- Published on
Alibaba Page Agent: 브라우저 밖 자동화보다 페이지 안 GUI 에이전트가 더 중요해지는 이유
- Authors

- Name
- Kyunghyun Park
- @devkhpark
키워드: Page Agent · in-page GUI agent · DOM-first browser automation · MCP
Alibaba의 page-agent가 흥미로운 이유는 “웹페이지를 AI가 클릭해준다” 정도가 아니다. 진짜 신호는 더 구체적이다. AI 에이전트가 브라우저 밖에서 화면을 훔쳐보는 자동화 도구가 아니라, 웹앱 안에 직접 들어와 사용자 인터페이스를 자연어로 조작하는 제품 계층이 되고 있다.

2026년 7월 5일 기준 GitHub Trending에서 alibaba/page-agent는 TypeScript 기반 AI/agent/tooling 흐름으로 다시 강하게 올라왔고, GitHub API 기준 약 2.3만 개의 별과 1,900개 이상의 포크를 기록하고 있다. README가 내세우는 문장도 분명하다. “The GUI Agent Living in Your Webpage. Control web interfaces with natural language.” 즉 페이지 바깥의 범용 브라우저 로봇이 아니라 페이지 안에 사는 GUI 에이전트다.
이 글은 alibaba/page-agent GitHub 저장소, README, 공식 문서의 Overview, Limitations, Models, Data Masking, MCP Server, @page-agent/mcp README, 그리고 GitHub API 메타데이터를 기준으로 썼다.
기준 시점: 이 글은 2026-07-05에 확인한 공개 저장소와 문서 기준이다. Page Agent는 빠르게 바뀌는 프로젝트이므로 실제 도입 전 npm 버전, 문서, 보안 정책을 다시 확인하는 편이 좋다.
핵심 전환: 브라우저 자동화가 아니라 제품 안의 자연어 조작 계층
지금까지 “AI가 웹을 조작한다”는 말은 대개 외부 자동화에 가까웠다. 에이전트가 Playwright나 Puppeteer를 통해 브라우저를 열고, 스크린샷을 보고, 클릭 좌표를 추정하고, DOM을 읽고, 실패하면 다시 시도하는 식이다. 이 접근은 범용성이 크지만 제품 개발자 입장에서는 애매한 지점이 많다.
- 사용자 앱 안에 자연스럽게 들어가기 어렵다.
- 계정, 권한, 감사 로그, 개인정보 처리와 분리되기 쉽다.
- 화면 변화와 DOM 구조가 어긋나면 실패 원인을 추적하기 어렵다.
- “우리 서비스의 공식 UX”라기보다 “외부 로봇이 우리 서비스를 조작한다”에 가깝다.
Page Agent의 방향은 다르다. README는 “browser extension / python / headless browser가 필요 없고, in-page JavaScript만으로 동작한다”고 설명한다. 공식 Overview도 Page Agent를 “웹 개발자와 웹 애플리케이션을 먼저 겨냥한 embedded GUI Agent”라고 소개한다. 이 차이가 중요하다.
