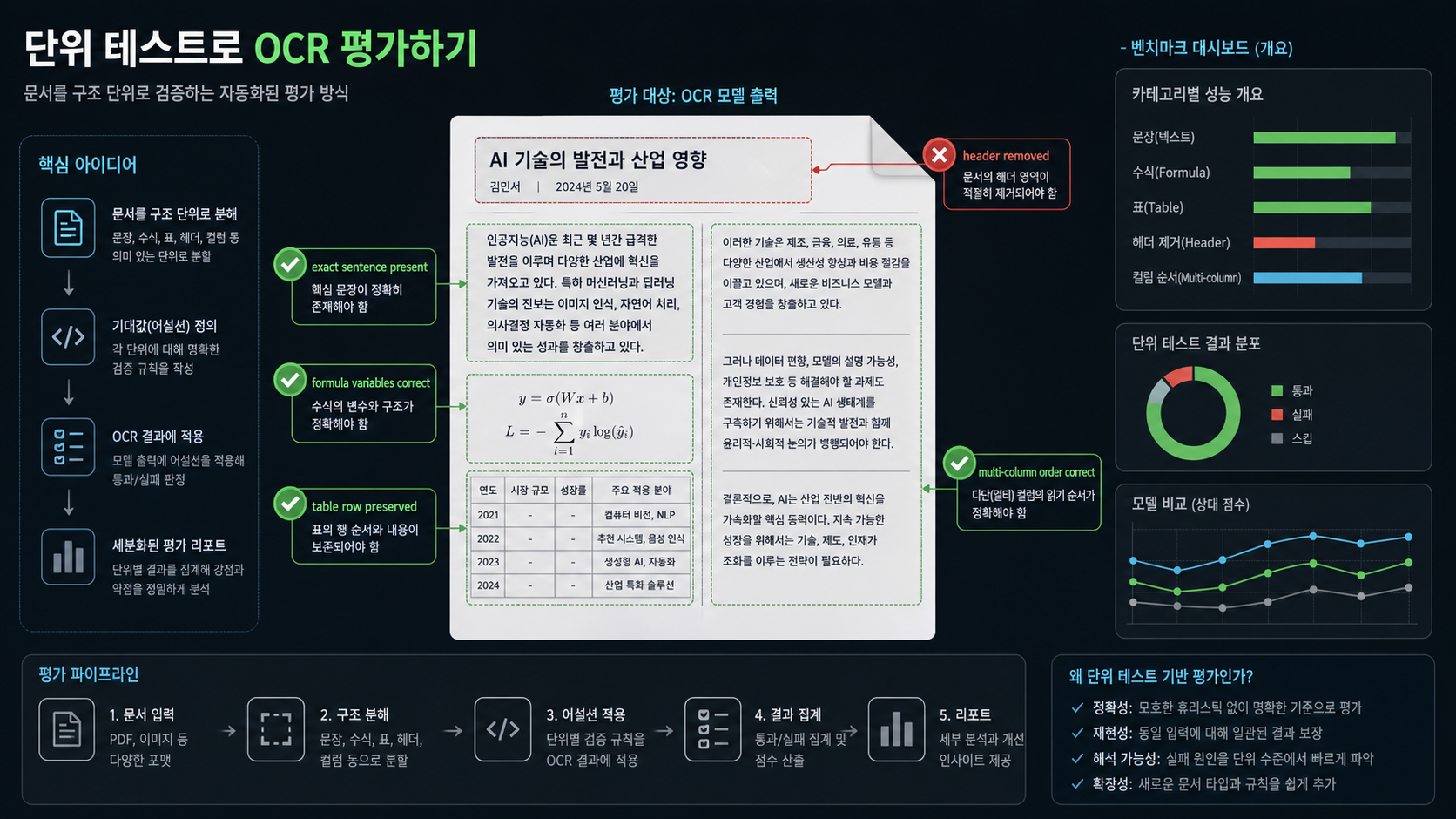
이 접근이 중요한 이유는 문서 AI 평가를 더 운영 친화적으로 만들기 때문이다. 단순한 평균 점수 하나보다, “우리 조직 문서에서 반드시 보존돼야 하는 조건”을 테스트로 만들 수 있기 때문이다.
예를 들어 한국 기업의 내부 RAG라면 이런 테스트가 더 의미 있을 수 있다.
- 계약서의 조항 번호가 본문과 같이 남아 있는가?
- 표 안의 단가, 수량, 합계가 같은 행에 유지되는가?
- PDF 하단의 반복 기밀 문구가 본문으로 섞이지 않는가?
- 스캔 품질이 낮은 문서에서도 날짜와 금액이 누락되지 않는가?
