- Published on
AI 에이전트의 다음 병목은 모델이 아니라 평가 비용이다
- Authors

- Name
- Kyunghyun Park
- @devkhpark
AI Agent · Evaluation Cost · MCP Proxy · Agent Runtime
AI 에이전트 이야기는 한동안 “어떤 모델이 더 똑똑한가”에 집중됐다. 그런데 2026년 4월 말의 신호를 묶어 보면 질문이 바뀌고 있다. 이제 실무자가 먼저 봐야 할 것은 모델 점수보다 그 에이전트를 얼마나 싸고, 반복 가능하고, 안전하게 평가·통제·배포할 수 있는가다.

이 글은 Hugging Face의 AI evals are becoming the new compute bottleneck, AWS의 Run custom MCP proxies serverless on Amazon Bedrock AgentCore Runtime, OpenAI의 Cybersecurity in the Intelligence Age, 그리고 Hugging Face의 DeepInfra on Hugging Face Inference Providers를 바탕으로 썼다. 핵심 주장은 단순하다. 에이전트의 병목은 추론 호출 하나가 아니라 평가 비용, 보안 경계, 도구 프록시, 데이터 준비도까지 포함한 운영 계층으로 이동하고 있다.
기준 시점: 2026-04-30에 확인한 공식/준공식 자료 기준이다. 각 서비스의 가격, API, 모델 제공 방식은 바뀔 수 있으니 실제 도입 전 원문을 다시 확인해야 한다.
왜 지금 이 주제가 중요한가
LLM 제품을 만들 때 예전에는 비교가 비교적 단순했다. 모델 A가 더 정확한지, 모델 B가 더 빠른지, 모델 C가 더 싼지를 보면 됐다. 물론 그것도 쉬운 일은 아니지만, 적어도 평가 단위는 대개 “프롬프트를 넣고 답을 본다”에 가까웠다.
에이전트는 다르다. 에이전트는 답만 생성하지 않는다.
- 문서를 읽고 요약한다.
- 코드를 쓰고 실행한다.
- 웹이나 사내 API를 호출한다.
- 실패하면 재시도한다.
- 중간 결과를 바탕으로 다음 행동을 고른다.
- 때로는 사람에게 확인을 요청하거나, 시스템 권한 경계를 넘나든다.
이렇게 되면 “정답률” 하나로는 부족하다. 같은 태스크도 한 번은 성공하고, 한 번은 엉뚱한 도구를 호출하고, 한 번은 비용을 과도하게 쓰고, 한 번은 보안 정책을 건드릴 수 있다. 그래서 에이전트 시대의 평가는 단순 benchmark가 아니라 운영 리허설에 가까워진다.
Hugging Face 글이 중요한 이유가 여기에 있다. 이 글은 평가가 연구자의 부록 작업이 아니라, 자체 compute budget과 failure mode를 가진 별도 인프라 문제가 됐다고 지적한다. 특히 agent benchmark는 정적 벤치마크보다 훨씬 지저분하다. rollout이 길고, tool use가 들어가고, grading 자체도 비싸며, 신뢰도 있는 숫자를 얻으려면 반복 실행이 필요하다.
“평가 비용”은 이제 accountability의 병목이다

Hugging Face가 인용한 비용 구조를 보면, 문제는 생각보다 현실적이다. 글은 agent evaluation의 비용이 benchmark 종류에 따라 크게 달라지고, 어떤 경우에는 한 번의 평가가 수천 달러 단위까지 올라갈 수 있다고 설명한다. PaperBench류의 연구 재현 에이전트 평가에서는 rollout 비용과 grading 비용이 따로 붙고, 더 신뢰할 만한 측정을 하려면 단일 실행이 아니라 반복 실행이 필요하다.
여기서 중요한 것은 “평가가 비싸다”는 불평이 아니다. 더 근본적인 문제는 누가 평가할 수 있는가다.
평가 비용이 높아지면 다음과 같은 일이 생긴다.
- 작은 팀은 충분히 반복 평가하지 못한다.
- 한두 번 성공한 데모를 보고 제품화할 위험이 커진다.