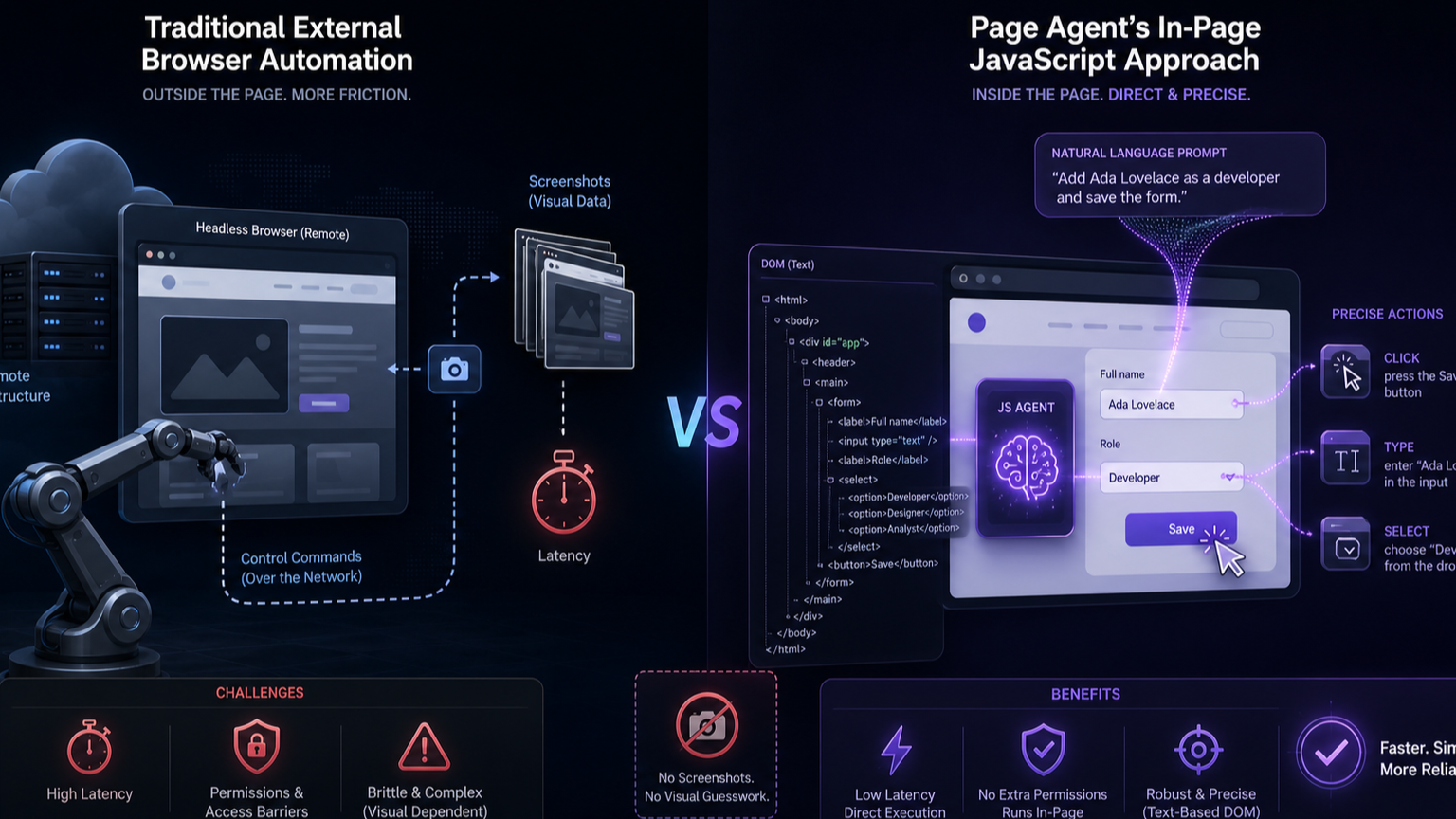
외부 자동화가 “브라우저를 대신 운전하는 로봇”이라면, Page Agent는 “서비스가 스스로 제공하는 자연어 조작 계층”에 가깝다. SaaS, ERP, CRM, 관리자 콘솔처럼 버튼과 폼이 많고 반복 조작이 많은 제품에서는 이 방향이 더 제품답다.
왜 DOM-first인가: 멀티모달보다 운영 가능한 텍스트 인터페이스
Page Agent가 강조하는 또 하나의 포인트는 text-based DOM manipulation이다. README는 “No screenshots. No multi-modal LLMs or special permissions needed.”라고 적는다. 공식 Overview도 DOM-based analysis와 “high-intensity dehydration”, 즉 페이지를 압축된 텍스트 표현으로 단순화하는 접근을 핵심 기능으로 설명한다.
이건 모델 성능 논쟁보다 운영 설계에 가깝다. GUI 에이전트가 매번 스크린샷을 보고 판단하면 시각적으로는 직관적이지만, 서비스 운영팀 입장에서는 다음 문제가 남는다.
- 어떤 정보가 모델에 전달됐는지 추적하기 어렵다.
- 민감한 화면 일부를 지우거나 바꾸는 정책을 붙이기 어렵다.
- 토큰 비용과 지연시간이 커지기 쉽다.