- 다단 보고서에서 왼쪽 열과 오른쪽 열의 순서가 섞이지 않는가?
olmOCR 2 논문은 이 방향을 더 밀어붙인다. AllenAI는 olmOCR-2-7B-1025가 RLVR, 즉 verifiable rewards 기반 강화학습으로 학습됐고, 그 reward가 다양한 binary unit test라고 설명한다. 합성 문서의 HTML 원본과 테스트 케이스를 이용해 challenging layout을 만들고, 수식 변환·표 파싱·다단 레이아웃에서 개선을 보였다는 설명도 나온다.
이건 OCR 성능 향상보다 더 큰 신호다. 문서 변환 모델도 이제 “그럴듯한 결과 생성”이 아니라 검증 가능한 조건을 통과하도록 학습·평가되는 방향으로 가고 있다.
비용 신호: 문서 파이프라인은 모델 품질만큼 단가가 중요하다
첫 번째 olmOCR 논문 초록은 비용 비교도 직접 언급한다. 최고급 VLM을 API로 쓰면 품질은 좋을 수 있지만, GPT-4o 기준 백만 PDF 페이지당 6,240달러 이상이 될 수 있고, PDF를 외부 API로 보낼 수 없는 경우도 있다고 지적한다. 반면 olmOCR는 백만 PDF 페이지를 176달러에 변환할 수 있도록 최적화됐다고 설명한다. README 역시 백만 페이지당 200달러 미만이라는 비용 신호를 내세운다.
물론 이 숫자는 하드웨어, 배치 크기, 문서 난이도, 재시도 정책에 따라 달라진다. 그래도 메시지는 분명하다. 대량 문서 처리에서 비용은 부가 조건이 아니라 아키텍처 조건이다.
한국 개발팀이 사내 문서 AI를 만든다고 가정해보자. 처음에는 1,000페이지 데모로 충분하다. 하지만 실제 배포 후에는 부서별 문서, 과거 스캔 자료, 고객 제출 파일, 제품 매뉴얼, 법무 문서가 계속 들어온다. 이때 페이지당 비용과 재처리 비용을 무시하면 RAG 품질보다 먼저 예산이 무너진다.
그래서 문서 AI 운영자는 다음 항목을 초기에 정해야 한다.
- 어떤 문서는 고품질 VLM OCR을 쓸 것인가?
- 어떤 문서는 기존 텍스트 추출기로 충분한가?
- 스캔·표·수식이 많은 문서만 별도 고급 파이프라인으로 보낼 것인가?
- GPU 배치 처리와 큐 기반 재시도를 어떻게 운영할 것인가?
- 변환 실패·저신뢰 페이지를 어떻게 검출하고 다시 처리할 것인가?
olmOCR의 의미는 “무조건 이 도구를 써라”가 아니다. 문서 AI를 비용·검증·처리량까지 포함한 파이프라인으로 보라는 신호다.
실무 해석: RAG 품질 문제의 상당수는 검색 전에 이미 결정된다
많은 RAG 프로젝트는 검색 결과가 이상하면 임베딩 모델, chunk size, reranker, 프롬프트부터 바꾼다. 물론 그 레이어도 중요하다. 하지만 문서 변환이 망가지면 그 이후의 모든 튜닝은 오염된 입력 위에서 진행된다.

특히 PDF 기반 RAG에서는 아래 문제가 자주 발생한다.
1) chunking 이전에 reading order가 깨진다
문서가 잘못 펼쳐지면 chunking은 이미 틀어진 문맥을 잘라낼 뿐이다. 두 단락이 섞이거나 표와 설명이 분리되면, 임베딩은 그 오염된 조합을 그대로 벡터화한다.
2) 표와 수식은 “텍스트 유무”만으로 평가할 수 없다
문자가 다 들어 있어도 행·열 관계가 깨지면 답변은 틀린다. 수식은 한 글자 차이도 의미가 크다. 그래서 문서 변환 평가는 단순 문자열 유사도보다 사실 검증형 테스트가 더 잘 맞는다.
3) 헤더·푸터 노이즈는 검색 품질을 조용히 갉아먹는다
페이지마다 반복되는 회사명, 문서명, 보안 문구, 페이지 번호가 본문처럼 들어가면 검색 결과가 불필요하게 반복된다. RAG 답변이 “문서 제목”만 과도하게 인용하거나 비슷한 chunk를 계속 가져오는 문제가 여기서 생긴다.
4) 문서별 라우팅이 필요하다
모든 PDF를 최고급 VLM에 넣는 것은 비싸다. 모든 PDF를 저렴한 파서에 넣는 것은 품질 리스크가 크다. 운영에서는 문서 종류, 스캔 여부, 표/수식 밀도, 보안 등급에 따라 변환 경로를 나눠야 한다.
이 지점에서 olmOCR는 하나의 도구를 넘어 설계 패턴을 제안한다. 문서 ingestion은 “파일을 읽는다”가 아니라 파일을 분류하고, 변환하고, 검증하고, 실패를 재처리하고, 비용을 관측하는 작업이다.