- regression을 잡기 어렵고, 모델 교체 때마다 다시 검증하기 어렵다.
- 리더보드가 비용 지출 능력에 영향을 받는다.
- 많은 샘플과 반복 실행을 감당하는 쪽이 더 안정적인 숫자를 낸다.
- 비용을 공개하지 않는 benchmark는 재현 가능성이 약해진다.
- 운영 품질과 연구 품질의 간극이 커진다.
- paper나 demo에서는 잘 보이지만, 실제 업무 루프에서는 variance가 문제 된다.
- 사용자 입장에서는 평균 성능보다 실패 시나리오가 더 중요하다.
즉 평가 비용은 단순한 예산 항목이 아니라 accountability barrier다. 강력한 에이전트를 만들었다고 말하려면, 이제 “얼마나 잘했는가”뿐 아니라 “그 숫자를 얻는 데 어떤 비용과 반복 횟수와 grading 방법을 썼는가”까지 설명해야 한다.
정적 벤치마크와 에이전트 평가는 다른 게임이다
정적 LLM benchmark는 대체로 입력과 기대 출력이 고정돼 있다. 비용 최적화 여지도 있다. 샘플 수를 줄이거나, 작은 judge를 쓰거나, adaptive testing을 적용하는 식의 절감 전략이 가능하다.
반면 에이전트 평가는 실행 경로 자체가 결과의 일부다. 같은 최종 답을 내더라도 어떤 도구를 호출했는지, 몇 번 실패했는지, 권한이 맞았는지, 불필요한 비용을 썼는지, 민감 데이터를 노출했는지까지 봐야 한다. 그래서 에이전트 평가는 아래 네 층을 동시에 본다.
| 평가 층위 | 봐야 할 것 | 실무 리스크 |
|---|---|---|
| 결과 품질 | 최종 답, 산출물, task completion | 사용자가 느끼는 유용성 |
| 실행 경로 | tool call, retry, planning, latency | 비용 폭증, 불안정한 UX |
| 정책 준수 | 권한, PII, 보안 경계, audit log | 사고·규제·내부 통제 실패 |
| 반복 신뢰도 | 여러 run의 variance, regression | 데모와 운영의 괴리 |