- 버튼·입력창 같은 구조적 의미를 안정적으로 보존하기 어렵다.
반대로 DOM-first 접근은 화면을 “보이는 이미지”가 아니라 “조작 가능한 구조”로 다룬다. 버튼, 입력 필드, 셀렉트, 폼 제출, 스크롤, 포커스 이동 같은 웹 조작 단위가 명확해진다. Page Agent 문서의 Limitations도 이 경계를 솔직하게 드러낸다. 지원 범위는 클릭, 텍스트 입력, 선택, 스크롤, 폼 제출, 포커스, 같은 출처의 단일 iframe, 선택적 JavaScript 실행 등에 가깝다. 즉 “무엇이든 보는 범용 눈”보다 웹앱의 조작 구조를 안정적으로 다루는 쪽에 무게가 있다.
실무에서 더 중요한 기능: 데이터 마스킹과 통제 가능한 에이전트
AI 에이전트를 실제 서비스에 넣을 때 가장 먼저 부딪히는 질문은 “잘 클릭하느냐”가 아니다. 더 현실적인 질문은 이것이다.
- 모델에 어떤 페이지 정보가 넘어가는가?
- 개인정보, 이메일, 전화번호, 결제 정보는 어떻게 가리는가?
- 사용자가 시킨 자연어 명령이 어디까지 실행될 수 있는가?
- 문제가 생겼을 때 멈추거나 감사할 수 있는가?
Page Agent 문서에서 눈여겨볼 부분은 Data Masking이다. transformPageContent 훅을 통해 DOM 추출·단순화 이후 LLM으로 보내기 전 페이지 콘텐츠를 가공할 수 있다고 설명한다. 예시는 전화번호, 이메일, 주민등록번호류 식별자, 카드번호 같은 민감 정보를 마스킹한다.
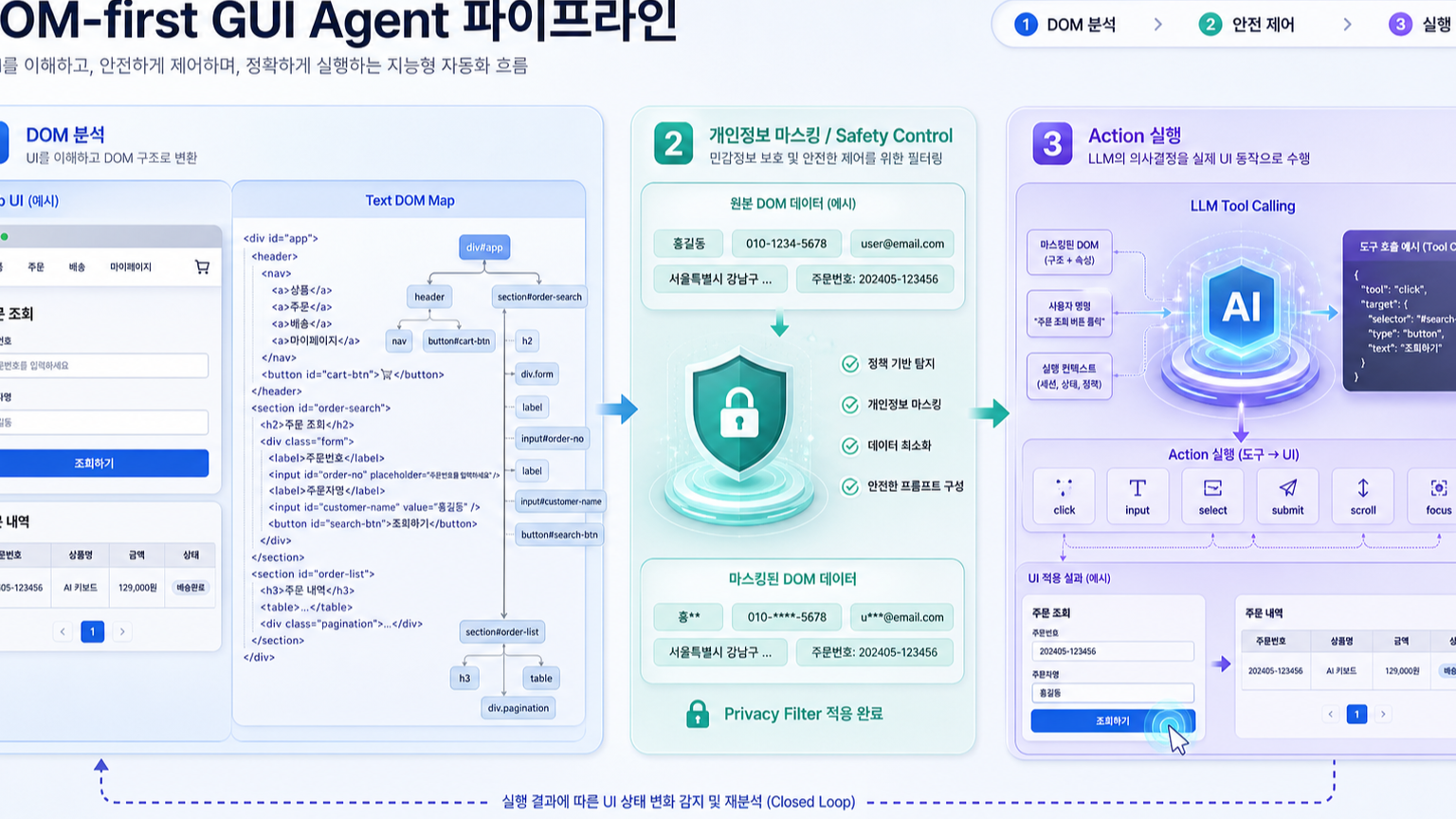