MarkItDown류 변환기와 무엇이 다른가
이 블로그에서도 Microsoft MarkItDown을 LLM 문서 파이프라인의 중간 언어로 다룬 적이 있다. 둘은 겹치는 지점이 있지만 역할은 다르다.
MarkItDown류 도구는 여러 파일 포맷을 Markdown으로 보내는 범용 변환 계층에 가깝다. Office 문서, HTML, 오디오, 이미지, PDF 등 다양한 입력을 하나의 텍스트 표면으로 모으는 데 의미가 있다.
반면 olmOCR가 던지는 신호는 더 좁고 깊다. 특히 PDF와 image-based document에서 시각적 레이아웃을 읽고, 자연스러운 순서로 펼치고, 표·수식·손글씨·스캔 품질 같은 어려운 케이스를 다루는 모델 기반 OCR 파이프라인이다.
실무적으로는 둘 중 하나만 고르는 문제가 아니다.
- 일반 문서·웹·Office 포맷은 범용 변환기로 처리한다.
- 스캔 PDF, 논문, 표·수식 많은 문서, 레이아웃이 복잡한 문서는 VLM 기반 OCR 경로로 보낸다.
- 변환 결과는 모두 Markdown 또는 구조화 텍스트로 모은다.
- 품질이 중요한 문서군에는 별도 검증 테스트를 붙인다.
이렇게 보면 문서 AI 스택은 “OCR 엔진 하나”가 아니라 라우팅과 검증을 포함한 ingestion control plane에 가까워진다.
한국 개발팀을 위한 적용 체크리스트
olmOCR를 그대로 쓰든, 다른 OCR/VLM 서비스를 쓰든, 중요한 건 설계 기준이다. 문서 기반 AI 제품을 준비하는 팀이라면 아래 체크리스트를 먼저 보는 편이 좋다.
1) 문서군을 먼저 나눠라
계약서, 연구 논문, 매뉴얼, 스캔 문서, 회의록, 이미지 캡처는 실패 양상이 다르다. 하나의 OCR 품질 점수로 전체를 판단하면 운영 중에 터진다.
2) 평가 기준을 업무 단위로 만들어라
“전체 정확도 90%”보다 “금액·날짜·조항 번호·표의 행 관계가 보존되는가”가 더 중요하다. 가능하면 문서별 unit test를 만든다.
3) 원본과 변환본을 같이 보관하라
나중에 모델이나 변환기가 바뀌면 재처리가 필요하다. 원본 PDF, 변환 텍스트, 변환 버전, 파라미터, 실패 로그를 함께 남겨야 한다.
4) RAG 튜닝 전에 변환 품질을 샘플링하라
검색 결과가 이상하면 chunking부터 바꾸기 전에 원문 변환 결과를 먼저 확인해야 한다. 상당수 문제는 변환 단계에서 이미 발생한다.
5) 외부 API 사용 가능 여부를 초기에 결정하라
개인정보, 계약 문서, 내부 정책 문서가 들어간다면 외부 OCR API 사용이 어려울 수 있다. 이 경우 오픈소스 모델과 자체 GPU 처리 경로가 단순 비용 문제가 아니라 보안·컴플라이언스 문제가 된다.
결론: 문서 AI의 경쟁력은 “읽는 모델”보다 “검증 가능한 입력”에서 나온다
olmOCR의 가장 흥미로운 점은 OCR을 다시 모델 경쟁으로만 끌고 가지 않는다는 데 있다. 7B VLM, Markdown 변환, reading order, 표·수식 처리, 대량 배치 비용, olmOCR-Bench, unit-test rewards가 한 묶음으로 제시된다. 이 조합이 말하는 방향은 분명하다.
앞으로 문서 AI에서 중요한 질문은 “어떤 모델이 문서를 읽을 수 있는가”에서 “어떤 파이프라인이 문서를 검증 가능한 LLM 입력으로 만들 수 있는가”로 이동한다.
한국 개발자와 운영자에게 실무적 결론은 이렇다. RAG 품질을 올리고 싶다면 검색기와 프롬프트만 보지 말고, 문서가 처음 텍스트가 되는 순간을 먼저 잡아야 한다. PDF가 깨끗한 Markdown과 테스트 가능한 데이터로 바뀌지 않으면, 그 뒤의 LLM은 똑똑하게 틀릴 뿐이다.
참고한 주요 출처
- AllenAI, allenai/olmocr GitHub repository
- AllenAI, olmOCR official demo page
- arXiv, olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models
- arXiv, olmOCR 2: Unit Test Rewards for Document OCR
- AllenAI, olmOCR-Bench README
- Hugging Face, allenai/olmOCR-2-7B-1025-FP8
- Hugging Face, allenai/olmOCR-bench dataset