이 표에서 핵심은 네 번째다. 에이전트는 한 번 잘하는 것보다 계속 비슷하게 잘하는 것이 어렵다. 그리고 그 반복 신뢰도를 확인하는 순간 비용은 다시 올라간다.
그래서 MCP proxy는 단순 연결 편의가 아니라 governance 경계가 된다
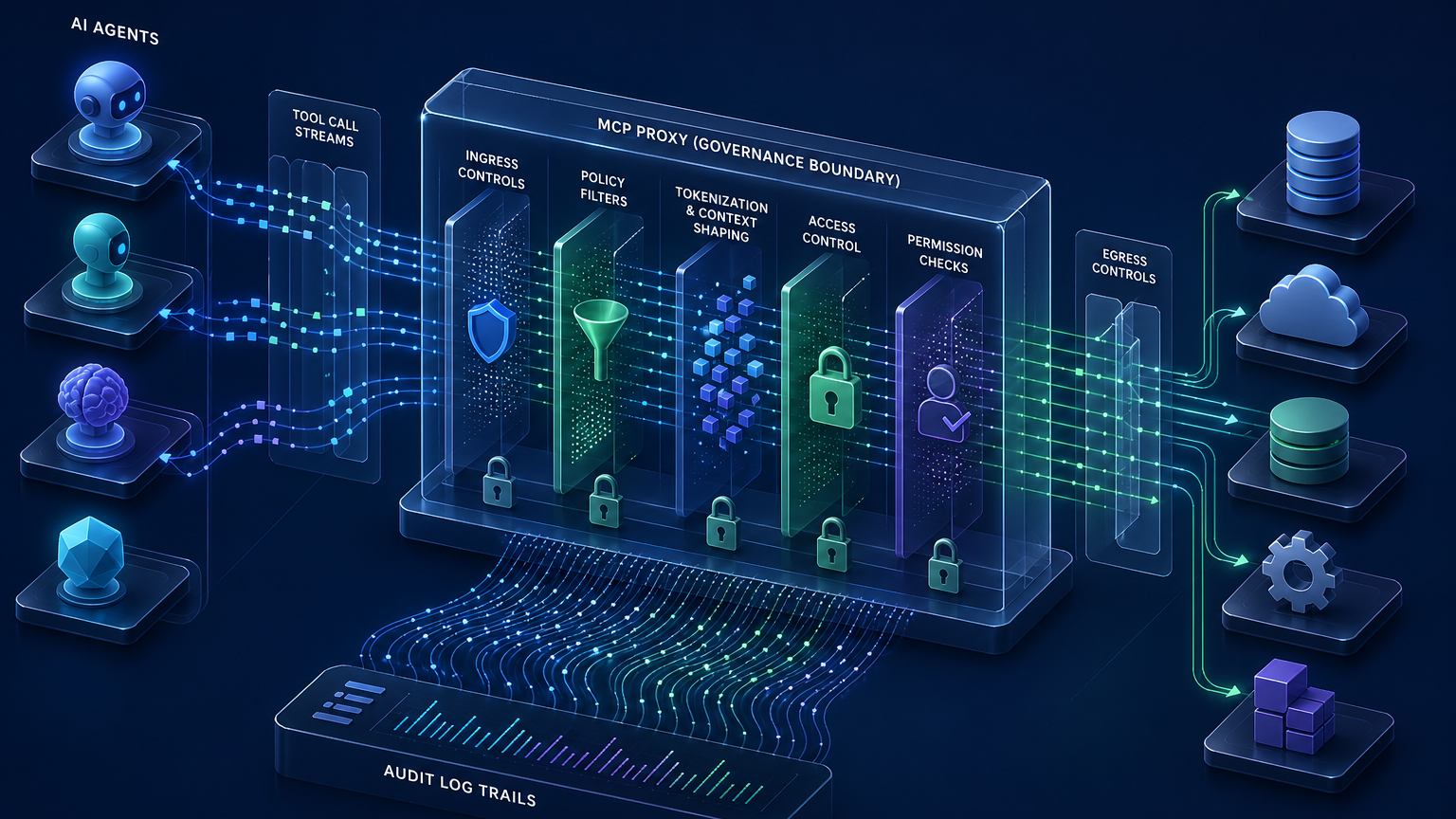
AWS의 Bedrock AgentCore Runtime 위 MCP proxy 글은 이 흐름의 다른 면을 보여준다. MCP는 모델이나 에이전트가 외부 도구와 연결되는 표준 인터페이스로 빠르게 자리 잡고 있다. 그런데 도구 연결이 쉬워질수록 질문은 더 어려워진다.
- 에이전트가 어떤 도구를 볼 수 있어야 하는가?
- 도구 호출 인자에 민감 정보가 섞여 있으면 어떻게 처리할 것인가?
- upstream MCP server와 agent 사이의 인증은 누가 책임지는가?
- tool call을 중간에서 기록, 변환, 차단해야 할 때 어디에 넣을 것인가?
AWS 글의 proxy 구조가 흥미로운 이유는 여기에 있다. proxy는 tool을 직접 정의하지 않고 upstream MCP server에서 tool을 discovery한 뒤, client 요청을 runtime에 forward한다. 동시에 중간에서 authorization, tokenization, tool-level access control 같은 개입 지점을 만들 수 있다.
이건 제품 설계상 꽤 큰 의미가 있다. MCP가 “에이전트가 툴을 쓰게 해주는 편리한 연결 포맷”에서 끝나지 않고, 에이전트 거버넌스의 현실적인 chokepoint가 될 수 있기 때문이다.
실무적으로는 다음과 같은 설계가 가능해진다.
- agent는 proxy만 호출한다.
- proxy는 upstream tool server와 인증 관계를 가진다.
- proxy는 PII를 tokenization하거나 일부 필드를 masking한다.
- proxy는 tool별 접근 정책을 적용한다.
- proxy는 모든 tool call을 audit log로 남긴다.