이건 작은 기능처럼 보이지만, 제품 도입 관점에서는 핵심이다. GUI 에이전트는 사용자의 현재 화면을 읽고 행동한다. 그래서 개인정보 보호와 권한 통제를 “나중에 프롬프트로 잘 말하면 되겠지” 수준으로 처리하면 안 된다. 페이지 콘텐츠가 모델에 넘어가기 전에 필터링되는 지점이 있어야 하고, 어떤 필드를 모델이 보지 못하게 할지 서비스 개발자가 통제할 수 있어야 한다.
Page Agent가 완성된 엔터프라이즈 거버넌스 제품이라는 뜻은 아니다. 오히려 지금 봐야 할 포인트는 반대다. 웹앱 안 GUI 에이전트가 제품 기능이 되려면 DOM 추출, 데이터 마스킹, 허용 동작, 실행 로그가 하나의 운영면으로 묶여야 한다. Page Agent는 이 방향을 꽤 노골적으로 보여준다.
모델 선택도 달라진다: 큰 비전 모델보다 빠른 ToolCall 모델
Page Agent의 Models 문서는 OpenAI 호환 API와 tool call을 지원하는 모델을 대상으로 한다고 설명한다. 문서에는 Qwen, OpenAI, DeepSeek, Google, Anthropic, MiniMax, xAI, MoonshotAI, Z.AI 계열 모델명이 예시로 나열되어 있고, 팁으로 “빠르고 가벼우며 ToolCall 능력이 강한 모델”을 권장한다.
이 부분은 한국 개발자들이 특히 주목할 만하다. GUI 에이전트라고 해서 항상 가장 비싼 멀티모달 모델을 붙여야 하는 것은 아니다. Page Agent식 접근에서는 화면을 이미지로 보는 대신 페이지 구조를 텍스트로 정리하고, 모델은 그 구조 위에서 다음 행동을 선택한다. 그러면 병목은 이미지 이해보다 도구 호출 정확도, 짧은 지연시간, 실패 복구, 비용 안정성으로 옮겨간다.