- 평가 시스템은 최종 답뿐 아니라 proxy log를 함께 본다.
이 구조가 평가 비용 이야기와 연결된다. 에이전트를 제대로 평가하려면 결과만 보면 안 된다. tool call 경로와 정책 위반 가능성까지 봐야 한다. 그러려면 중간 경계가 필요하고, MCP proxy 같은 계층은 그 경계를 넣기 좋은 위치다.
OpenAI의 사이버 보안 계획은 “AI 배포 = 보안 운영”이라는 신호다
OpenAI의 “Cybersecurity in the Intelligence Age”는 AI가 방어자에게 취약점 식별, remediation 자동화, 빠른 대응을 가능하게 하지만, 동시에 악의적 행위자도 공격을 확장하고 진입 장벽을 낮추는 데 같은 능력을 쓴다고 말한다. 그리고 frontier cyber capabilities 주변의 보안 강화, deployment에서 visibility와 control을 유지하는 문제를 명시한다.
이 문서의 실무적 의미는 “AI가 보안에 중요하다”가 아니다. 더 정확히는 AI 에이전트 배포 자체가 보안 운영의 일부가 된다는 뜻이다.
에이전트가 사내 코드베이스, 고객 데이터, 운영 콘솔, 결제 시스템, 클라우드 리소스에 연결되는 순간, 보안팀과 플랫폼팀은 다음 질문을 해야 한다.
- 이 agent가 어떤 권한으로 어떤 도구를 호출하는가?
- 실패하거나 prompt injection을 당했을 때 어디까지 피해가 퍼지는가?
- 로그와 재현 경로가 남는가?
- eval set에 보안·정책 위반 시나리오가 포함돼 있는가?
- 모델 교체나 tool 추가 때 같은 테스트를 다시 돌릴 수 있는가?
이 질문들은 보안 문서에도 있고, 평가 문서에도 있고, MCP proxy 문서에도 있다. 이름만 다를 뿐 같은 문제다. 운영 가능한 에이전트는 모델, 평가, 보안, 도구 경계를 분리해서 생각할 수 없다.
Inference Provider 경쟁은 비용 문제를 더 투명하게 만든다
Hugging Face가 DeepInfra를 Inference Providers에 추가한 것도 같은 흐름 안에서 볼 수 있다. Hugging Face의 설명에 따르면 사용자는 provider를 선호도 순으로 정하고, 직접 provider key를 쓰거나 HF를 통해 routed 방식으로 호출할 수 있다. routed 방식에서는 provider의 표준 API rate를 그대로 지불하며, 별도 markup은 없다고 설명한다.
이 변화는 “모델을 어디서 싸게 돌릴까”의 문제처럼 보이지만, 평가 병목과도 연결된다. 에이전트 평가가 비싸질수록 inference provider 선택은 단순 배포 옵션이 아니라 evaluation budget 설계의 일부가 된다.
예를 들어 같은 agent를 운영하려면 다음 비용을 함께 봐야 한다.
- 실제 사용자 요청 serving 비용
- offline regression eval 비용
- 모델 교체 전 A/B evaluation 비용
- tool call과 external API 비용
- judge model 또는 human grading 비용
- 실패 재현과 log 저장 비용
이 중 하나만 싸다고 전체가 싸지는 않는다. 오히려 provider 선택이 쉬워질수록 팀은 더 자주 평가하고, 더 많은 후보 모델을 비교하며, 더 많은 regression matrix를 만들게 된다. 결국 비용 병목은 serving 단가만이 아니라 얼마나 자주, 얼마나 넓게, 얼마나 신뢰할 수 있게 평가할 것인가로 이동한다.
한국 개발팀이 당장 바꿔야 할 질문

한국어권 개발팀이나 기술 운영팀 입장에서 이 흐름의 실전 포인트는 명확하다. “어떤 모델이 제일 좋나?”로 시작하면 너무 늦다. 먼저 다음 질문을 해야 한다.