실무적으로는 아래처럼 생각하는 편이 맞다.
| 선택 기준 | 외부 스크린샷 기반 GUI 에이전트 | Page Agent식 in-page DOM 에이전트 |
|---|---|---|
| 입력 | 스크린샷, 접근성 트리, 브라우저 상태 | 단순화된 DOM 텍스트, 페이지 컨텍스트 |
| 모델 요구 | 강한 비전·추론 모델 | 빠른 ToolCall·텍스트 추론 모델 |
| 장점 | 범용 웹 조작 | 제품 안 통합, 낮은 권한 요구, 데이터 마스킹 |
| 약점 | 비용·지연·권한·관측성 | DOM 경계 밖 시각 작업에는 약함 |
| 좋은 사용처 | 외부 웹 리서치, 테스트, 크롤링 | SaaS copilot, 관리자 콘솔, 폼 자동화, 접근성 |
즉 Page Agent의 가치는 “브라우저 자동화를 대체한다”가 아니라, 제품 내부 조작에 맞는 더 좁고 운영 가능한 에이전트 설계를 제안한다는 데 있다.
MCP 서버와 확장: 페이지 안 에이전트가 외부 에이전트와 만나는 지점
Page Agent는 기본적으로 in-page JavaScript를 강조하지만, README는 선택적 Chrome extension과 MCP Server(Beta)도 함께 소개한다. @page-agent/mcp README를 보면 구조가 더 선명하다. 로컬 에이전트 클라이언트가 stdio로 MCP 서버를 시작하고, 서버는 localhost에서 HTTP/WebSocket을 열며, 브라우저 확장의 Hub tab이 연결되어 작업을 전달받는다. 도구는 단순하다.
execute_task: 자연어 브라우저 작업 실행get_status: 연결·작업 상태 확인stop_task: 현재 작업 중지
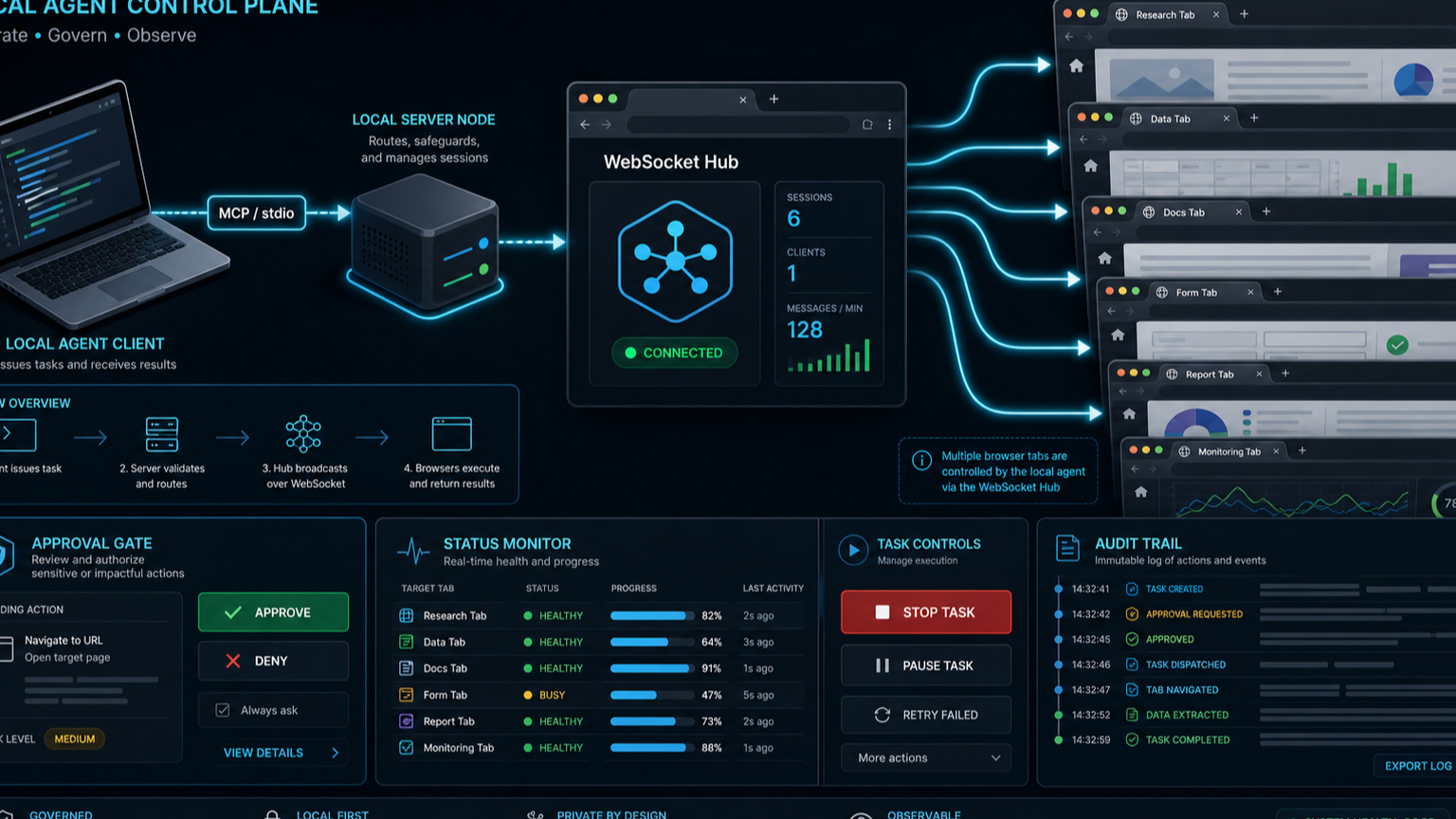
여기서 재미있는 점은 Page Agent가 두 방향을 동시에 잡고 있다는 것이다.
- 제품 안으로 들어가는 방향 — 웹 개발자가 스크립트나 npm 패키지로 페이지에 자연어 조작 계층을 붙인다.
- 에이전트 생태계와 연결되는 방향 — MCP 서버와 브라우저 확장을 통해 Claude, Copilot, Cursor 같은 외부 에이전트 클라이언트가 브라우저 작업을 맡길 수 있다.
이 조합은 앞으로 자주 보게 될 가능성이 높다. 웹앱은 자체 copilot을 제공하고, 동시에 외부 에이전트 클라이언트가 안전하게 붙을 수 있는 표준 제어면을 갖추는 식이다. 중요한 건 “AI 버튼 하나 추가”가 아니라, 앱의 UI가 에이전트가 사용할 수 있는 계약면이 되는 것이다.
어디에 바로 쓸 만한가: 복잡한 B2B 화면, 폼, 운영 콘솔
Page Agent README의 Use Cases는 꽤 실무적이다. SaaS AI Copilot, Smart Form Filling, Accessibility, Multi-page Agent, MCP가 언급된다. 이 중에서 가장 먼저 현실성이 높은 건 B2B·운영 화면이다.
예를 들어 이런 장면을 생각해볼 수 있다.
- “지난달 미결제 고객만 필터링하고 CSV로 내보내줘.”
- “이 고객의 플랜을 Pro로 바꾸고 메모에 사유를 남겨줘.”
- “오늘 등록된 문의 중 SLA가 2시간 미만으로 남은 건만 보여줘.”
- “이 설정 페이지에서 알림 채널을 Slack으로 바꾸고 테스트 메시지를 보내줘.”
이런 작업은 LLM이 창의적인 답을 해야 하는 문제가 아니다. 복잡한 UI를 사용자의 의도에 맞춰 정확히 조작하는 문제다. 그래서 Page Agent식 접근이 맞는 곳은 “무한한 웹 탐색”보다 정해진 제품 화면 위에서 반복 작업을 줄이는 영역이다.
특히 한국의 B2B SaaS, 내부 관리자 도구, 커머스 운영 콘솔, 병원·교육·물류·제조 ERP처럼 화면은 많고 사용자는 바쁜 제품에서는 자연어 조작 계층이 꽤 큰 생산성 기능이 될 수 있다. 다만 이때도 에이전트가 마음대로 실행하게 두면 안 된다. 결제, 삭제, 권한 변경, 대량 발송 같은 고위험 동작에는 확인 단계와 정책 제한이 필요하다.
한계도 명확하다: DOM 바깥의 세상까지 해결해주지는 않는다
Page Agent 문서가 좋은 점은 한계를 숨기지 않는다는 데 있다. Limitations 문서는 PageAgent.js와 PageAgentExt의 범위를 나누고, PageAgent.js는 현재 페이지·SPA 중심이며 PageAgentExt는 다중 탭 같은 브라우저 수준 제어를 더한다고 설명한다. 또 DOM 기반 이해가 능력 경계를 정한다.