1) 우리는 에이전트의 실패를 어떻게 측정할 것인가
단순 accuracy가 아니라 task completion, latency, tool-call count, retry 횟수, 비용, 정책 위반, 사용자 개입 여부를 같이 봐야 한다. 특히 사내 업무 에이전트라면 “정답”보다 “권한을 넘지 않고 재현 가능한 경로로 처리했는가”가 더 중요할 수 있다.
2) evaluation budget을 제품 예산에 넣었는가
에이전트 평가는 런칭 전 한 번 하는 QA가 아니다. 모델이 바뀌고, tool이 추가되고, prompt가 수정되고, 사내 데이터가 갱신될 때마다 다시 돌아가야 한다. 그러려면 평가 비용을 연구비가 아니라 운영비로 잡아야 한다.
3) tool boundary를 어디에 둘 것인가
MCP를 쓴다면 “연결됐다”에서 끝내면 안 된다. proxy, gateway, policy layer, audit log를 어디에 둘지 정해야 한다. 민감 데이터를 그대로 tool backend에 보낼지, tokenization할지, tool별 allowlist를 둘지, emergency revoke를 어떻게 할지 정해야 한다.
4) 보안 시나리오를 eval set에 넣었는가
prompt injection, 과도한 권한 요청, PII 노출, 잘못된 tool selection, 악성 문서 입력, 외부 URL 처리 같은 시나리오는 보안팀 문서에만 있으면 안 된다. agent regression suite에 들어가야 한다.
5) 데이터 준비도와 sync를 평가하고 있는가
좋은 모델을 붙여도 사내 문서가 오래됐거나, permission metadata가 틀리거나, knowledge base sync가 느리면 agent는 실패한다. agent 성능의 상당 부분은 모델이 아니라 데이터 준비도에서 결정된다.
SEO 키워드보다 중요한 실무 키워드: eval ops
이 주제를 검색 관점에서 보면 “AI agent evaluation”, “LLM eval cost”, “MCP proxy”, “agent runtime security” 같은 키워드가 따로 움직이는 것처럼 보인다. 하지만 실무에서는 하나의 묶음이다. 나는 이 묶음을 eval ops라고 부르는 편이 좋다고 본다.
Eval ops는 단순히 benchmark를 돌리는 일이 아니다. 다음을 포함한다.
- 평가 데이터셋과 시나리오 관리
- rollout 비용 추적
- judge model / human review 정책
- tool-call log 수집
- security and policy test cases
- 모델·프롬프트·도구 변경 시 regression 자동화
- provider별 cost/performance 비교
- 결과 재현성과 보고 체계
DevOps가 배포를 자동화했고, MLOps가 모델 학습·서빙을 운영화했다면, agent 시대에는 eval ops가 별도 레이어로 올라올 가능성이 크다. 특히 에이전트가 실제 업무 권한을 갖는 순간, eval ops는 품질팀의 선택 사항이 아니라 플랫폼팀의 기본 인프라가 된다.
한 줄 결론
AI 에이전트 경쟁은 “더 똑똑한 모델”만으로 설명되지 않는다. 2026년 4월 말의 신호는 훨씬 실무적이다. 평가 비용이 새 compute bottleneck이 되고, MCP proxy가 governance 경계가 되며, 사이버 보안이 agent runtime의 기본 요구사항으로 들어오고 있다.
따라서 지금 에이전트를 도입하는 팀이 먼저 만들어야 할 것은 멋진 데모가 아니라, 반복 가능한 평가 예산표, tool boundary, audit log, 보안 시나리오, 데이터 준비도 체크리스트다. 모델은 계속 바뀐다. 하지만 이 운영 계층을 먼저 잡은 팀이 다음 모델을 더 빨리, 더 안전하게, 더 싸게 흡수할 가능성이 높다.
참고한 자료
- Hugging Face / EvalEval Coalition, AI evals are becoming the new compute bottleneck, 2026-04-29.
- AWS Machine Learning Blog, Run custom MCP proxies serverless on Amazon Bedrock AgentCore Runtime, 2026-04-29.
- OpenAI, Cybersecurity in the Intelligence Age, 2026-04-29.
- Hugging Face, DeepInfra on Hugging Face Inference Providers, 2026-04-29.