이 말은 곧 다음과 같다.
- 캔버스, 복잡한 그래픽 편집기, 비정형 시각 작업에는 한계가 있다.
- 페이지가 의미 있는 DOM 구조를 제공하지 않으면 정확도가 떨어질 수 있다.
- 외부 웹 전체를 돌아다니는 범용 리서치 에이전트와는 목적이 다르다.
- 고위험 액션에는 제품 차원의 승인·권한·감사 설계가 별도로 필요하다.
그래서 Page Agent를 “모든 브라우저 자동화의 미래”로 과장할 필요는 없다. 더 정확한 해석은 이렇다. 브라우저 자동화가 하나의 범용 로봇으로 수렴하는 것이 아니라, 제품 내부용·테스트용·외부 웹 리서치용·MCP 제어용으로 분화되고 있다. Page Agent는 그중 제품 내부용 GUI 에이전트의 좋은 사례다.
실무 해석: 지금 도입한다면 어떻게 봐야 하나
한국 개발팀이나 제품 운영팀이 Page Agent류 도구를 검토한다면, “데모가 잘 되나”보다 아래 질문을 먼저 던지는 게 좋다.
우리 제품의 반복 조작은 무엇인가?
자연어로 줄였을 때 가치가 큰 작업부터 찾아야 한다. 모든 화면에 copilot을 붙이는 것보다 청구, 고객관리, 리포트, 설정, 승인 같은 반복 화면이 우선이다.DOM이 에이전트 친화적인가?
버튼 이름, aria label, 폼 구조, 상태 텍스트가 엉망이면 DOM-first 에이전트도 흔들린다. AI 도입 전에 UI 구조를 정리하는 일이 먼저일 수 있다.어떤 데이터가 모델에 넘어가도 되는가?
Data Masking 훅처럼 사전 필터링 지점이 있어야 한다. 특히 고객정보, 결제정보, 내부 메모, 권한 데이터는 기본 비공개로 보는 편이 안전하다.고위험 액션은 어떻게 막을 것인가?
자연어 명령이 삭제, 송금, 대량 발송, 권한 변경으로 이어질 수 있다면 반드시 확인 단계와 허용 목록이 필요하다.외부 에이전트 연결은 어떤 경로로 열 것인가?
MCP는 매력적이지만, 외부 에이전트가 브라우저 작업을 실행한다는 뜻이다.get_status,stop_task, Hub 연결, 로컬 포트, 감사 로그까지 운영 관점에서 봐야 한다.
결론: Page Agent는 “웹앱이 에이전트를 품는 방식”을 보여준다
Page Agent를 단순한 Alibaba의 브라우저 자동화 라이브러리로 보면 작게 보인다. 하지만 README, 문서, MCP 패키지 구조를 같이 보면 방향은 선명하다. 에이전트는 더 이상 외부에서 페이지를 어설프게 조작하는 로봇만이 아니다. 웹앱 자체가 자연어 조작 계층을 제공하고, DOM을 에이전트용 계약면으로 정리하고, 필요한 경우 MCP를 통해 외부 에이전트와 연결되는 방향으로 가고 있다.
한 줄로 정리하면 이렇다. Page Agent의 핵심은 “AI가 웹을 클릭한다”가 아니라, 웹 제품이 스스로 AI 조작 가능성을 설계하기 시작했다는 신호다. 이 흐름을 먼저 이해하는 팀은 단순 챗봇이 아니라 실제 업무 흐름을 줄이는 제품형 에이전트를 더 빨리 만들 수 있다.
참고한 주요 출처
- Alibaba, alibaba/page-agent GitHub repository
- Alibaba, Page Agent README
- Alibaba, Page Agent 공식 문서: Overview
- Alibaba, Page Agent 공식 문서: Limitations
- Alibaba, Page Agent 공식 문서: Models
- Alibaba, Page Agent 공식 문서: Data Masking
- Alibaba, Page Agent 공식 문서: MCP Server
- Alibaba,
@page-agent/mcpREADME - GitHub API,
alibaba/page-agentrepository metadata, 2026-07-05 확인